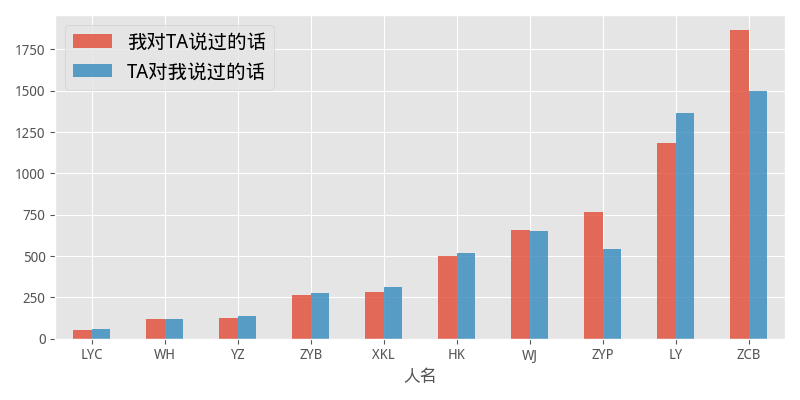
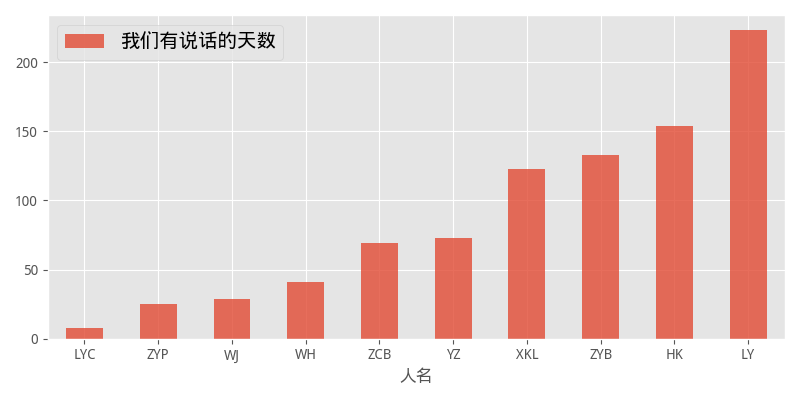
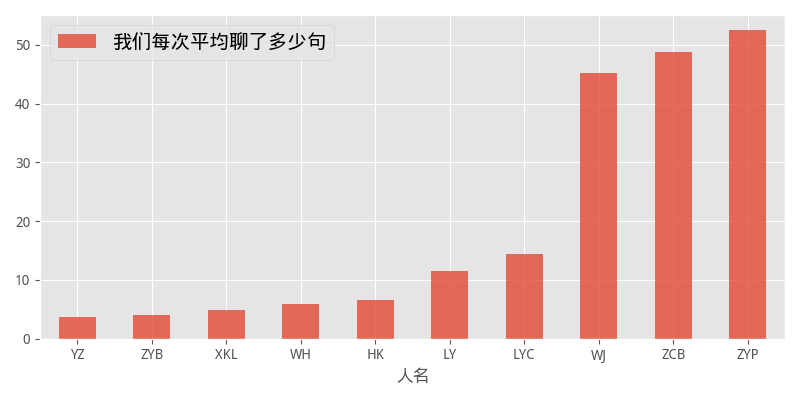
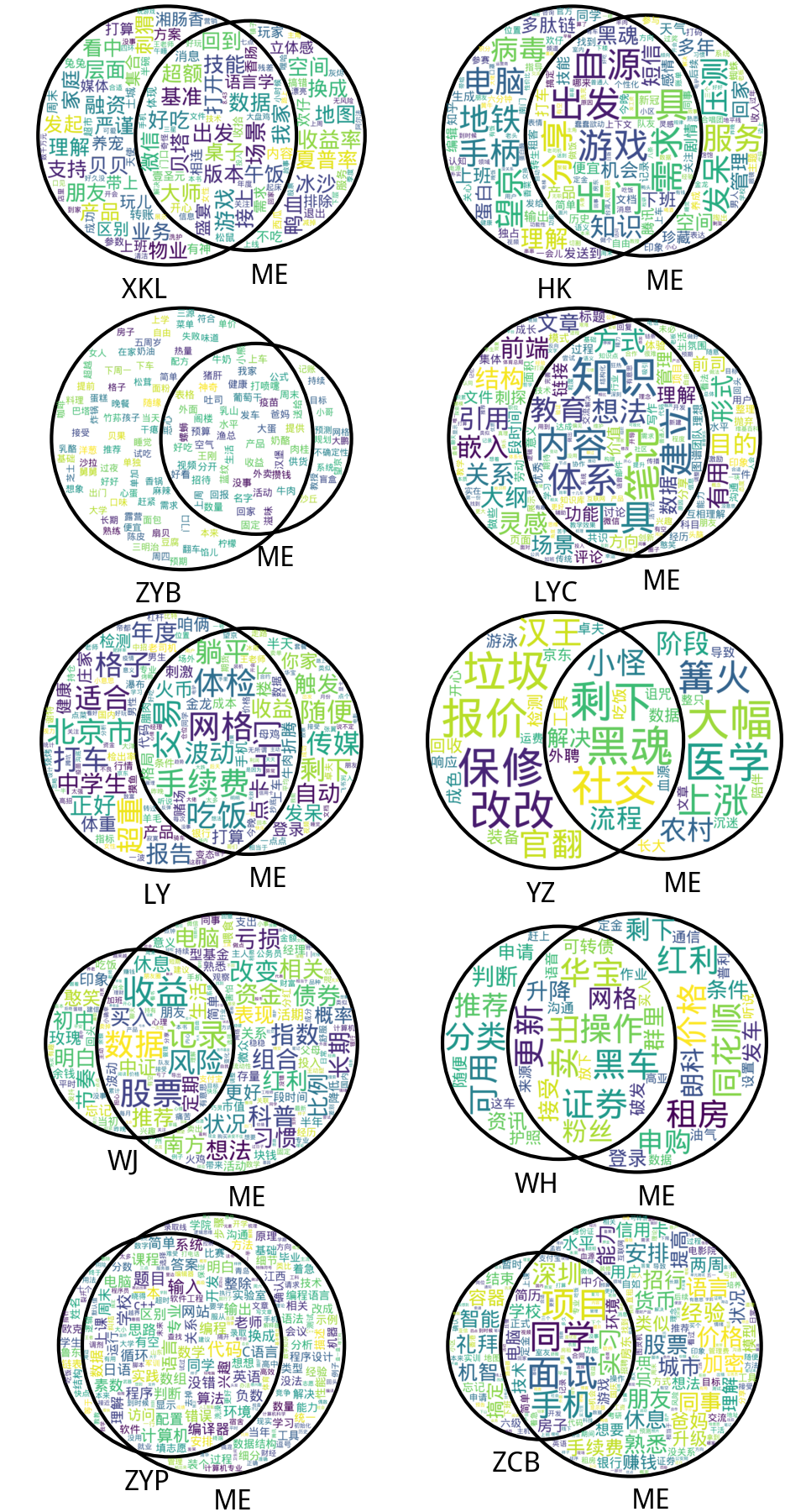
本文是《LLM Prompt Engineering 实践》系列的第二篇文章,系列文章如下:
- LLM Prompt Engineering 实践:序 · ZMonster's Blog
- LLM Prompt Engineering 实践:原型 · ZMonster's Blog
- LLM Prompt Engineering 实践:记忆(1) · ZMonster's Blog
在 ChatGPT 的帮助下,给项目起了 xorius 这么一个名字,这个单词实际上并不存在,所以含义完全是由我来定义的,不过作为一个随时可能会鸽掉的项目,就先不说我给它赋予的意义了,以后做大做强再来说会比较合适一点。
起好名字后,我准备先实现一个最最简单的原型出来,并在过程中对一些问题进行讨论。后文所有内容都是我的开发日志的整理汇总,之后的文章基本上也会采用这个模式。
为了实现原型,有两个选择,一是直接去调用 OpenAI 的官方接口或 SDK,二是选择 langchain 之类的第三方封装,出于方便考虑,我选择了 langchain。
首先,无论是直接调用官方接口、SDK,还是使用 langchain,国内都是需要通过代理才能访问的:
import openai
openai.proxy = 'http://localhost:8080'
设置好代理后,用 langchain 就可以简单地调用 OpenAI 的接口来获得回答,比如说这样:
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage
