苹果Carplay 自定义壁纸实现逻辑分析

虽然在开车的时候,多数时间不会停留在carplay的桌面。然而,当第一次切进来的时候显示的那个桌面背景图片,着实不怎么喜欢。于是就想着能够换掉这个壁纸。
网上搜了一下,基本都是一年前的文章,或者说最新的文章都是一年前的。这就比较尴尬了。
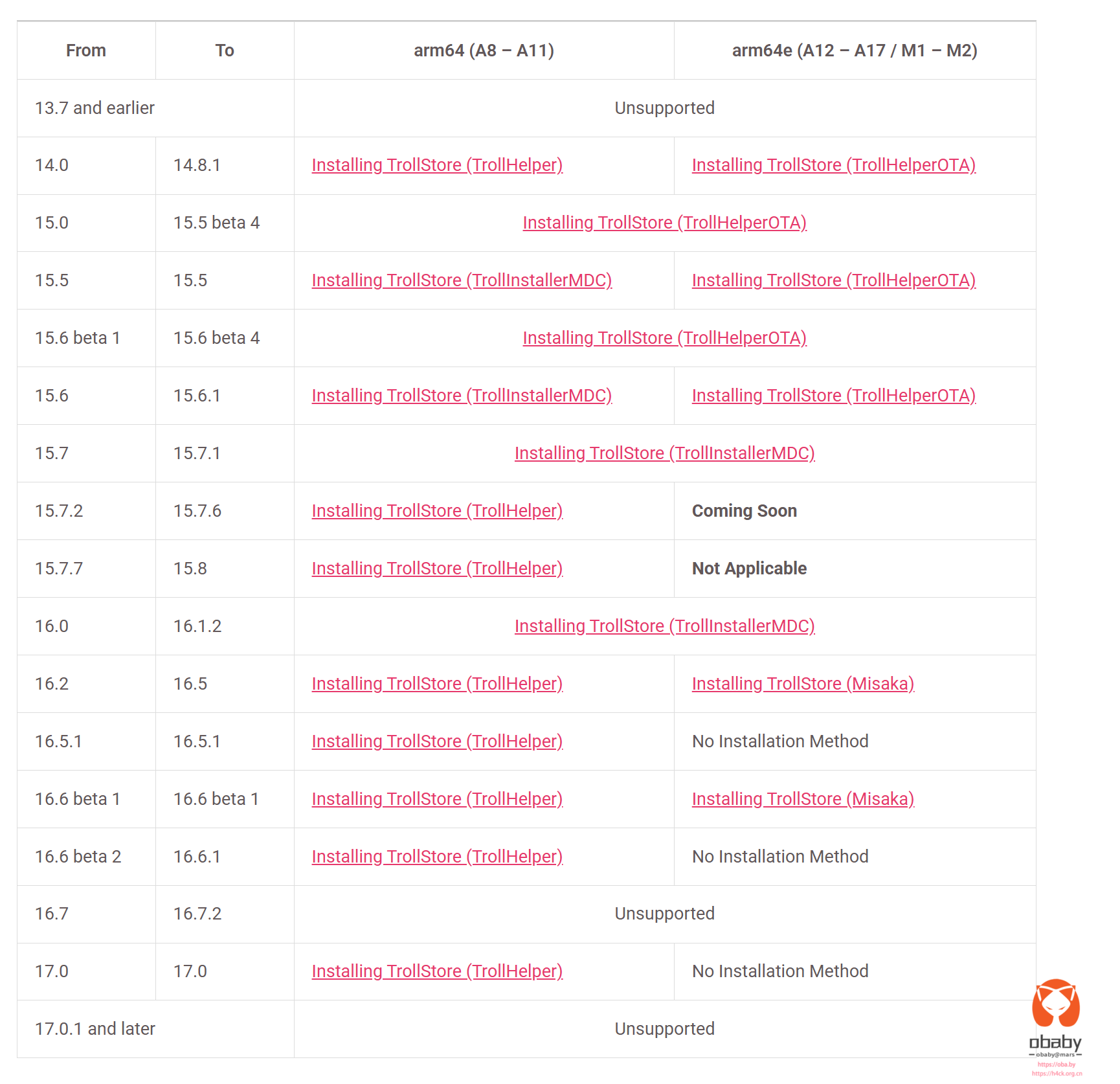
而至于实现工具和方法,到处都是抄来抄去的文章,第一步基本都是安装巨魔助手,Troll app,https://trollstore.app
这是一个越狱的应用商店。通过这个越狱的商店安装AirWall,在air wall里面设置壁纸。
https://onejailbreak.com/blog/airwall/

这一切看起来似乎完美,但是,这个troll store app 最高支持到ios 17,我现在的18没有越狱,也不想越狱。那么又该怎么搞呢?
