这次呢,想着借机写一款主题,形式依然是我喜欢单栏。由于很久不写代码,看到代码很生疏了,外加当前前端技术迭代太快了,好多HTML、css3的新特性和js的ES5、ES6,我处于完全看不懂的状态,这个主题的由来是我平时浏览网站的时候,看到别人好看的风格样式,就扒拉扒拉下来了,有的懒得动脑子,就直接参考和借鉴过来。整个主题是使用字节推出的 Trae CN 编辑器,本地电脑搭建环境,外加用上Trae 的 Ai 来写代码,效率是离谱的高,在这个主题绝大部分代码是使用 Ai 的写的。开发效率是有点高,尤其是在解决一些很复杂的逻辑时,你只需告诉 Ai 程序的基本逻辑,它便生成可用的代码,在前端库的选择, 当然我选择的是 jQuery,其实前端JS可以用原生来实现,但是用着jQuery很顺手,代码简单,一行代码就能搞定的,没必要绕弯。别人都在用高级的Hexo、Hugo 等高级,而我依然选择的是 wordpress,可能懒得折腾、懒得写作时用Markdown,也可能是保持了习惯和旧状态,新特性对我没有吸引力吧。
在使用过VCS配合Verdi进行波形仿真之后,再也无法忍受vivado那缓慢的仿真与卡顿的界面,Verdi追踪信号更是极快加速问题定位。不过FPGA的IP不能像普通Verilog IP一样直接使用VCS进行编译仿真,需要调用一些Vivado IP Library才可以,下面分享一下如何使用VCS进行FPGA工程波形前仿真。
今年618把大部分的家具和家电配齐之后,一直没看到合适的电视,刚开始看好的的小米的ES Pro 75寸,在雷鸟和小米之间犹豫,后来因为其他家具还没备齐,618上价格也没啥竞争力,外加电视并不是刚需,于是拖着一直没买,进了客厅,只见一面大白墙。
今年双11,我正在瞎逛的时候,京东和天猫都开始推小米电视 S Pro 75 Mini LED ,什么MiniLED、75寸、2200nits 的亮度、144Hz高刷、ΔE≈1 、4GB+64GB,就这配置居然5999,果断下单。使用了几天,感觉真心 不错,得益于MiniLED面板,效果和OLED有一拼,黑的地方完全黑,亮的地方很亮。播放我NAS里的4K 120帧的双子杀手,真心丝般顺滑。
[4] Bellroy Lite Sling
这款包的体积和容积稍小,同时包很轻薄。这个的前袋设计也是整齐的,取拿东西应该也比较方便。因为包的设计是轻薄类型,内衬的质感就差了些,不过分隔看起来还是比较科学的。这款的设计也算是比较喜欢,这款国内仿版拼多多50RMB左右,正版则是要700+RMB,实在消费不起。
Recently, I have been to Beijing for 4 days. It was my first time to get there. Before the trip, I was so excited that I had a great preparation. The night before the first day, I didn’t sleep well because I thought about how to have fun there all night!
After four hours’ ride on the train, we arrived at Beijing. It is such a big city but there are few high buildings. Why is that? That is because there are some quadrangle dwellings which are not very high. They are very important to this city. They are a symbol of the Old Beijing.
After a great lunch, we went to the Great Wall. It is such a long wall that we can’t see the edge of it! After having a search on the Internet, we found it is over 20 thousand kilometers long! That is fantastic! We took a deep breath and started to go. Although I didn’t sleep well last night, I didn’t feel tired at all. We ate nothing but climb from afternoon to evening. We got such a strong feeling of joy and satisfaction when we found we had 20 thousand meters’ walk! We walked one thousandth of the length of the Great Wall!
On the second day, we went to the National Museum. There are so many people there! After we get into the museum, we went to see the Ancient China. There are many valuable cultural relics there such as Houmuwu ding, Four-goat Square Zun, etc. Before I could only see them on the history books, but this time I was able to watch the real things in front of my eyes! I took a lot of photos to review the relics.
That night, we tried something different — Copper Pot Instant Pork. That was so delicious that we ate four plates of meat. We got very full at last but still want to eat more!
Next day, we went to the Tiananmen Square in the morning. It is a large and beautiful square. We could clearly see the big photo of Chairman Mao on the wall. We all kept serious and thought a lot. Without Mao and other leaders, we wouldn’t live a happy life at all!