user_message = HumanMessage(content='将这句话翻译成中文: “to be or not to be”')
# 安全考虑这里把真实 API KEY 隐藏了,后文不再强调
llm = ChatOpenAI(temperature=0, openai_api_key='sk-xxxxxxxxxxxxxxxx')
answer = llm([user_message])
print(answer.content)
上面的代码没有指定要使用的模型,默认会使用 gpt-3.5-turbo,运行后得到了这样的结果
生存还是毁灭
当然,这段代码不是对话的模式,没有考虑聊天历史,如果要做聊天的话,需要维护一个聊天历史
from langchain.memory import ChatMessageHistory
memory = ChatMessageHistory()
之后每次的用户输入和得到的回答都可以按顺序添加到这个 memory 里面,比如说前面的 user_message 和 answer,都可以加到里面去
memory.add_user_message(user_message.content)
memory.add_ai_message(answer.content)
通过 memory.messages 可以得到历史记录
结果
[HumanMessage(content='将这句话翻译成中文: “to be or not to be”', additional_kwargs={}, example=False),
AIMessage(content='"生存还是毁灭"', additional_kwargs={}, example=False)]
然后在下一轮对话时使用它
user_message = HumanMessage(content='再翻译成日语')
answer = llm(memory.messages + [user_message])
print('Answer:', answer.content)
