
假期还是如约而至了,晚上本来想早点休息的,毕竟早上两点就要爬起来出发了。
但是,洗刷完,却怎么也睡不着了。终于十一点多 迷迷糊糊睡着了,夜里起来上一趟厕所,看了下时间,差几分钟不到一点。
256块钱的早餐
宝子的小姨凌晨多一点点在群里发了一条消息说到家了,她们带着孩子,晚上八点就走了,两百多公里的路程,走了四个多小时,也在意料之内。从晚上就不断的关注路况,生怕堵车,高速的拥堵状况直到睡觉前,还有很多地方是大段的红色。
醒来之后再也睡不着了,打开地图看下路况,仅剩下往京沪高速拐的地方有一点红色,等跑到那里应该也就差不多了。窗外传来雨滴打在玻璃上的声音,躺在床上刷了会儿手机,一点半把他们叫起来,穿好衣服就准备出门了。

提前下去把车开到楼下,这样一来可以不用拖着行李走太多的路程,第二也免得那么多人被雨打湿衣服。
一路上相对来说还算顺畅,不过在到了临沂之后,导航提示出高速更快,然而,出高速之后导航的长深。在出发之前已经做过功课,长身高速修路,整体限速80,所以段然是不可以走的。出了高速,重新导航,折返一段,最终还是走的京沪。比较幸运的是一路上基本没什么突发状况,除了有一辆车翻在路中间,黑乎乎的看不清楚,其他的还是比较畅通的。

出发早的好处,在此刻也就体现出来了,路上没什么人,并且服务区也没什么人。

最终,终于在三个小时之后,天亮了。此时对象可以开车了,换自己休息下。不过,这临沂境内的大雾,真的浓重。可见度异常的低,只能降低车速行驶。
到处弥漫着浓重的雾气,这些雾气,让远处的风景变得不可捉摸。

五个小时候,总算是到了淮安。

到目的地之后,第一件事情,自然是找地方吃早饭啦。大众点评,找个最近的饭店,路上经过一座塔,后来折返回来之后才发现这座塔叫做爱心塔。

在饭店门口停车的时候,开过来一辆宾利。
“哇哦,咱们跟开宾利的吃一样儿的餐厅哎”我说。
“会不会吃不起啊?”对象问。
“不至于,不至于。开宾利的都吃,可能真的不错”我说完,就带着他们往里走。
在前台点餐,给个定位器,给张单子,就可以进去随便找地方做了。虽然已经快八点,不过吃饭的人还真的不少。

当然,最贵的还是蟹黄汤包,38一个。

给了一根吸管,用来喝汤。整体来说味道还算不错,但是没有那么惊艳,可能是没有多少蟹黄的原因吧。

一桌子菜,对于早餐来说确实多了点,不过,这一顿吃完,下一顿饭可能就得很晚啦。
窦娥,冤
吃完饭去民宿,安置好,稍微休息一下。不过,这民宿也是第一次见到没有电视的民宿,只有个电视机,古老的panda品牌,没有机顶盒,也没什么其他的播放设备,就这么孤零零的一个电视。的确有点匪夷所思。
中午简单的游览下,最终选择了清晏园。一个不大的园林,周边有两个停车场。然而到达目的地之后,却发现都满了,围着院子转了一圈,终于在门口又等到了机会,有车出来才好歹停了进去。不大的园林,好处是人不多,适合溜达,自然也不需要导游讲解。

一天的时间,过得还是很快,毕竟这一天的时间,还有很多实在路上消耗的。
第二天的行程自然也简单,主要目标是周恩来纪念馆。驱车前往导航的停车场,快到目的地的时候发现前方异常拥堵,直接右拐,找了个停车场停了进去。步行围绕纪念馆前面的湖转半圈即可到达,入口处的喇叭在广播持身份证入场,不过在实际进入的时候也没有查验。