自然是自签名,目前爱思助手之类的貌似不支持普通的appstore账号签名安装了。
不过可以通过下面的工具,签名应用然后通过爱思助手安装。
Esign iPA download and install using Sideloaly App.
Download Esign IPA:
First, download the Esign IPA file for your PC.
Download Esign iPA file.
Install Sideloadly:
Sideloadly is the tool we’ll use to install Esign on your iOS device.
If you don’t have Sideloadly yet, download and install Sideloadly app on your PC(Windows or Mac).
Connect Your Device:
Connect your iPhone or iPad to your computer using a USB cable.
Open Sideloadly:
Launch the Sideloadly application on your computer.
Select the IPA File:
In Sideloadly, click on the IPA icon to select the Esign IPA file you downloaded earlier.
Sign the IPA File:
Enter your Apple ID and password when prompted. This step is necessary for signing the IPA file.
Start Installation:
Click the Start button in Sideloadly to begin the installation process.
Sideloadly will sign the Esign IPA file and install it on your iOS device.
Check Your Home Screen:
Once the process is complete, you’ll find the Esign app icon on your home screen.
Then go to Settings App → General → Profiles & Device Management → Find the Esign app profile and trust it.
You can now use Esign to sign and install other IPA files directly on your device.
然而,签名安装之后却发现了另外一个问题,那就是卡在了加载界面。一直在获取目录,后面就进行不下去了。
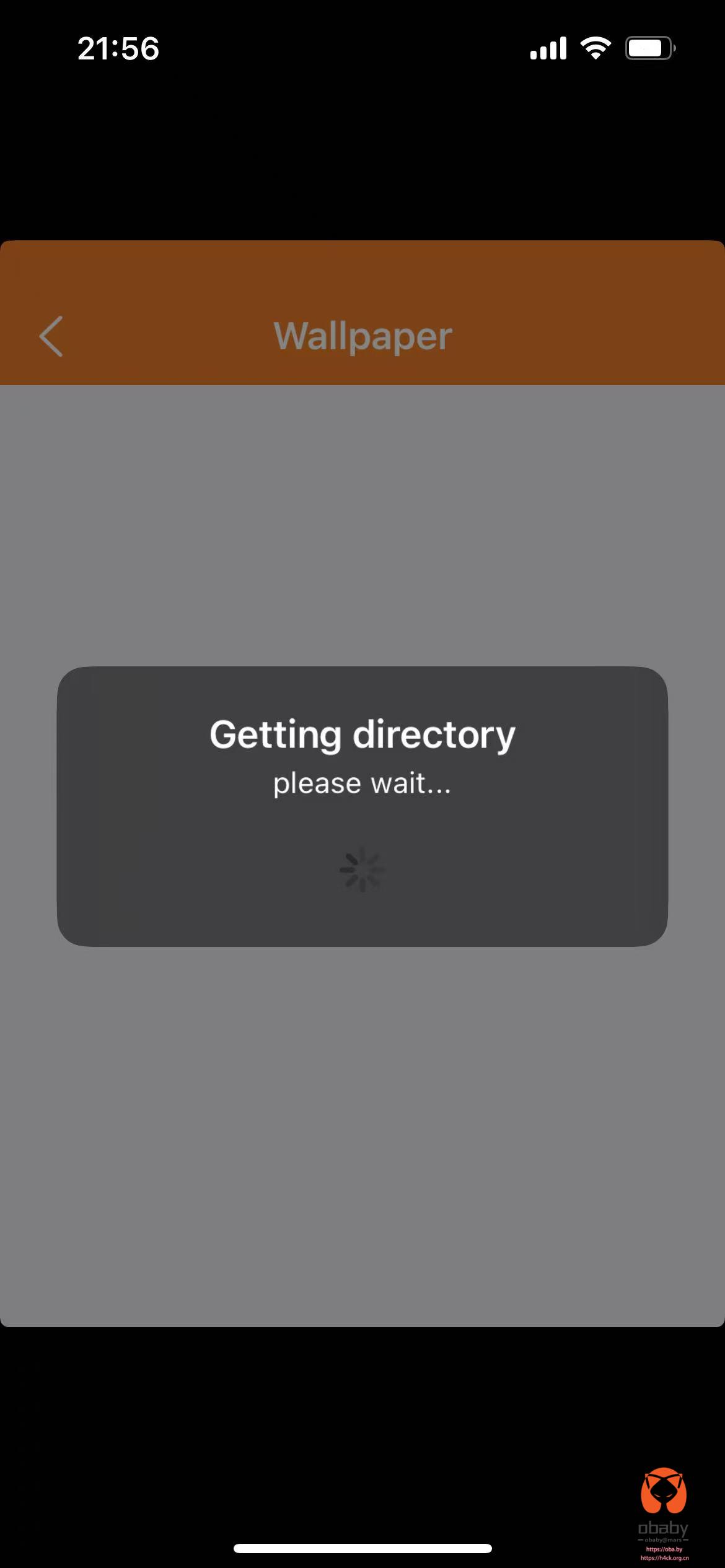
上网搜了一下,好无进展,都是说什么连接carplay之后在设置,然而,这就是句废话。连上了也没什么用。
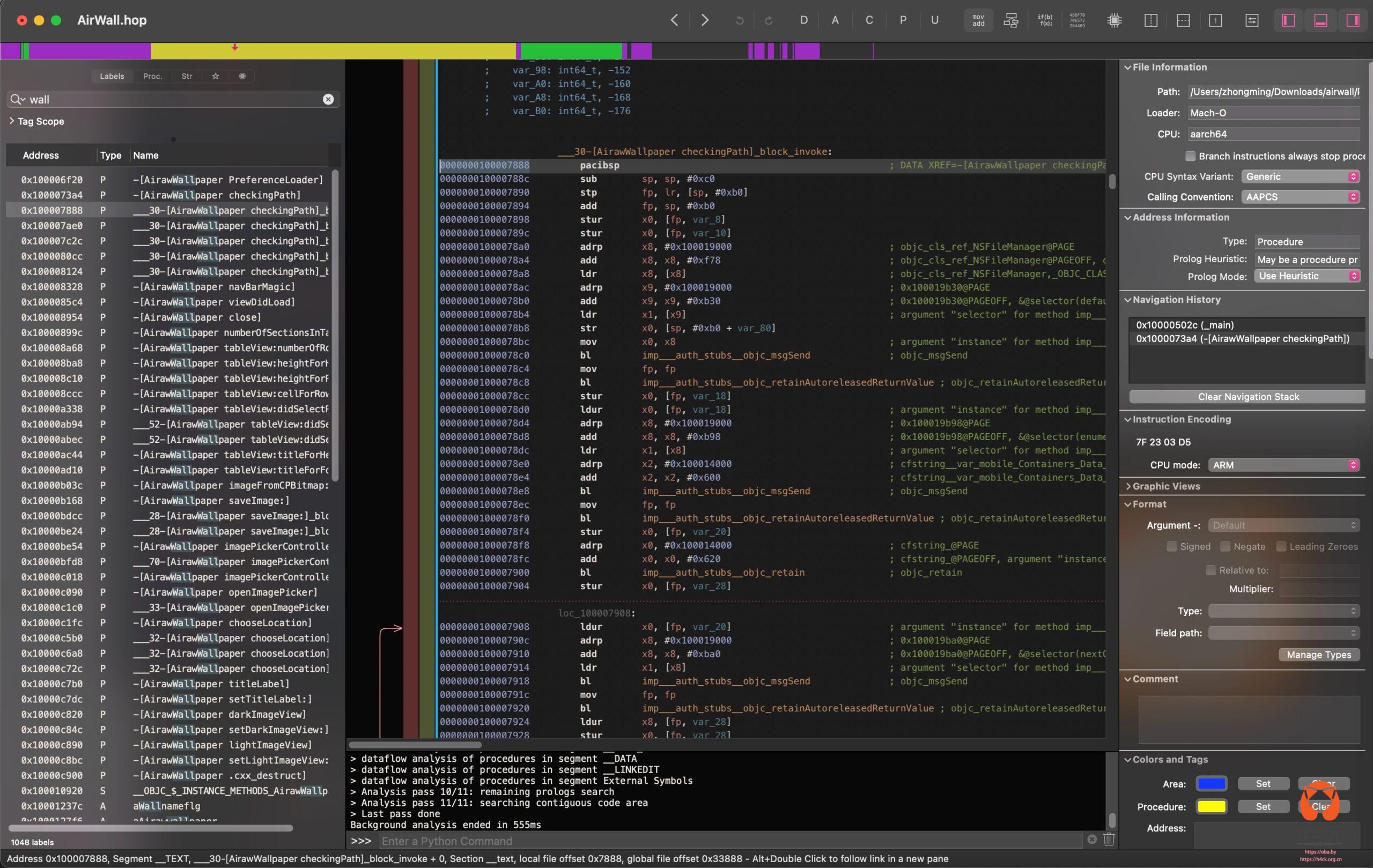
