Memcached 和 Redis 有什么区别,做缓存 WordPress 用哪个好?
前面介绍了使用 Memcached 内存缓存来实现 WordPress 站点秒开,但是很多人问到了 Redis,就是做缓存 Redis 和 Memcached 有什么区别,用哪个更好?今天就给大家做一个简单介绍。
Memcached 和 Redis 有什么区别
首先从模型上看,Memcached 是一个分布式内存缓存系统,专注于简单的键-值对存储,设计简单易用,它不支持复杂数据类型,而 Redis 是一个内存数据结构存储,支持更多的数据结构(如列表、集合、排序集合、哈希等),不仅仅是简单的键-值对。

所以 Memcached 是为简单的读写操作优化的,适合需要快速缓存大量数据的场景,而 Redis 提供了丰富的数据操作功能,对复杂数据操作优化良好,同时也提供了高性能的读写速度,并且 Redis 支持数据持久化,可以将内存数据保存到磁盘,Memcached 没有持久性功能,所有数据都存储在内存中,服务器重启时数据就会丢失,作为缓存这个问题不大。
此外,它们还有一点比较大的区别,就是 Memcached 支持多线程,所以支持高并发访问,而 Redis 一般使用单线程模型,虽然通过 I/O 多路复用技术提供高吞吐量,这样就比较在秒杀等场景下使用,不需要考虑并发的问题,因为单线程。
简单做个功能特性对比表格:
| 特性 | Memcached | Redis |
|---|---|---|
| 数据结构 | 仅支持键值对(String) | 支持 String、List、Hash、Set 等 |
| 持久化 | 不支持 | 支持 RDB 快照和 AOF 日志 |
| 线程模型 | 多线程(高并发读优) | 单线程(避免锁竞争,顺序执行) |
| 内存管理 | 预分配固定内存,LRU 淘汰 | 支持内存淘汰策略,可配置虚拟内存 |
| 集群模式 | 依赖客户端分片(如 Twemproxy) | 原生 Cluster 模式支持 |
| 适用场景 | 简单键值缓存(如会话、HTML片段) | 缓存、消息队列、实时统计等复杂场景 |
Redis 的作者的建议
Redis 的作者 Salvatore Sanfilippo 曾经对这两种基于内存的数据存储系统进行过比较:
- Redis 支持服务器端的数据操作:Redis 相比 Memcached 来说,拥有更多的数据结构和并支持更丰富的数据操作,通常在 Memcached 里,你需要将数据拿到客户端来进行类似的修改再 set 回去。这大大增加了网络 IO 的次数和数据体积。在 Redis 中,这些复杂的操作通常和一般的 GET/SET 一样高效。所以,如果需要缓存能够支持更复杂的结构和操作,那么 Redis 会是不错的选择。
- 内存使用效率对比:使用简单的 key-value 存储的话,Memcached 的内存利用率更高,而如果 Redis 采用 hash 结构来做 key-value 存储,由于其组合式的压缩,其内存利用率会高于 Memcached。
- 性能对比:由于 Redis 只使用单核,而 Memcached 可以使用多核,所以平均每一个核上 Redis 在存储小数据时比 Memcached 性能更高。而在 100k 以上的数据中,Memcached 性能要高于 Redis,虽然 Redis 最近也在存储大数据的性能上进行优化,但是比起 Memcached,还是稍有逊色。
总结一下:Memcached 是解决简单缓存问题的可靠选择,而 Redis 通过提供更丰富的功能和各种各样的特性而优于 Memcached,这些特性对于解决复杂的场景更有优势。
WordPress 使用哪个做缓存好?
如果单纯作为内存缓存来使用,两者其实没有什么区别,那么为什么 WPJAM Basic 为什么使用 Memcached 呢?
这里有一份 4 核 CPU / 8G 内存的服务器上的测试数据:
| 操作 | Memcached QPS | Redis QPS |
|---|---|---|
| GET 请求 | 120,000+ | 100,000+ |
| SET 请求 | 90,000+ | 80,000+ |
可以看出在 WordPress 这样简单的键-值缓存,并且需要处理大量简单数据,Memcached 是一个更好的选择。
此外我们一开始就选择了 Memcached 做 WordPress 的内存缓存的存储介质,并且在使用 Memcached 做内存缓存过程中,针对出现的各种的问题,我也做了很多的优化,比如我们在后台「WPJAM」菜单下的「系统信息」中展示「Memcached」的各种信息。