主楼仅有雕塑能看,其他的地方都不开放。


沿着边上继续参观的牌子前进,竟然直接出来了。往后绕直仿照总理之前办公场所一比一复刻的办公室。

纪念馆人潮涌动,被裹挟着一路向前。从纪念馆出来之后,刚好可以从另外一侧的出口绕出去,沿着河岸继续前进,走不远就到了淮安府署,另外一个景点。

而至于,淮安府署。门票60一张,的确不便宜,然而,这个地方确满足了自己对于古代那些刑具的好奇心,与我而言的确是物超所值。淮安府署属于国内唯二保存完整的府衙结构之一,在刑狱一块的完整程度的确比较高。在其他地方不曾见过这些东西,之前的了解也仅限于书上,或者影视作品,或者之前看《世界酷刑简史》里面的一些图片。
而窦娥,也是在这个地方被斩首处死的。《窦娥冤》的故事大家应该都听过,讲的是:
是元代戏曲家 关汉卿 创作的杂剧,刊行于明万历十年(公元1582年),故事原型来自《列女传》中的《东海孝妇》。 全剧四折一楔子,写弱小寡妇 窦娥,在无赖 张驴儿 陷害、昏官 桃杌 毒打下,屈打成招,成为杀人凶手,被判斩首示众。 临刑前,满腔悲愤的窦娥许下三桩誓愿:血溅 白练,六月飞雪,大旱三年。 果然,窦娥冤屈感天动地,三桩誓愿一一实现。
这是语文课本中的内容,其实,后面还有,那就是:
刽子手行刑后。窦娥的鲜血竟然一滴都没有落在地上,全部飞溅在了高挂的白布上。当时围观的百姓暗自称奇。紧接着天地变色,狂风大作,天空飘起鹅毛大雪,密密地覆盖在窦娥的身上。那时候正是六月夏天,每一个在场的人都惊呼:“这窦娥真是冤枉的!”
接下来,楚州果真大旱了三年。所有人都相信窦娥的冤屈,为窦娥抱不平,直到窦娥的父亲窦天章在京城做官返乡,窦娥的冤案才得到昭雪,杀人凶手张驴儿被处以死刑,贪官知府也得到了应有的惩罚。
而至于窦娥冤,这罪魁祸首,自然是她的父亲,为了凑盘缠考取功名,把自己的女儿卖了!
刑科外面现在还矗立着腰斩台,用来实行腰斩的钺依然高悬。

只是不知道这死在腰斩台台上的人,有多少罪大恶极,又有多少含冤负恨。用来控制钺升起的绞绳已经被锁死,自然无法再拉上去,或者放下来。另外一侧没有锁死,可以自由的转动,但是不会有任何实质性的变化。
本来,想着这淮安府署也不过如此,自己坐在院子里耍手机,对象带着宝子去溜达,过了回来对象回来很神秘的跟我说:“你该去看看刑科的东西,应该是你感兴趣的”

听到这句话,我蹭的一声蹦起来,这自然是要去看的。腰斩台边上叫做皮场庙,这个庙自然是用来剥皮的。


既然是针对贪官剥皮,在古代自然都是男性,不得不说,这里面的还原度是真的不错,连阴茎的皮都给呈现了出来,自然,这种活在古代也是一种手艺。剥皮自然要完整,不过这个东西无法申请非遗,毕竟现在申请了,那些贪官也不能拿来真给剥皮。
初次之外,看到了另外一个刑具,那就是木驴。


这个刑具,其实并不是单纯给女性设计的。男性一样适用,毕竟男人下面也有个洞不是吗?看着这粗大的棍子,就该猜到插到下体里面是什么感觉了。《窦娥冤》最后一折,就有关于张驴儿骑木驴的判罚:
你这一行人,听我下断:张驴儿毒杀亲爷,谋占寡妇,合拟凌迟,押付市曹中,钉上木驴,剐一百二十刀处死。
钉上木驴,自然就是汤张驴儿直接骑到这个东西上面。之后就是凌迟处死,不过这个凌迟的判罚并不算重,一百二十刀而已,如果真的判千刀万剐,一千刀,那自然是要割完一千刀才能死。对于这种行刑,自然也是需要深厚功力,申请非遗恐怕也找不到师傅了。这凌迟要从身体最不重要的部位开始,比如乳头,耳朵,鼻子,嘴唇,屁股,大腿等等。一步一步的向中间靠近,据传最厉害的刽子手,在快一千刀割完的时候,胸部只剩下一层薄膜,透过肋骨能看到跳动的心脏。
而这最后一刀就是捅进心脏里。
而至于这其他的刑法,不管是世界酷刑描述的多么厉害,其实与中国古代的酷刑相比,并没多先进,人性使然,所以折磨人的方法也自然大同小异。
当然,也有专门区分性别的刑法,例如“乳夹”,这个要夹男人的话可能就有些难度了。
不过有个屋子做了各种行刑的动画,当然,我最想看的木驴和凌迟没有,有点遗憾。
只是,这窦娥,的确死的冤!
金湖水上森林,我比窦娥还冤
第三天,选了个稍微远点的地方,金湖水上森林,这个地方在大众点评上的评价两极分化。不过来都来了,去看看也行,驱车前往一百公里,的确有点远,不过好在路上还是比较畅通的。