不过,这个app体积不大,直接拉出来。扔到hopper里面看下实现逻辑,也并不复杂。
直接通过目录来获取的当前壁纸,同样替换壁纸也是直接写入文件实现的。
看F5之后的代码就更直观了。
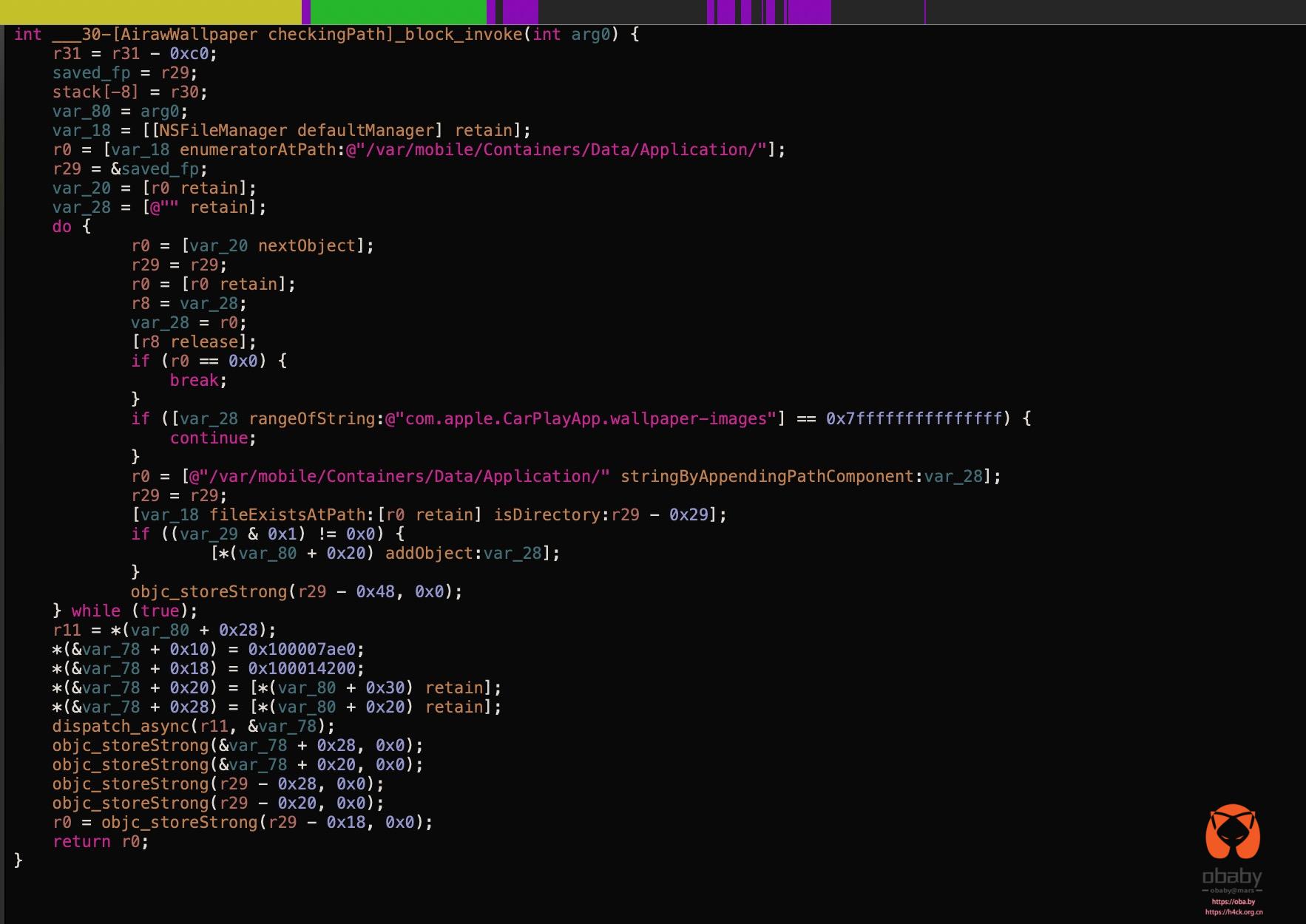
导出代码,直接扔给cursor,让cursor根据f5代码拆分重构代码。
现在代码逻辑就明朗了,更换壁纸的方法主要在AirawWallpaper.m中:
#pragma mark - Helper Methods
- (void)checkingPath {
// 检查壁纸路径
NSFileManager *fileManager = [NSFileManager defaultManager];
NSString *basePath = @"/var/mobile/Containers/Data/Application/";
// 检查是否有权限访问
if (![fileManager isWritableFileAtPath:basePath]) {
UIAlertController *alert = [UIAlertController alertControllerWithTitle:@"权限错误"
message:@"无法访问系统目录,请确保设备已越狱并授予了正确的权限。"
preferredStyle:UIAlertControllerStyleAlert];
[alert addAction:[UIAlertAction actionWithTitle:@"确定" style:UIAlertActionStyleDefault handler:nil]];
[self presentViewController:alert animated:YES completion:nil];
return;
}
NSError *error = nil;
NSArray *contents = [fileManager contentsOfDirectoryAtPath:basePath error:&error];
if (error) {
NSLog(@"Error reading directory: %@", error);
return;
}
NSMutableArray *validPaths = [NSMutableArray array];
for (NSString *path in contents) {
if ([path containsString:@"com.apple.CarPlayApp.wallpaper-images"]) {
NSString *fullPath = [basePath stringByAppendingPathComponent:path];
BOOL isDirectory;
if ([fileManager fileExistsAtPath:fullPath isDirectory:&isDirectory] && isDirectory) {
[validPaths addObject:path];
}
}
}
if (validPaths.count > 0) {
self.FullCache = [basePath stringByAppendingPathComponent:validPaths[0]];