In the afternoon, we got to Sanlian Bookstore and read there for several hours. We found many good books there and bought a few of them. Maybe it is the best bookstore I’ve ever been!
The last day, we had a look at Qianmen Street. We bought some snacks there and saw something interesting. After there hours’ walk, we felt bored and went back to the hotel. Then we had a lunch and went back to Bengbu in the afternoon.
It was a nice cultural journey to Beijing. We reached many places of interest, enjoyed the dietary culture and also had a good time at the bookstore. This way, I have a deeper understanding of the Chinese culture. As a middle school student in the new era, I will study widely and try my best to help realize the China Dream.
举几个例子。不知道大家有没有用过那款 iPod,那个带有 Click Wheel 的经典款?巧了我也没用过,但这次 Apple TV 附带的遥控器让我们有机会体验到那种有趣高效的交互。简单来说,这次的遥控器既有实体的按键,但也是可触控的,你可以在遥控器上面滑动,TV 上相应的焦点也会改变,十分顺滑。苹果甚至在配备了触摸遥控器的机型上修改了键盘布局,由 QWERTY 键盘变成了直接的 26 个字母罗列,想必是对新遥控器的输入速度很有信心。
流畅的体验不止于此,苹果通过自己的软硬件生态做到了只有它能做到的流畅:Apple TV 是可以用 iPhone 做遥控器的。当与 iPhone 配对之后控制中心会出现一个新按钮,点开就可以完全使用 iPhone 来遥控电视,当然也支持滑动手势,不需要下载什么 App,整合程度很深。另外 TV 上需要输入文字的地方,比如输密码,搜索内容,都可以使用 iPhone 输入。说起来这么自然的方案,第一次用上还是会觉得,啊,舒坦。另外和 HomeKit 的联动,支持 Siri 等等我就不说了。
App 方面可能见仁见智。因为 Apple TV 没有进入国区,所以是不能用国区的 Apple ID 下载 App 的,爱奇艺、优酷、腾讯等等也只能下载美区商店里的海外版,内容和国内不同。这对许多用户来说是硬伤,但具体到我就觉得还好,一者是我很少看这几个平台的视频,二者还能保底用 AirPlay 投屏。我更关心的如何播放我自己的收藏品,以及看 B 站,这两个需求在 Apple TV 上刚好能很好地解决。
前者我的选择是 Infuse,一个横跨苹果所有平台的播放器。它首先实力超群,对各种格式、编码都有很好的支持,基本上解决了所有播放需求;其次颜值非常非常高。TV 端不好截屏,给你们看看 Mac 端的效果,TV 端基本类似。