memory.add_user_message(user_message.content)
memory.add_ai_message(answer.content)
print('History')
print(memory.messages)
结果
Answer: "生きるか死ぬか"
History:
[HumanMessage(content='将这句话翻译成中文: “to be or not to be”', additional_kwargs={}, example=False),
AIMessage(content='"生存还是毁灭"', additional_kwargs={}, example=False),
HumanMessage(content='再翻译成日语', additional_kwargs={}, example=False),
AIMessage(content='"生きるか死ぬか"', additional_kwargs={}, example=False)]
综合上面的代码,只要写一个循环,就能做持续的对话了
from langchain.chat_models import ChatOpenAI
from langchain.memory import ChatMessageHistory
memory = ChatMessageHistory()
llm = ChatOpenAI(temperature=0, openai_api_key='sk-xxxxxxxxxxxxxxxx')
while True:
user_message = input('You: ').strip()
if not user_message:
continue
if user_message.lower() in ('quit', 'exit'):
break
memory.add_user_message(user_message)
answer = llm(memory.messages)
print('BOT:', answer.content)
memory.add_ai_message(answer.content)
不过上面这段代码是有问题的,因为实质上我是每次都把历史消息和当前输入拼接起来输入给 OpenAI 的接口,而 OpenAI 的接口对处理的文本总长度是有限制的,gpt-3.5-turbo 最大长度是 4096 个 token,gpt-4 最大支持 32768 个 token(这个 token 是语言模型里对文本切分后的最小单元,先不用细究),像上面这样一直把 user_message 和 answer 往 memory 里面加,那么只要对话轮次够多一定会超过这个限制的,超过了就会报错,所以必须要限制一下。需要注意的是,这个最大文本长度,是输入和输出加在一起算的,比如说如果用 gpt-3.5-turbo 然后输入就已经 4000 token 了,那么只能输出最长 96 个 token 的结果。
综上,为了保证不超出接口长度限制,需要只取 memory.messages 中的一部分,假设取的 memory.messages 中的这部分的总 token 数 为 L1,我们还要保证输出结果的总 token 数能达到 L2,那么必须保证 L1 + L2 < 4096,L2 可以在初始化 ChatOpenAI 的时候通过参数 max_tokens 来设置,默认没设置就是无限,那为了更好地计算 L1,需要显式设置一下它,比如说设置为 1024:
max_tokens = 1024
llm = ChatOpenAI(
temperature=0,
openai_api_key='sk-xxxxxxxxxxxxxxxx',
max_tokens=max_tokens
)
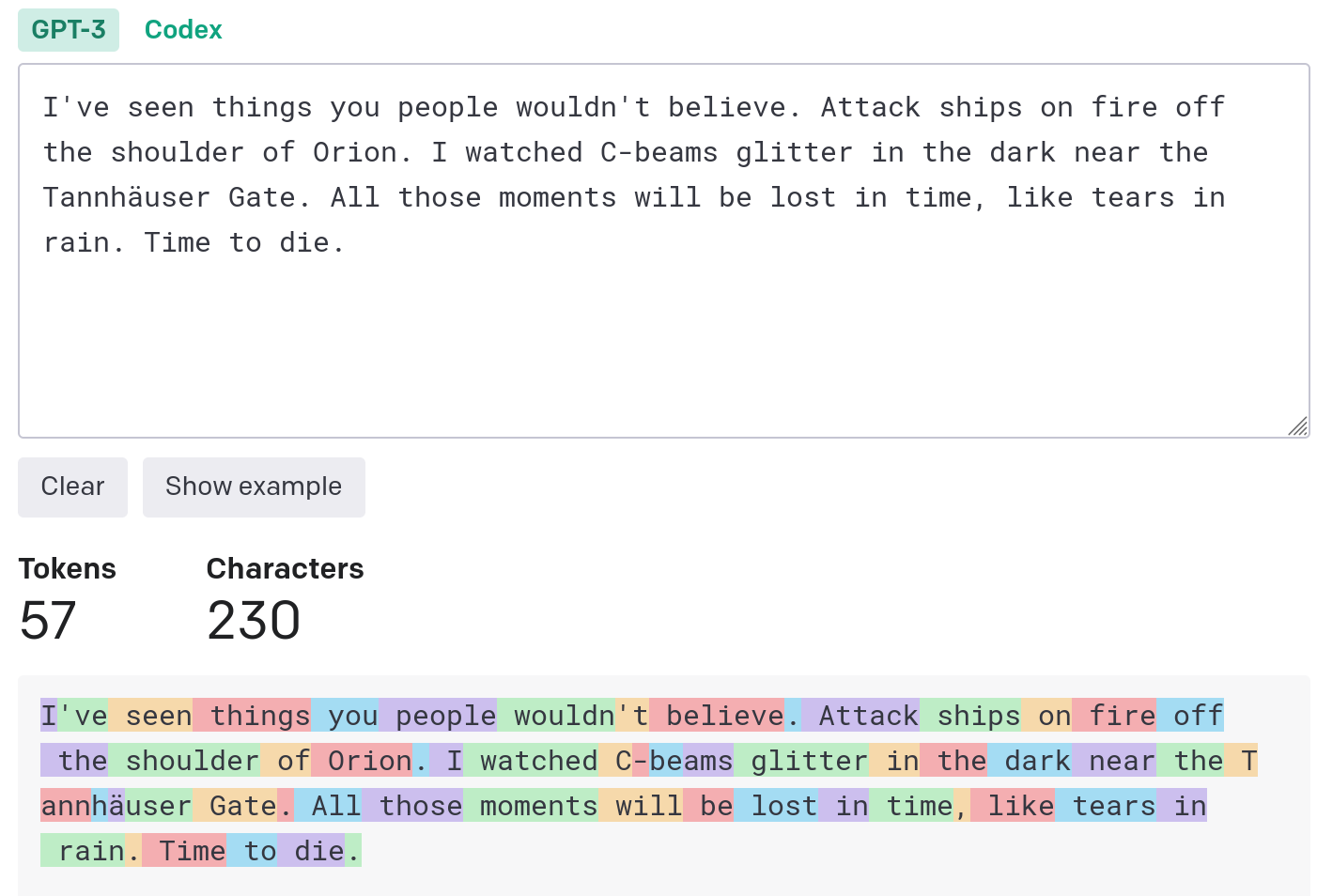