当然如果你已经使用了 Redis 做内存缓存或者更熟悉 Redis,WordPress 官方插件库也有很多第三方提供了 Redis 的 object-cache.php,和使用 Memcached 一样,只需要将对应的 object-cache.php 上传到 wp-content 目录即可。
此外也有小伙伴问,WPJAM Basic 会不会集成 Redis,让大家自己选,这个可以明确的说,目前作为简单缓存功能,Memcached 已经足够好用,不会再花时间集成 Redis。
最后还有个问题,Memcached 和 Redis 可以一起用吗?如果作为缓存,WordPress 只能选择一个,因为你上传谁的 object-cache.php,就是用谁得了。
但是不等于使用 Memcached 作为缓存,就不能使用 Redis 了,比如我们之前就利用 Redis 的一些特性做过一些开发,比如因为 Redis 单线程天然串行排队的特性,我们在花生小店秒杀的功能中就是使用 Redis 进行处理的,还有一些简单的消息队列的功能处理,也是基于 Redis 进行开发的。
简单总结
所以最后总结说一下,如果简单的 key-value 的内存缓存,建议使用 Memcached,WordPress 绝大部分站点也是使用 Memcached 进行缓存的,此外 WPJAM Basic 也对此优化得比较完善。
如果要进行复杂的程序开发,比如上面说的电商的秒杀功能 ,消息队列系统等,那么 Redis 才是发挥其长处的地方。

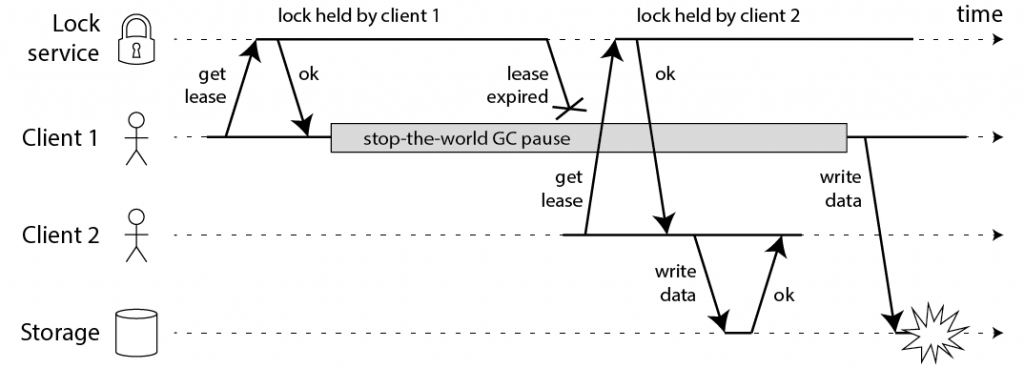
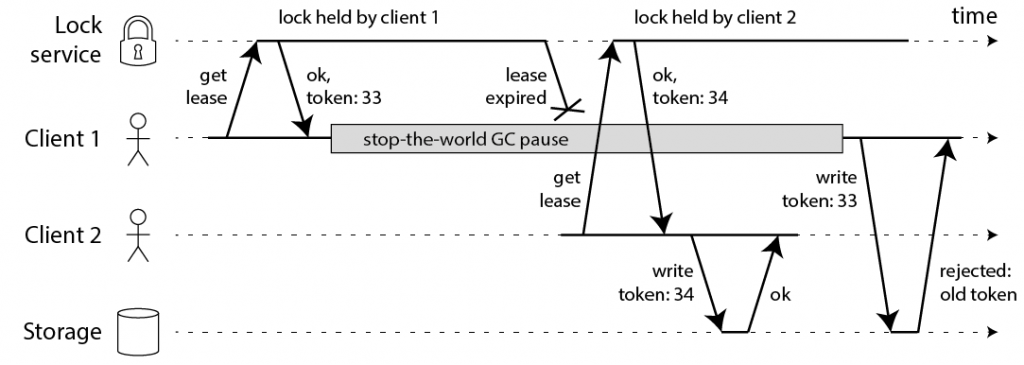
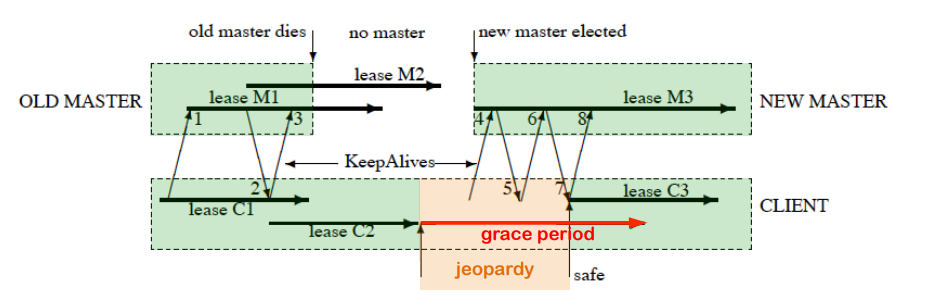
 就像 Martin Fowler 说的那样,“分布式调用的第一原则就是不要分布式”,谈分布式锁也要先说,不要使用分布式锁。原因很简单,分布式系统是软件系统中复杂的一种形式,而分布式锁是分布式系统中复杂的一种形式,没有必要的复杂性就不要引入。
就像 Martin Fowler 说的那样,“分布式调用的第一原则就是不要分布式”,谈分布式锁也要先说,不要使用分布式锁。原因很简单,分布式系统是软件系统中复杂的一种形式,而分布式锁是分布式系统中复杂的一种形式,没有必要的复杂性就不要引入。