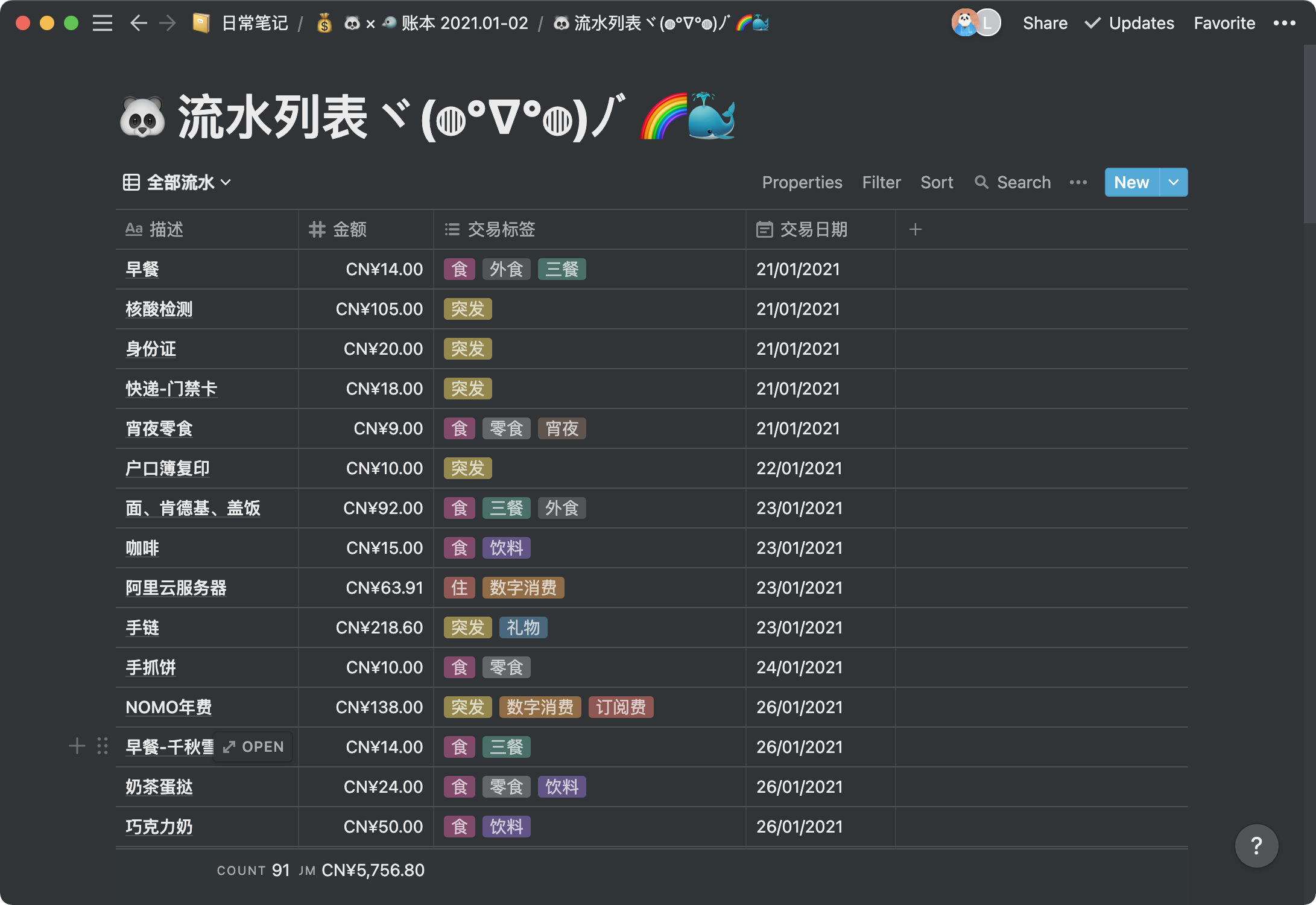
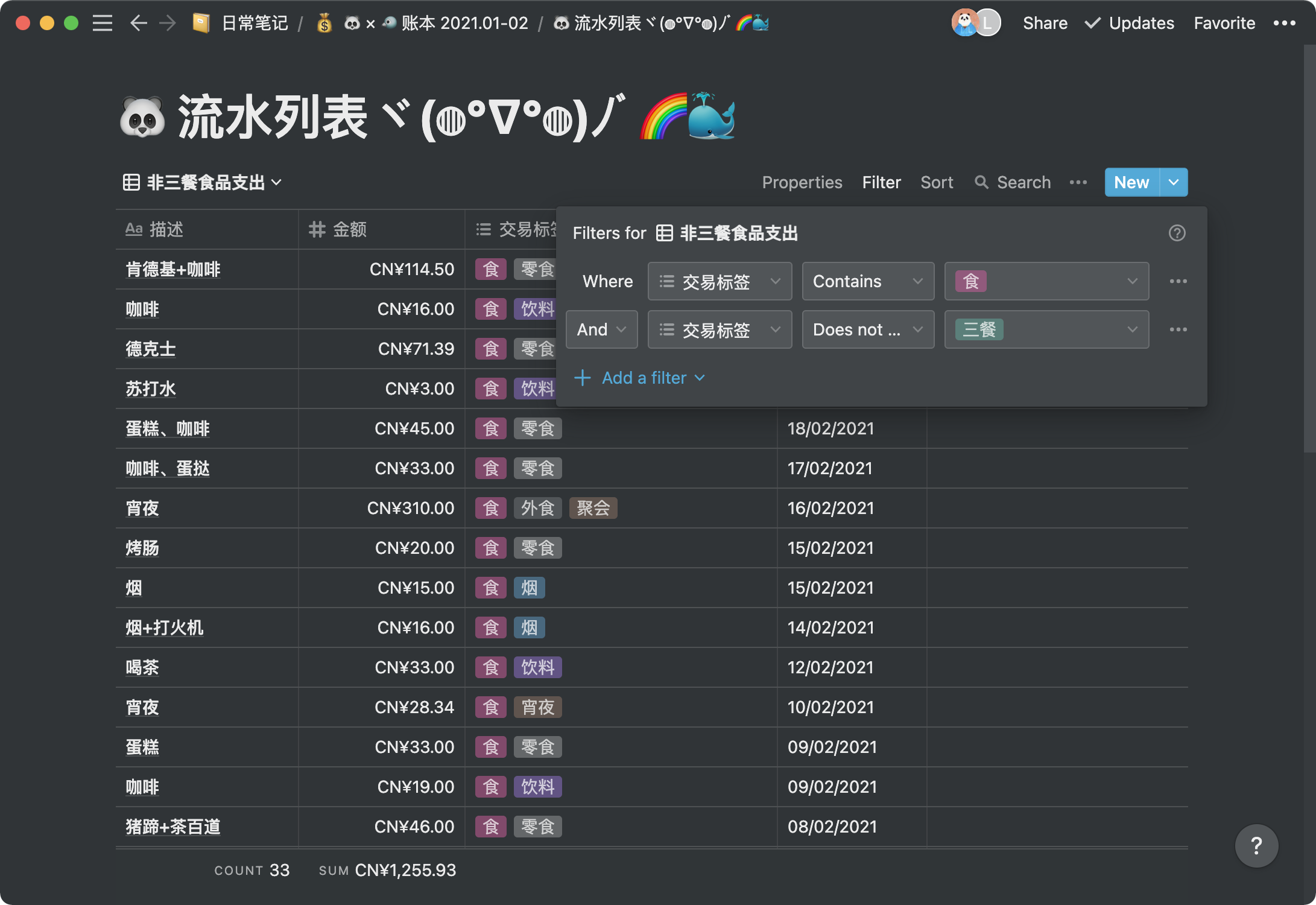
我开始是有点担心买回来吃灰的,因为在我的认知里 NAS 不过就是增加了一个管理面板的 Linux 服务器,顶多是稳定性稍微好一点,这样一来我家里的任何一台电脑都能胜任。到手探索了一段时间后发现群晖基于「存储」这个核心做了很多衍生,完全创造了新的价值。短短几天我就更新了认知:群晖 NAS 给用户提供的是「好玩、自由、可靠的文件服务」。
文件共享服务器这个核心功能确实大多数的 Linux 都能做到的,群晖使用的也是 SMB、NFS、AFP 这些标准协议,但群晖 NAS 的优势在于这些服务开箱即用,支持十分全面,免去了很多繁琐的运维工作。基于文件存储的衍生服务才是群晖的独门绝技,这里我主要说的是 Synology Drive,Synology Photos 这两项服务。
Synology Drive 可以理解为自托管的类似 Dropbox 的服务,它在文件存储的基础上增加了同步、共享、协作等等特性。与 OneDrive、Dropbox 等类似,它也支持将远程存储映射到本地目录,并且官方支持 Windows、Mac、Linux(Ubuntu) 几大平台,对 Geek 相当友好。增量同步是有的,按需同步目前在 Windows 上支持,据官方表示今年 Q2 会上 Mac 平台。Synology Drive 还提供了 Web 界面,可以浏览文件,甚至也支持在网页端创建在线协作文档,就类似于 Google Docs 那种,个人用自必不说,对几人十几人的小团队来说也是堪用的。