买票的时候本来想就买个门票,剩下的就算了,对象表示买套票,最后买了110的套票。进门就遇到了第一个障碍,等摆渡车的人排队都要排到大门外了。
只好先去做竹排,沿着最美步道,一路前行。步道的美景真的不错。


那种原始森林的感觉,让人心旷神怡。然而在步行了差不多一公里到了竹排的地方,发现排队的都要排到大路上了。

带拐弯的队伍,并且队伍又粗又长,看到这种队伍就真的让人挺反感的。主要问题还是工作人员的不作为,警戒线就在拐弯的地方有一点点。终于到了拐弯的地方,还出现一堆插队的,跟维持秩序的工作人员说,我们是一起的,于是一下子塞进来五六个人。工作人员装死,啥都没看到,自己也没必要说什么了。更神奇的是,塞进来的那些都没买船票,问题船票那里买的,这就尼玛离谱。
又让我想到了昨天中午吃饭排队等号的情景,看所有的餐厅都在排队,唯有一家浦园中桌和大桌没有排队的,于是选了他们。到了之后,取号也很方便,给了个b09。说现在叫号的是06,需要等三桌。然而,等了半个小时了,一个号都没叫,问什么情况,说要等。
终于,快一个小时了,再问说现在是按照等待时间叫号,跟小卓一起的,中桌是加的凳子,真是心里一万个草泥马奔过。
但是a都从a40叫到a60了,实在忍不住去看叫号机。这时候刚要叫a61,实在忍不住了问服务员:“刚才就说下一桌,现在下一桌怎么又要61了?!”
“再下一桌就是你们了”服务员说答到。
“你们不是按照等待时长吗?我们等了69分钟了,a61只有60分钟,凭什么先叫61?”我继续问。
“这……”服务员吞吞吐吐,“你们先来吧”
就这菜算吃上饭,而此时已经都两点了,等号的人就还我们几个。吃饭的都吃完走了,这体验真的只能说是垃圾!
现在又来这么一出,我也不管队伍粗不粗了,拉着宝子往前挤,我可去你妈的吧。就这样,我一个人开路,拉着四个人往里挤,把那几个给挤到了后面。
半个小时一个项目,等下一个项目小火车,这次要好很多,因为有围栏,只能一个一个往前走。排进去,等了十几分钟不动,这时候有人说小火车半小时一趟。我数了数前面的人,大约得最少一个小时。这时候有人等不了了,直接跳出去或者逆行出去了,就这样等了半小时,等没了二十几个人。不过好处是,感觉等一个小时就能坐上了。





鉴于这种秩序,我要然还是拉着宝子尽量往前走。小火车拉着人走的时候我说:“这也太慢了,蛆guyong的都比他快!”
“别瞎说,比蛆快”我对象说,“等你上车了就不嫌他慢了,慢悠悠多好”

这体验,不说要求有多高,最起码把秩序维护好吧。
下了小火车,宝子的姥姥姥爷死活不往回走了。于是带着宝子去萌宠乐园等其他的地方玩,说实话,真的啥都没有。风筝广场,就他们自己放的三四个风筝。

只看到尼玛跟葫芦娃一起上天了。

玻璃栈道上都是人,下滑的速度太慢了,本来还想跟宝子去的,后来看这个速度直接放弃了。
这景区,感觉真的不值这个价格,如果评价的话,五星能得一星,其中0.9星是给那个最美步行道的。
而至于这最美味卫生间(我给他起的名字,其实叫最美卫生间),真的不知道有啥卵用。

出园的时候发现小火车排满了,而这么多人,没四五个小时根本排不上。来这地方,果然是妥妥大冤种。
接着奏乐,接着舞
晚上的夜市,感觉更有意思。
古城,国内的古城都大同小异,看不出太多的区别。





第二天大学城的夜市人头攒动。

天还没黑就已经很多人了。

逛了会儿,发现卖香水的,于是69买了一只香水。

然后买了半只兔兔吃掉了。

最后一晚,来都来了,怎么也得去最热闹的地方看看。九点多出门,自己住的地方一如往日的宁静,路上也没什么车。然而,到了里运河文化长廊才发现,人可能都在这里吧。路上行人如织,走都走不动。终于找了个路边把车停下。往河边走各种拍照打卡的,卖各种吃的小贩,占满了整个街道。
而既然来了,那就酱紫吧。接着奏乐,接着舞。
The post 窦娥,冤 appeared first on obaby@mars.