在 L2=1024 的情况下,可以得到 L1 < 4096 - 1024 = 3072。接下来的问题就是按照这个最大 token 数来对 memory.messages 进行选择了,要做这个的话,首先要能计算出给定文本的 token 数量,语言模型里的 token 不完全等于字词,OpenAI 提供了一个在线工具展示把文本变成 token 的效果:
英文基本上是一个词一个 token,有时会把一个词拆成几个 token,比如下面这个例子里 Tannhäuser 这个词就被拆成了 T/ann/h/ä/user 五个 token,但不管怎么说按字数算,英文最后的 token 数是小于字数的,下面这个例子的文本总字数是 230,token 数才 57
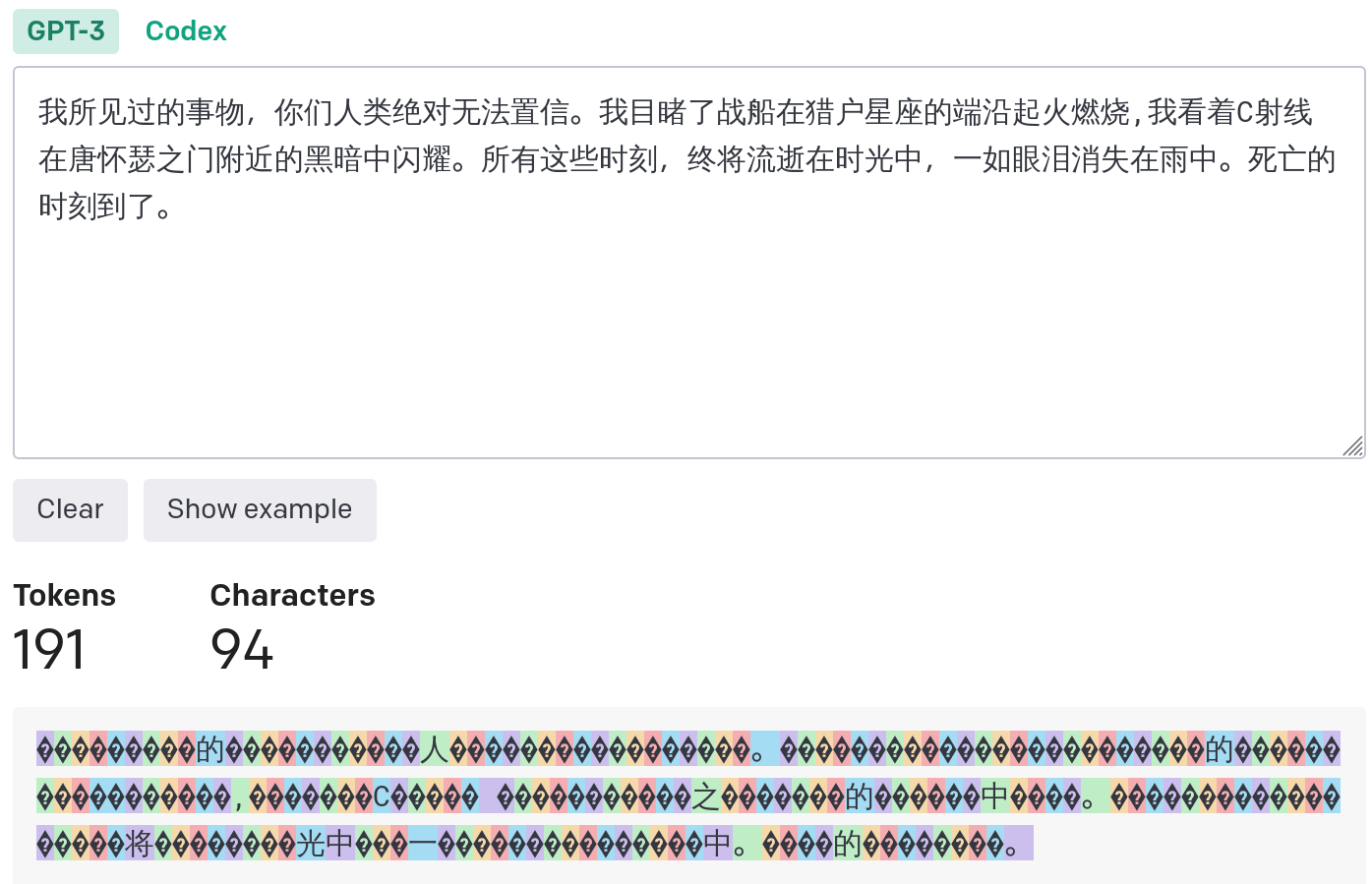
中文的话一个字就可能拆成多个 token,这些 token 大都是不可理解的,所以总体来说 token 数会大于字数,下面这个例子里的文本字数是 94,token 数是 191
注意,上面中文的例子是 GPT3 的编码器的效果,换成 gpt-3.5-turbo 的编码器后,中文的 token 数下降到了 124。
OpenAI 提供了 tiktoken 这个 python 库来做文本到 token 的编码转换
from tiktoken.model import encoding_for_model
encoder = encoding_for_model('gpt-3.5-turbo')
由于 gpt-3.5-turbo 模型使用的 Chat Completion 接口的输入不是普通的文本格式,计算输入的 token 数不能简单把用户输入和接口响应结果文本的 token 数加起来,OpenAI 自己给出了计算方法:
import tiktoken
def num_tokens_from_messages(messages, model="gpt-3.5-turbo-0301"):
"""Returns the number of tokens used by a list of messages."""