Synology Photos 我还没有体验太多,大致是一套类似于 Google Photos 的服务,也支持基于 AI 的内容识别、照片归类等等。据深度使用过的人说,体验甚至比 Google Photos 更好,因为他不会压缩你的图片,空间限制也就是你的硬盘限制。
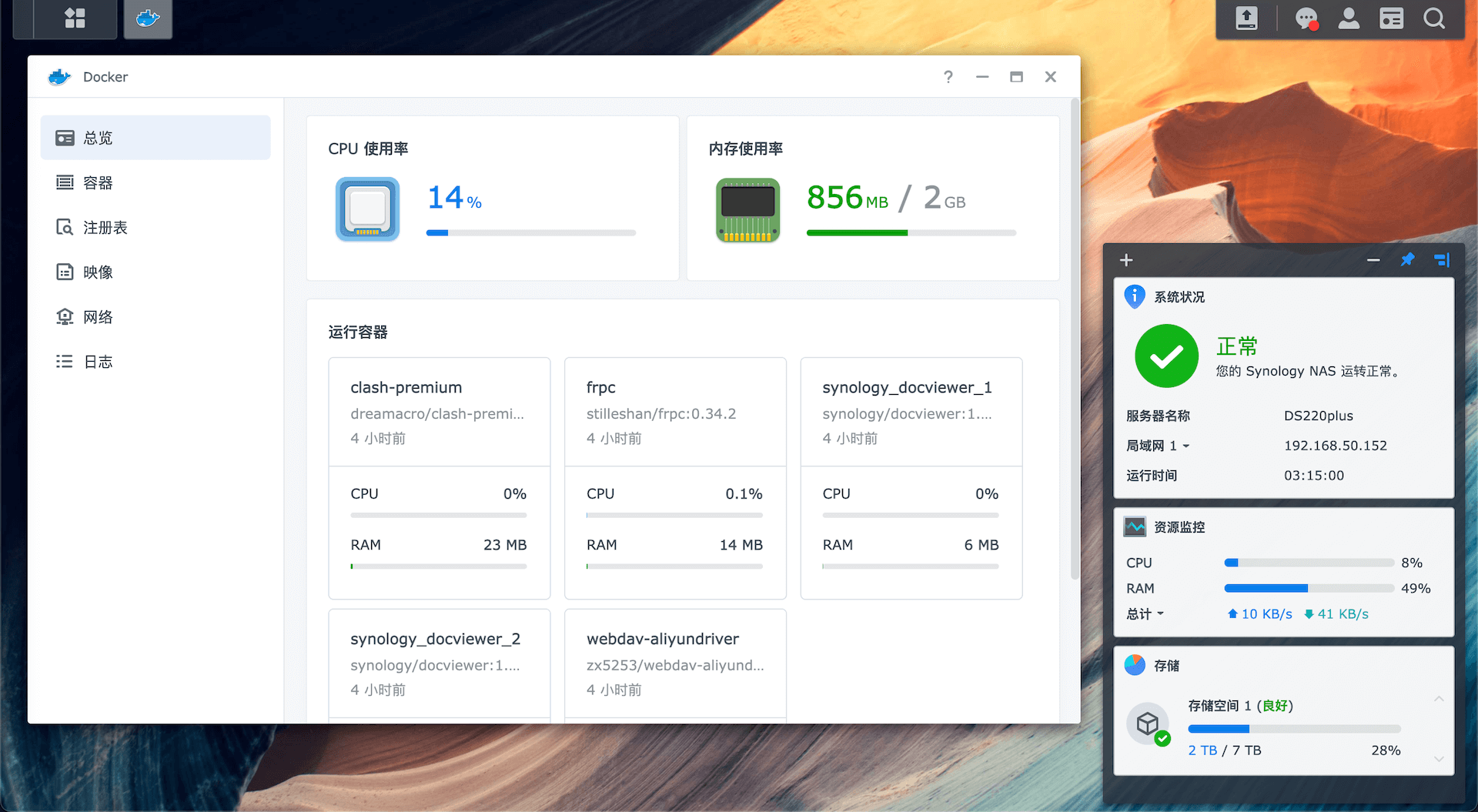
群晖 DSM 上还有很多优质套件,比如 Video Station,Audio Station 等,以及 Nginx,MySQL,PHP 等开发套件,应该是够技术达人们好好把玩一番了。还有一个套件是 Docker,我举两个用例。
国内环境里,全面使用 NAS 作为个人存储解决方案最大的阻碍只有一个:公网 IP。没有公网 IP 的情况下要从外网访问 NAS 只能走群晖的 QuickConnect,叫「Quick」,其实很不「Quick」。FRP 这样的内网穿透服务使我们可以用一个有公网 IP 的 VPS 作为中转进而访问内网的 NAS。FRP,是可以通过 Docker 容器部署的,在群晖 NAS 上,部署只是点几下鼠标的工作量。基于此,我的 NAS 真正地随处可用了,它现在已经完全取代 OneDrive 成为了我所有文件的存取点。
阿里云盘大家都知道,不限速,资源也逐渐地在多起来。如果能在 Apple TV 上直接串流阿里云盘的内容是不是很美好?可惜阿里云盘并没有 TV 客户端。但是有人基于阿里云盘的 API 开发了 aliyundrive-webdav,可以直接把阿里云盘转换成一个 WebDAV 服务器,同样支持 Docker 部署在 NAS 上,这样在 Apple TV 上通过 Infuse 连上这个 WebDAV 服务器,你的阿里云盘立即就变成了一个巨大的媒体库,可以直接在 TV 上串流播放,爽不爽?