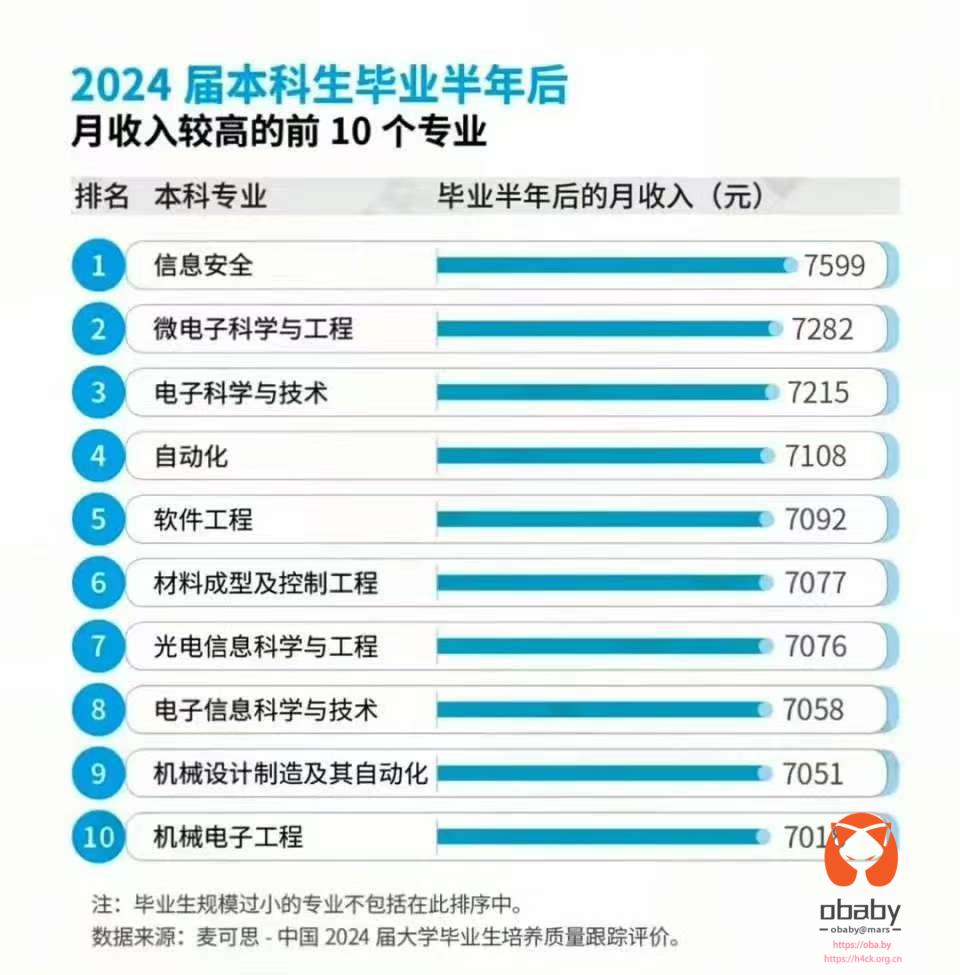






























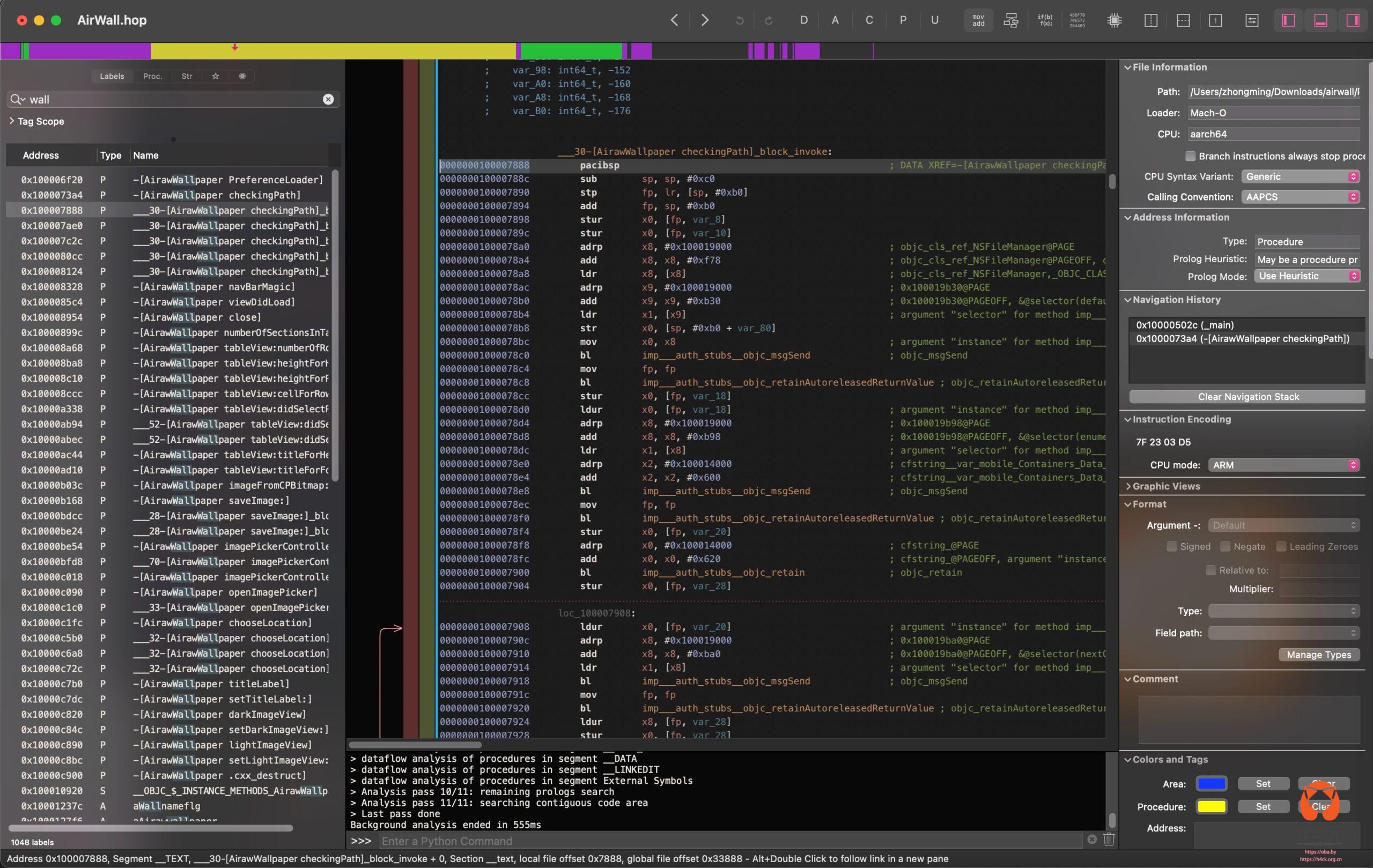
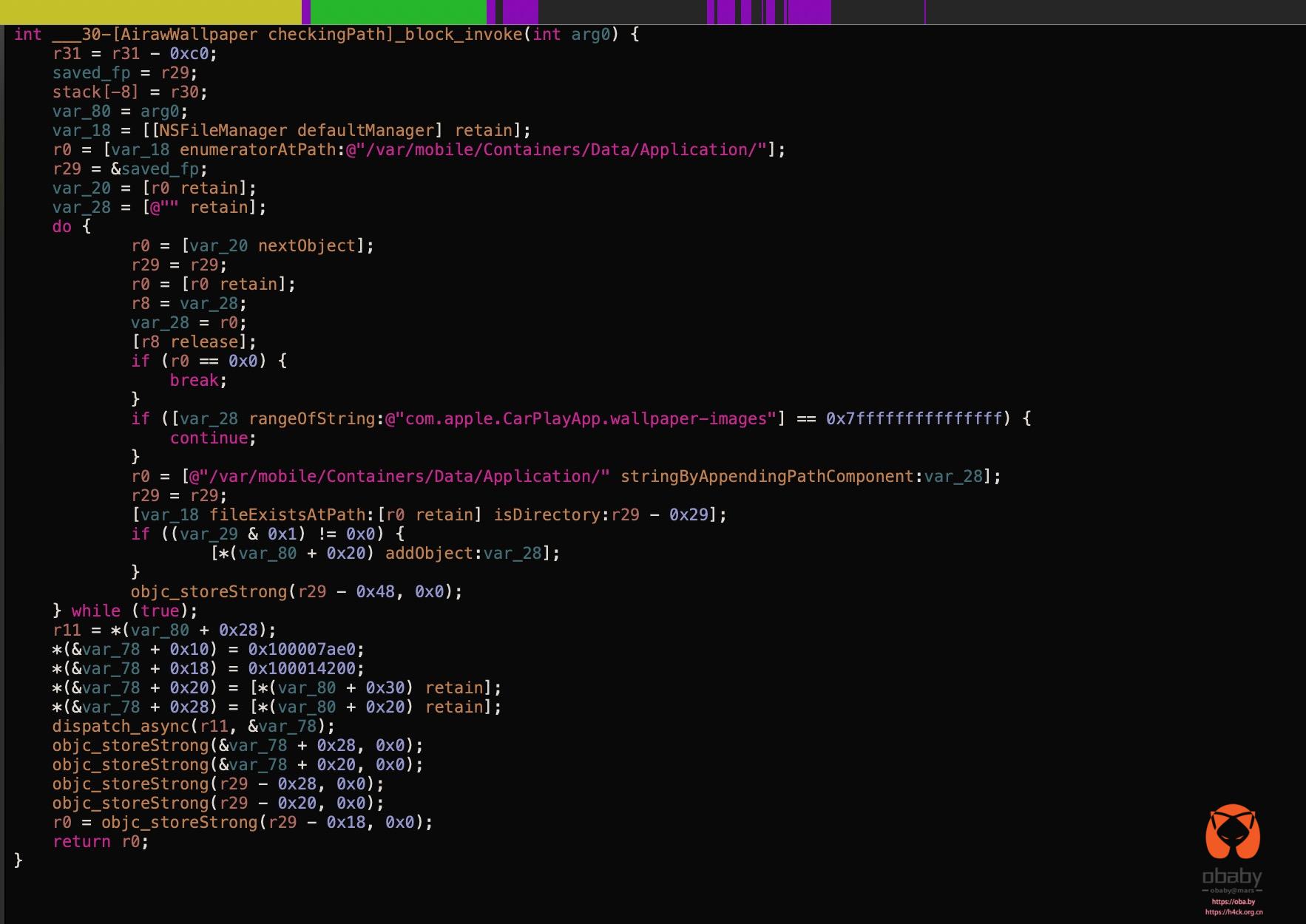
 _CodeSignature 目录不存在,这可能导致安装失败"
fi
# 显示更多签名信息
echo "显示详细签名信息..."
codesign -d --entitlements :- "$APP_PATH"
# 验证所有签名
echo "验证所有签名..."
if codesign --verify --deep --strict --verbose=4 "$APP_PATH"; then
echo "✓ 严格验证通过"
else
echo "
_CodeSignature 目录不存在,这可能导致安装失败"
fi
# 显示更多签名信息
echo "显示详细签名信息..."
codesign -d --entitlements :- "$APP_PATH"
# 验证所有签名
echo "验证所有签名..."
if codesign --verify --deep --strict --verbose=4 "$APP_PATH"; then
echo "✓ 严格验证通过"
else
echo "















































































































































 ,忽然觉得抽到那么多隐藏款也不是什么特别让人开心的事情,不过宝子已经决定把这个敖光送人了。知我的蓝胖子后面的卡片,都是我买的,并且都是最低级的卡。这运气不得不说,区别有点大。当然宝子不可能就这几个,柜子里已经塞了很多了。
,忽然觉得抽到那么多隐藏款也不是什么特别让人开心的事情,不过宝子已经决定把这个敖光送人了。知我的蓝胖子后面的卡片,都是我买的,并且都是最低级的卡。这运气不得不说,区别有点大。当然宝子不可能就这几个,柜子里已经塞了很多了。





 ,昨晚睡觉的时候我跟对象说,我每天流鼻涕也能轻二两,助力了我的减肥事业。
,昨晚睡觉的时候我跟对象说,我每天流鼻涕也能轻二两,助力了我的减肥事业。
