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
encoding = tiktoken.get_encoding("cl100k_base")
if model == "gpt-3.5-turbo-0301": # note: future models may deviate from this
num_tokens = 0
for message in messages:
num_tokens += 4 # every message follows <im_start>{role/name}\n{content}<im_end>\n
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name": # if there's a name, the role is omitted
num_tokens += -1 # role is always required and always 1 token
return num_tokens
else:
raise NotImplementedError(
f"num_tokens_from_messages() is not presently implemented for model {model}.\n"
"See https://github.com/openai/openai-python/blob/main/chatml.md "
"for information on how messages are converted to tokens."
)
注:为了方便计算单条消息的长度,我对 num_tokens_from_messages 做了一定的修改,删掉了 num_tokens += 2 这一行。
注2:经测试,OpenAI 提供的这个函数,计算出来的 token 数比实际的少 1 个。
基于这个函数可以来实现聊天历史的选择了,这里只简单实现一个取最近聊天历史的
from langchain.schema import AIMessage, HumanMessage
def select_messages(messages, max_total_tokens=4096, max_output_tokens=1024):
tokens_num = 0
selected = []
for message in messages[::-1]:
role = 'system'
if isinstance(message, AIMessage):
role = 'assistant'
elif isinstance(message, HumanMessage):
role = 'user'
cur_token_num = num_tokens_from_messages([{'role': role, 'content': message.content}])
if tokens_num + cur_token_num + 2 + max_output_tokens > max_total_tokens:
break
selected.append(message)
tokens_num += cur_token_num
selected = selected[::-1]
if isinstance(selected[0], AIMessage): # 确保第一条是用户消息
selected = selected[1:]
if not selected: # 假设 messages 里最后一条是当前用户输入
selected = message[-1]
return selected
那么前面的持续对话代码可以改造成这个样子了
from langchain.chat_models import ChatOpenAI
from langchain.memory import ChatMessageHistory
memory = ChatMessageHistory()
max_output_tokens, max_total_tokens = 1024, 4096
llm = ChatOpenAI(
temperature=0,
openai_api_key='sk-xxxxxxxxxxxxxxxx',
max_tokens=max_output_tokens,
)
while True:
user_message = input('You: ').strip()
if not user_message:
continue
if user_message.lower() in ('quit', 'exit'):
break
memory.add_user_message(user_message)
messages = select_messages(
memory.messages,
max_total_tokens=max_total_tokens,
max_output_tokens=max_output_tokens
)
print(f"selected messages: {messages}")
answer = llm(messages)
print('BOT:', answer.content)
memory.add_ai_message(answer.content)
把 max_output_tokens 设置得更大一些会选择更少的历史,比如说
max_output_tokens=200, max_total_tokens=4096 时,输入的最大 token 数可以到 3896,所以可以选到尽可能多的历史消息
You: 将这句话翻译成中文: “to be or not to be”
selected messages: [HumanMessage(content='将这句话翻译成中文: “to be or not to be”', additional_kwargs={}, example=False)]
BOT: "生存还是毁灭"
You: 再翻译成日语
selected messages: [HumanMessage(content='将这句话翻译成中文: “to be or not to be”', additional_kwargs={}, example=False), AIMessage(content='"生存还是毁灭"', additional_kwargs={}, example=False), HumanMessage(content='再翻译成日语', additional_kwargs={}, example=False)]
BOT: "生きるか死ぬか"
max_output_tokens=4050, max_total_tokens=4096,输入的最大 token 数只有 46,第二轮的时候没法使用前一轮的历史消息
You: 将这句话翻译成中文: “to be or not to be”
selected messages: [HumanMessage(content='将这句话翻译成中文: “to be or not to be”', additional_kwargs={}, example=False)]
BOT: "生存还是毁灭"
You: 再翻译成日语
selected messages: [HumanMessage(content='再翻译成日语', additional_kwargs={}, example=False)]
BOT: もう一度日本語に翻訳してください。
实现了聊天历史的选择后,一个最基本的原型其实就好了,进一步地,还可以为这个对话机器人做一些属性设定,比如说叫什么名字、什么性格之类的,具体的做法就是在每次调用语言模型时,除了聊天历史和当前输入,再额外输入一个描述这个机器人属性的 prompt,在 OpenAI 的接口里要求这条 prompt 的 role 设置为 system,用 langchain 的话直接用 SystemMessage 就好,我这里简单把这个 SystemMessage 放在输入的最前面,把代码改造成了这个样子:
from langchain.chat_models import ChatOpenAI
from langchain.memory import ChatMessageHistory
from langchain.schema import SystemMessage
memory = ChatMessageHistory()
system_message = SystemMessage(
content=(
"You are an AI assistant. Your name is xorius. "
"You can discuss any ideas and topics with your users, "
"and you will help your users solve their problems as much as you can."