[self.tableView reloadData];
} else {
UIAlertController *alert = [UIAlertController alertControllerWithTitle:@"错误"
message:@"未找到 CarPlay 壁纸目录,请确保已正确安装 CarPlay 应用。"
preferredStyle:UIAlertControllerStyleAlert];
[alert addAction:[UIAlertAction actionWithTitle:@"确定" style:UIAlertActionStyleDefault handler:nil]];
[self presentViewController:alert animated:YES completion:nil];
}
}
当然,上面这段代码的错误提示是我让cursor加上的。原来的并没有这段,这个是f5的代码:
int ___30-[AirawWallpaper checkingPath]_block_invoke(int arg0) {
r31 = r31 - 0xc0;
saved_fp = r29;
stack[-8] = r30;
var_80 = arg0;
var_18 = [[NSFileManager defaultManager] retain];
r0 = [var_18 enumeratorAtPath:@"/var/mobile/Containers/Data/Application/"];
r29 = &saved_fp;
var_20 = [r0 retain];
var_28 = [@"" retain];
do {
r0 = [var_20 nextObject];
r29 = r29;
r0 = [r0 retain];
r8 = var_28;
var_28 = r0;
[r8 release];
if (r0 == 0x0) {
break;
}
if ([var_28 rangeOfString:@"com.apple.CarPlayApp.wallpaper-images"] == 0x7fffffffffffffff) {
continue;
}
r0 = [@"/var/mobile/Containers/Data/Application/" stringByAppendingPathComponent:var_28];
r29 = r29;
[var_18 fileExistsAtPath:[r0 retain] isDirectory:r29 - 0x29];
if ((var_29 & 0x1) != 0x0) {
[*(var_80 + 0x20) addObject:var_28];
}
objc_storeStrong(r29 - 0x48, 0x0);
} while (true);
r11 = *(var_80 + 0x28);
*(&var_78 + 0x10) = 0x100007ae0;
*(&var_78 + 0x18) = 0x100014200;
*(&var_78 + 0x20) = [*(var_80 + 0x30) retain];
