Focalboard 开源项目管理的有力工具
在当今数字化协作的时代,高效的项目管理工具对于团队的成功至关重要。Focalboard 作为一款开源的项目管理软件,正逐渐崭露头角,受到了众多团队和个人的青睐。
简介
Focalboard 是由 Mattermost 开发的功能强大的开源项目管理和协作工具,能够以看板的形式灵活地组织任务,创建详细的笔记,并方便地共享文件。它支持创建各种类型的笔记页面,记录数字、链接、文字等多种类型的信息,且内置了多种模板供用户直接套用编辑。
Focalboard 具有以下特点:一是开源免费,数据自托管,用户可将其部署在自己的本地服务器上,确保数据安全可靠;二是支持多平台,包括 Windows、macOS、Linux、iOS 和 Android 等,方便用户随时随地接入项目;三是具备丰富的功能,如拖放卡、进出口板、按状态或截止日期等过滤板和任务,以及支持多人协作、文件共享、团队和直接消息等;四是界面简洁易用,操作便捷,易于上手。
安装
Focalboard 的安装方式主要有以下几种:
- 使用 Docker 安装
这是在 Windows 系统上较为便捷的安装方式。首先需要在 Windows 中安装 Docker,然后打开 cmd 命令行,输入命令 docker run -it -p 80:8000 mattermost/focalboard,等待安装完成。安装成功后,在 Docker Desktop 中可以看到 Focalboard 的 web 界面地址为 https://localhost:8000,点击该地址或在浏览器输入 localhost:8000 即可进入 Focalboard 登录界面。
- 在 Ubuntu 系统上安装
以 Ubuntu 22.04 为例,安装步骤如下:首先是安装和配置 PostgreSQL 数据库,使用命令 apt-get install curl wget gnupg2 -y 和 apt-get install postgresql postgresql-contrib -y 进行安装,然后创建数据库和用户。接着安装 Focalboard,可从官网下载适用于 Ubuntu 的安装包,再通过命令进行安装。安装完成后,需为 Focalboard 创建系统服务文件,并将 Nginx 配置为反向代理,最后访问 Focalboard 网络界面并启用 SSL。
- 直接下载安装包安装
可前往 Focalboard 的官方网站(https://focalboard.com/)下载适用于不同操作系统的个人桌面版或个人服务器版的安装包,按照提示完成安装。
使用
- 创建团队和看板
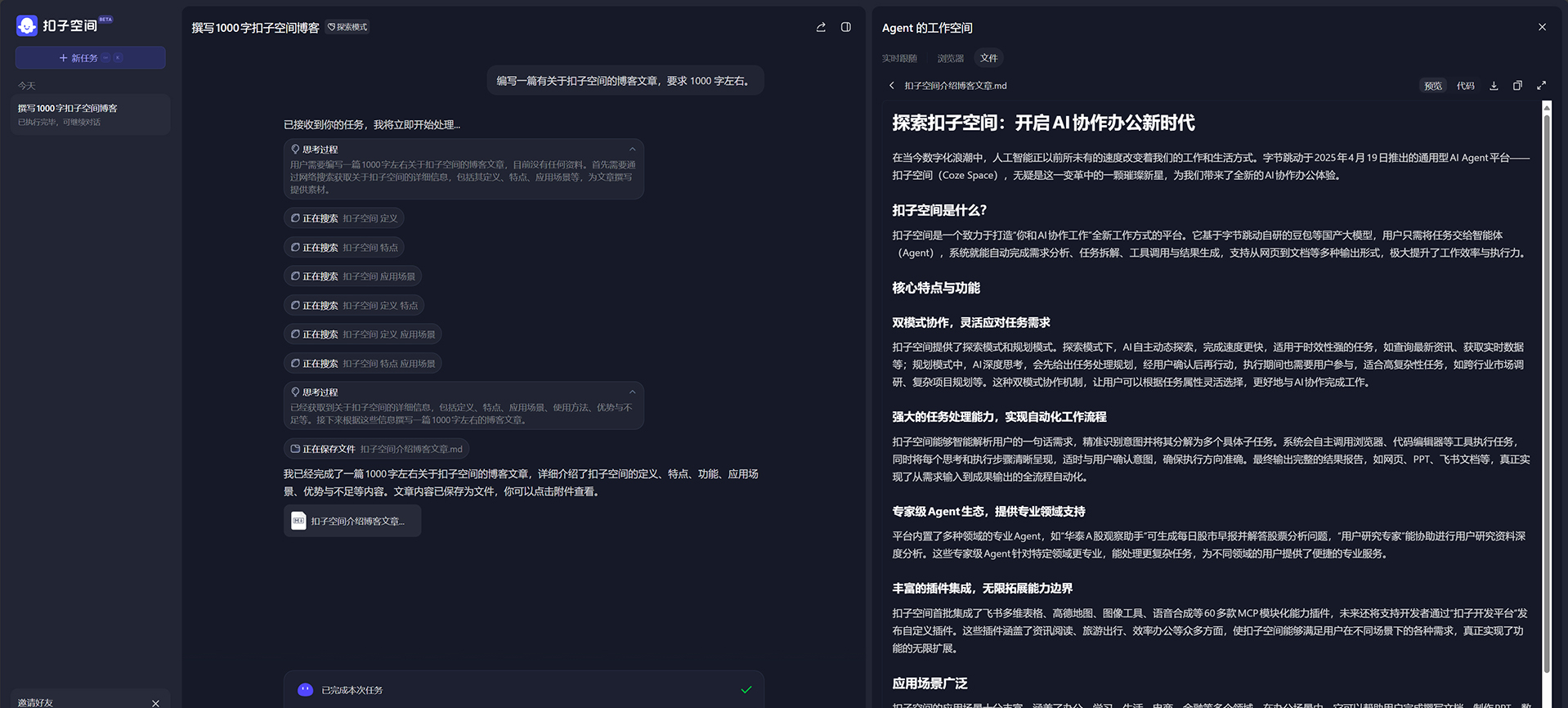
在 Focalboard 的欢迎屏幕上,用户可选择创建新的团队并设置团队名称。进入团队页面后,点击 创建看板 按钮,根据需要选择看板类型,如项目任务、内容日历、公司目标与 OKR、路线图等模板创建看板,也可创建空白看板自行设计。还可设置看板的名称、描述和背景色等信息。
- 添加任务和卡片
在看板上,通过点击 添加卡片 按钮来创建新的任务卡片。可在卡片中输入任务描述,并为卡片添加标签、截止日期、优先级等属性,以便更好地对任务进行分类和管理。同时,可以将任务卡片分配给团队中的不同成员,明确责任分工。
- 进行协作和沟通
团队成员可以在看板上实时查看和编辑任务卡片,共同推进项目进度。在卡片中添加评论和讨论,@提及队友以引起他们的注意,分享想法和意见,实现高效的协作沟通。此外,还可通过 Focalboard 的团队和直接消息功能,进一步加强团队成员之间的交流。
- 利用其他功能
Focalboard 支持文件共享,用户可在任务卡片中上传相关文件,方便团队成员查阅和下载。可对看板进行筛选、分组和排序,快速找到所需的任务和信息。还能查看历史记录、备份快照等,确保数据的安全性和可恢复性。