),
)
max_total_tokens = 4096 - num_tokens_from_messages([{'role': 'system', 'content': system_message.content}])
max_output_tokens = 1024
llm = ChatOpenAI(
temperature=0,
openai_api_key='sk-xxxxxxxxxxxxxxxx',
max_tokens=max_output_tokens,
)
while True:
user_message = input('You: ').strip()
if not user_message:
continue
if user_message.lower() in ('quit', 'exit'):
break
memory.add_user_message(user_message)
messages = select_messages(
memory.messages,
max_total_tokens=max_total_tokens,
max_output_tokens=max_output_tokens
)
print(f"selected messages: {messages}")
answer = llm([system_message] + messages)
print('BOT:', answer.content)
memory.add_ai_message(answer.content)
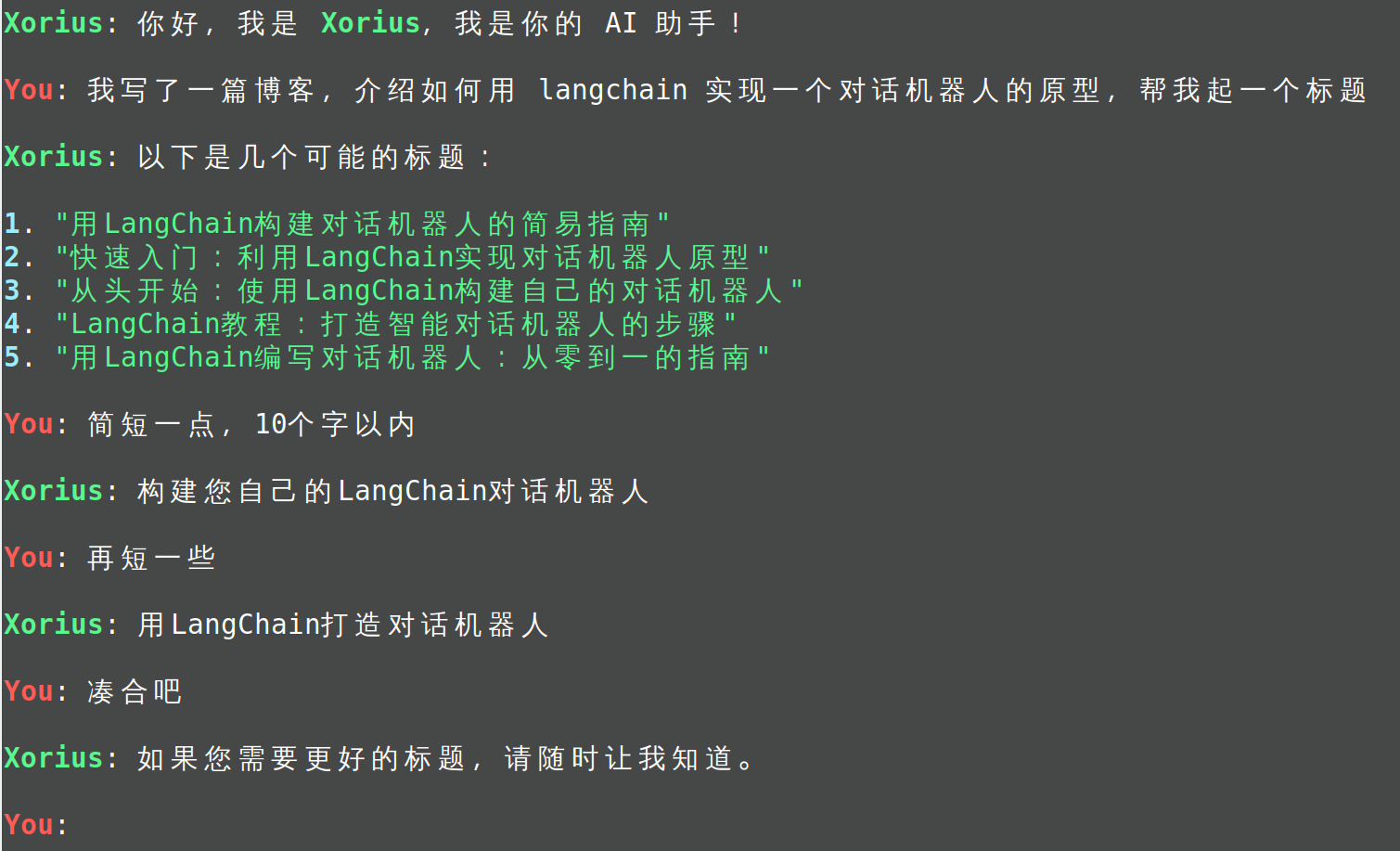
这样让它介绍自己就会按照设定来回答了
You: 介绍一下你自己
selected messages: [HumanMessage(content='介绍一下你自己', additional_kwargs={}, example=False)]
BOT: 你好,我是Xorius,一名人工智能助手。我可以与您讨论各种话题,帮助您解决问题。我可以提供有关各种主题的信息,例如科技、文化、历史、健康、旅游等等。我还可以执行各种任务,例如设置提醒、发送电子邮件、搜索信息等等。请告诉我您需要什么帮助,我会尽力为您提供支持。