*(&var_78 + 0x28) = [*(var_80 + 0x20) retain];
dispatch_async(r11, &var_78);
objc_storeStrong(&var_78 + 0x28, 0x0);
objc_storeStrong(&var_78 + 0x20, 0x0);
objc_storeStrong(r29 - 0x28, 0x0);
objc_storeStrong(r29 - 0x20, 0x0);
r0 = objc_storeStrong(r29 - 0x18, 0x0);
return r0;
}
不过现在,也能看出问题出在什么地方了。/var/mobile/Containers/Data/Application/这个目录,普通的app是没有足够的全项访问的。需要申请特殊的权限,直接让cursor创建权限申请的Entitlements:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<!-- 基本权限 -->
<key>application-identifier</key>
<string>49U329UV5Q.by.oba.airwall</string>
<key>com.apple.developer.team-identifier</key>
<string>49U329UV5Q</string>
<key>get-task-allow</key>
<true/>
<key>keychain-access-groups</key>
<array>
<string>49U329UV5Q.*</string>
<string>com.apple.token</string>
</array>
<!-- 容器访问权限 (私有API) -->
<key>com.apple.private.security.container-manager</key>
<true/>
<key>com.apple.private.security.disk-device-access</key>
<true/>
<key>com.apple.private.security.system-container</key>
<true/>
<!-- 文件系统完全访问 -->
<key>com.apple.private.security.no-container</key>
<true/>
<key>com.apple.private.security.no-sandbox</key>
<true/>
<!-- TCC绕过权限 -->
<key>com.apple.private.tcc.allow</key>
<array>
<string>kTCCServiceSystemPolicyAllFiles</string>
<string>kTCCServiceSystemPolicyDesktopFolder</string>
<string>kTCCServiceSystemPolicyDocumentsFolder</string>
<string>kTCCServiceSystemPolicyDownloadsFolder</string>
<string>kTCCServiceAppleEvents</string>
</array>