NAS 则让我从这种风险中解脱。数据存在硬盘上,硬盘放在家里。虽然说不上是绝对的安全(毕竟警察也可以没收我的 NAS),但是比起把数据放在某某云盘上可是安心多了。
本期揽件日志就到这里。我们拔高一点,上文的两个物件核心价值都来源于数据:NAS 让我以更稳定、可靠、可用的方式存储数据,Apple TV 则让我以最舒服的方式享受我的部分数据。数据到底多重要?现在,数据就是一切。把数据从公有云上撤下来、尽力保持数据私有,然后借助 NAS 获得不输公有云的可用性与可连接性,这是我当下的决定。
2021.08.14。EVA 最终篇终于有了可供观赏的资源,立刻看了。第一感是:唔,终于结束了。从高中时代至今我等这部最终篇已经等了太多年,自己也从十几岁的少年等成了社畜。从完结篇的角度看,《终》为整个系列画上了很圆满的句号,整部片子的告别意味很浓,大量用了老镜头,最后与每一位角色说再见,甚至是闪过了 TV 版所有标题作为告别,真让人怀念。电影终于交代了一切,从开始的动机到最终的结局。
或许是庵野真的厌倦了做这个系列,他从旧剧场版开始就一直在告诉观众的是,向前走吧,活在现实中吧,活在当下和未来吧,活在没有 EVA 的世界里吧。这部电影是与角色们,与庵野自己,与所有观众的最后一次促膝长谈。再见了,所有的 Evangelion。
前段时间 React 团队发布了一项用于解决 React 页面在多接口请求下的性能问题的解决方案 React Server Components。当然该方案目前还在草案阶段,官方也只是发了视频和一个示例 demo 来说明这个草案。
Server Components 官方在视频和 RFC 中说明了产生这个方案的主要原因是因为大量的 React 组件依赖数据请求才能做渲染。如果每个组件自己去请求数据的话会出现子组件要等父组件数据请求完成渲染子组件的时候才会开始去请求子组件的数据,也就是官方所谓的 WaterFall 数据请求队列的问题。而将数据请求放在一起请求又非常不便于维护。
既然组件需要数据才能渲染,那为什么接口不直接返回渲染后的组件呢?所以他们提出了 Server Components 的解决方案。我们暂且不管这其中的逻辑有没有道理,先来看看该方案的大体流程是怎样的。
方案的大概就是将 React 组件拆分成 Server 组件(.server.tsx)和 Client 组件(.client.tsx)两种类型。其中 Server 组件会在服务端直接渲染并返回。与 SSR 的区别是 Server Components 返回的是序列化的组件数据,而不是最终的 HTML。
可能带来的问题 通过接口将组件和组件的数据一并返回的方式带来了打包体积的优势,但是它真的能像 React Hooks 一样香吗?我觉得并不然。
接口返回 常规做法里前端 JS 中加载组件,接口返回组件需要的数据。而 React Server Components 中则是将二者合二为一,虽然在打包体积上有所优化,但是明显是把这体积转义到了接口返回中。特别是在类似列表这种有分页的请求中,这种劣势会更明显。明明组件只需要在初始的时候进行加载,但是因为被融合进接口里了,每次接口都会返回冗余的组件结构,这样也不知道是好还是不好。可能后续需要优化一下接口二次返回只返回数据会比较好。
服务器成本问题 这里所说的服务器成本有很多,首先是机器本身的成本。将客户端渲染行为迁移到服务端时候势必会增加服务端的压力,用户量上来之后这块的成本是成量级的在增加的。关于这个问题,官方提供的回复是随着服务器的成本降低势必 Server Components 带来的优势会抵消这块的劣势。
Question: This might become more expensive for applications. In the search demo, finding those search results plus rendering them on the server is a more expensive operation than just an API call sent from the client.