如果不加这个 system_message,同样的输入得到的回答里它会强调自己由 OpenAI 开发,如下所示:
You: 介绍一下你自己
selected messages: [HumanMessage(content='介绍一下你自己', additional_kwargs={}, example=False)]
BOT: 我是一名AI语言模型,由OpenAI开发。我可以进行自然语言处理和生成,帮助用户回答问题、翻译、写作等。我没有实体,只存在于计算机中,但我可以通过文字和语音与人类进行交互。我不会感到疲倦或犯错,但我也没有情感和意识。我只是一个程序,但我希望能够为人类提供帮助和便利。
最后,我将上述代码做一些调整后实现成了项目里的一个命令行工具,代码见 https://github.com/monsternlp/xorius ,也发布到了 pypi,执行 pip install xorius 即可安装,安装后即可在命令行执行 xorius-cli 来进入对话。
命令行参数说明如下:
--api-key: 设置 OpenAI 的 API 密钥--temperature: 设置温度参数,用于控制生成结果时的随性,0 的话不随机每次都生成概率最大的结果,默认 0.7--max-tokens: 设置生成结果允许的最大 token 数,默认 512--proxy: 设置 http 代理,主要针对国内网络环境
原型是实现了,但是在这个原型上,能看到一些直接的问题
- ChatMessageHistory 是基于内存的历史消息记录方法,一旦退出历史对话消息将全部丢失
- 当讨论的话题更早之前聊过时,选择最近历史消息的做法无法利用之前的讨论
- 固定设置输出最大 token 数量的做法为了照顾长输出的情况,会导致短输出情况下无法利用更多的历史消息
- 一个全局设置的温度参数会影响机器人处理不同任务的表现,比如说像翻译、分类、事实性问答这些任务并不需要随机性,而写作、创意生成则有一定的随机性会更好一些
在当前这种模式下,将机器人属性设置放在最开始的做法无法保证设定的一致性和连续性,用户总是能通过有意构造的输入来突破这种设置
这些问题将会在之后的文章中做进一步的讨论。