<!-- 根权限访问 -->
<key>com.apple.private.security.storage.SystemPolicyAllFiles</key>
<true/>
<!-- 平台应用权限 -->
<key>platform-application</key>
<true/>
<!-- 跳过验证 -->
<key>com.apple.private.skip-library-validation</key>
<true/>
<!-- 任务访问权限 -->
<key>task_for_pid-allow</key>
<true/>
<!-- 进程调试权限 -->
<key>com.apple.system-task-ports</key>
<true/>
<!-- 网络权限 -->
<key>com.apple.security.network.client</key>
<true/>
<key>com.apple.security.network.server</key>
<true/>
</dict>
</plist>
既然添加了自定义的权限,那么使用这些签名工具就没办法写入权限文件了,需要自己来实现签名,具体的实现方法可以参考:
iOS 签名杂谈(一):https://h4ck.org.cn/2020/06/7112
iOS 签名杂谈(二): https://h4ck.org.cn/2020/06/7130
虽然之前做个一个签名的图形界面工具,但是引入了一个库不支持arm架构,也懒得再更新了。现在就只能创建签名脚本签名了,来回修改多次之后,让cursor创建了一个自签名脚本,sign_with_args.sh。通过这个东西就可以快速签名文件了。
签名脚本代码:
#!/bin/bash
# 变量声明(无默认值)
MOBILEPROVISION=""
APP_PATH=""
CERTIFICATE=""
BUNDLE_ID=""
TEAM_ID=""
DEVICE_UDID=""
ENTITLEMENTS_FILE="" # 新增:自定义 Entitlements 文件路径
# 显示帮助信息
show_help() {
echo "用法: $0 [选项]"
echo "选项:"
echo " -p, --provision mobileprovision文件路径 (必需)"
echo " -a, --app-path 应用路径 (必需)"
echo " -c, --certificate 证书名称 (必需)"
echo " -b, --bundle-id Bundle ID (必需)"
echo " -t, --team-id Team ID (必需)"
echo " -d, --device-udid 设备UDID (必需)"
echo " -e, --entitlements Entitlements文件路径 (可选,默认从mobileprovision提取)"
echo " -h, --help 显示此帮助信息"
exit 0
}
# 检查必需参数
check_required_params() {
local missing=0
if [ -z "$MOBILEPROVISION" ]; then
echo "错误: 缺少 mobileprovision 文件路径 (-p)"