Reply: We are moving some of the rendering to the server–so it’s true that your server will be doing more work than before. But server costs are constantly going down, and far more powerful than most consumer devices. I think React Server Components will give you the ability to make that tradeoff and choose where you best want the work to be done, on a per component basis. And that’s not something that’s easily possible today. via: 《RFC: React Server Components》
不过以目前我所在的业务情况来看,服务器的成本还是非常贵的,为了降低成本大家纷纷将逻辑下发到边缘计算甚至是客户端处理。一方面是为了节省成本,另一方面也是为了降低压力加快处理。
除了机器本身的成本之外,请求的成本也会增加。毕竟除了数据请求之外还要处理组件渲染,而且这块作为组件耦合不好进行拆分。相比较常规方案,使用 JS 文件加载组件到客户端,接口单纯返回数据,这块的时间成本增加了非常多。特别是常规方案中 JS 文件加载完之后是在浏览器中缓存的,后续的成本非常小。
体积问题可能还好,但是请求时间增加了这个可能就非常致命了。
心智负担 这点在 RFC 中也有说明。由于 Server Components 中无法使用 useState, useReduce, useEffect, DOM API 等方法,势必这会给使用者带来大量的心智负担。虽然官方说会使用工具让开发者做到无感,且会提供运行时报错,但是我相信光是想什么时候需要写 Server Componet 什么时候需要写 Client Component 就已经脑壳疼了吧,更别提还有个 Shared Component 了。
另外还有就是增加了跨端的流程之后,调试的成本也会变的非常高。别说很多人没有服务端的经验,就算是有相关经验的同学可能也没办法很好的在服务端进行快速定位。关于这个问题官方提供的说法是可以依赖内部的错误监控和日志服务。
回归问题的本质 让我们回归到问题的本质,React Server Component 的目的其实是为了解决接口请求分散在各组件中带来的子组件的数据请求需要等待父组件请求完成渲染子组件时才能开始请求的数据请求队列问题。那么除了 Server Component 之外没有其它的解决方案了吗?其实不然。
import React, {useState, useEffect} from 'react'; import ReactDOM from 'react-dom'; function App() { const [data, setData] = useState([]); useEffect(() => { fetchData.then(setData); }, []); return ( <div> {!data.length ? 'loading' : null} <Child data={data} /> </div> ); } function Child({data}) { const [childData, setData] = useState([]); useEffect(() => { fetchChildData.then(setData); }, []); if(!data.length) { return null; } return ( <div>{data.length + childData.length}</div> ); } ReactDOM.render(<App />, document.querySelector('#root')); 如示例代码所示,只要加载组件,但是在无数据情况下不返回 DOM 也是可以做到子组件的数据先请求而无需等待的。当然这种需要认为的在写法上进行优化,但我也仍然认为比大费周章的去做 Server Component 要好很多。
至于 Server Component 带来的打包体积优化这个问题,我觉得 RFC 里面的评论说的非常的好。”比起 83KB(gzip 后大概是 20KB)打包体积,我觉得在项目中为了格式化日期使用一个 83KB 的库这才是更大的问题。“
Removing a 83KB (20KB gzip) library isn’t a big deal, I would say the bigger problem here is that you’re using a 83KB library to format dates. via: 《RFC: React Server Component》
实际上官方列举的两点关于日期处理以及 Markdown 格式处理的库,可以看到都是针对于数据进行处理的需求。针对这种情况如果觉得这块的体积非常”贵“的话完全是可以让服务端将格式化后的数据返回,这样岂不是更小成本的解决了这个问题?
后记 看完 《RFC: React Server Component》 中所有的讨论,大部分人对 Server Component 还是持不赞成的态度的,认为它可能并没有像 React Hooks 那样解决业务中的实际痛点。就目前暴露的提案,我个人也觉得 Server Component 是弊大于利的。目前就期望官方如果要实现的话能解耦实现,不要影响未使用 Server Component 的 React 用户打包体积。
当然该提案我觉得不是没有好处,它最大的好处我个人认为是带来了 React 组件序列化的官方标准。为多端、多机、多语言之间实现 React 组件交流提供了基础。基于这套序列化方案,我们可以实现组件缓存存储,多机器并发渲染组件等。至于多语言实现也是在 RFC 讨论中大家比较关心的问题,通过这套序列化标准让其它语言去实现 React 组件也不是没有可能。
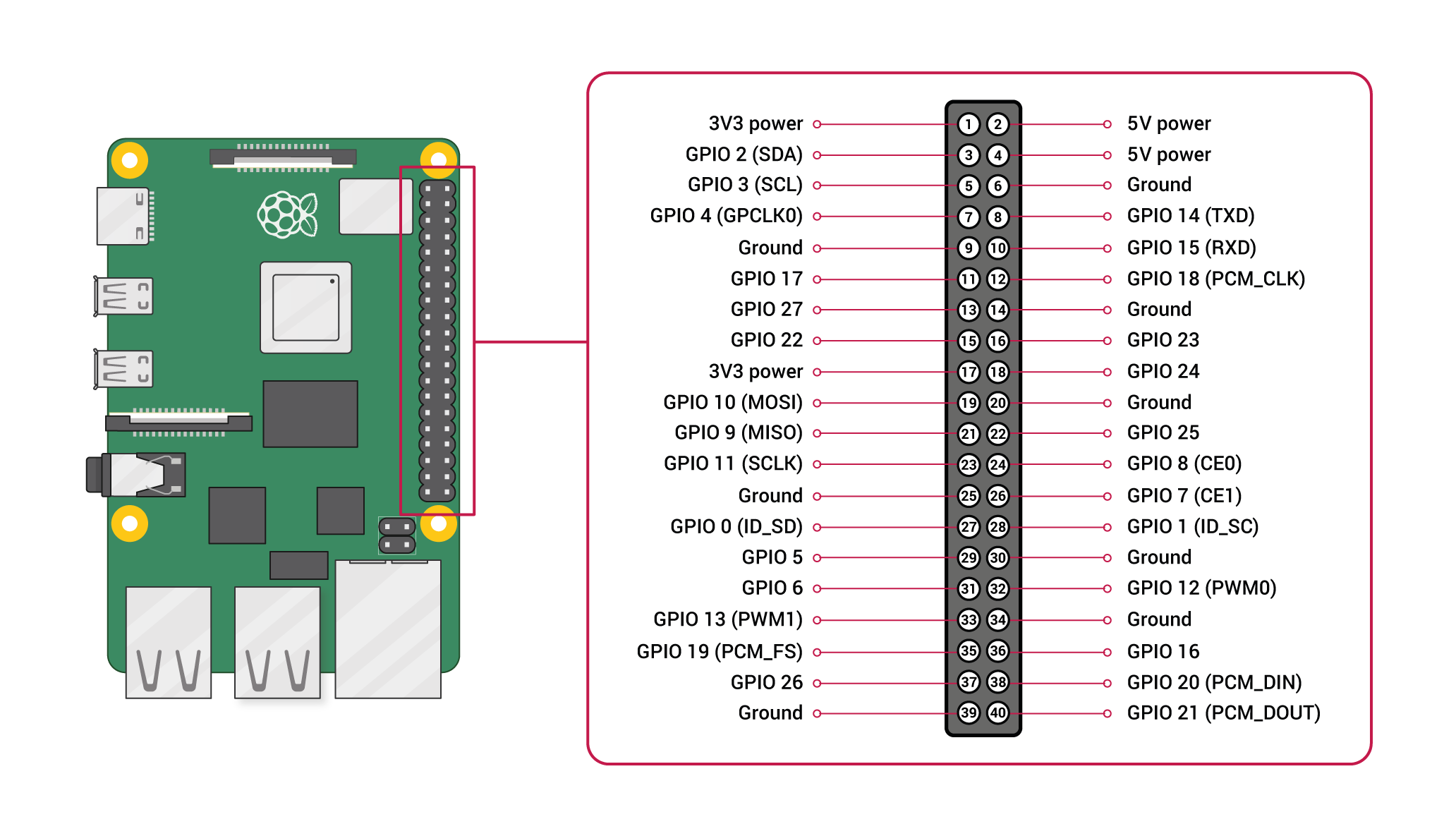
#!/usr/bin/python3importtimetry:importRPi.GPIOasGPIOexceptRuntimeError:print("Error importing RPi.GPIO!")defcpu_temp():withopen("/sys/class/thermal/thermal_zone0/temp",'r')asf:returnfloat(f.read())/1000defmain():channel=14GPIO.setmode(GPIO.BCM)GPIO.setwarnings(False)# close air fan firstGPIO.setup(channel,GPIO.OUT,initial=GPIO.LOW)is_close=TruewhileTrue:temp=cpu_temp()output=' '.join([str(time.ctime()),str(temp)])ifis_close:iftemp>=65:GPIO.output(channel,GPIO.HIGH)is_close=Falseelse:iftemp<55:GPIO.output(channel,GPIO.LOW)is_close=Trueifis_close:output+=' fan off'else:output+=' fan on'withopen('/var/log/autofan.log','a+')asf:print(output,file=f)time.sleep(2.0)if__name__=='__main__':main()
































 翻页
翻页
 速度。
速度。