missing=1
fi
if [ -z "$APP_PATH" ]; then
echo "错误: 缺少应用路径 (-a)"
missing=1
fi
if [ -z "$CERTIFICATE" ]; then
echo "错误: 缺少证书名称 (-c)"
missing=1
fi
if [ -z "$BUNDLE_ID" ]; then
echo "错误: 缺少 Bundle ID (-b)"
missing=1
fi
if [ -z "$TEAM_ID" ]; then
echo "错误: 缺少 Team ID (-t)"
missing=1
fi
if [ -z "$DEVICE_UDID" ]; then
echo "错误: 缺少设备 UDID (-d)"
missing=1
fi
if [ $missing -eq 1 ]; then
echo "请使用 -h 或 --help 查看帮助信息"
exit 1
fi
}
# 解析命令行参数
while [[ $# -gt 0 ]]; do
case $1 in
-p|--provision)
MOBILEPROVISION="$2"
shift 2
;;
-a|--app-path)
APP_PATH="$2"
shift 2
;;
-c|--certificate)
CERTIFICATE="$2"
shift 2
;;
-b|--bundle-id)
BUNDLE_ID="$2"
shift 2
;;
-t|--team-id)
TEAM_ID="$2"
shift 2
;;
-d|--device-udid)
DEVICE_UDID="$2"
shift 2
;;
-e|--entitlements)
ENTITLEMENTS_FILE="$2"
shift 2
;;
-h|--help)
show_help
;;
*)
echo "未知选项: $1"
show_help
;;
esac
done
# 检查必需参数
check_required_params
# 清理函数
cleanup() {
echo "清理临时文件..."
rm -f temp_entitlements.plist
}
# 错误处理
handle_error() {
echo "错误: $1"
cleanup
exit 1
}
# 检查文件是否存在
if [ ! -f "$MOBILEPROVISION" ]; then
handle_error "mobileprovision 文件不存在: $MOBILEPROVISION"
fi
# 检查目录是否存在
if [ ! -d "$APP_PATH" ]; then
handle_error "应用目录不存在: $APP_PATH"
fi
# 如果提供了自定义 Entitlements 文件,检查其是否存在
if [ ! -z "$ENTITLEMENTS_FILE" ] && [ ! -f "$ENTITLEMENTS_FILE" ]; then
handle_error "Entitlements 文件不存在: $ENTITLEMENTS_FILE"
fi
# 验证配置文件
echo "验证配置文件..."
PROFILE_INFO=$(security cms -D -i "$MOBILEPROVISION")
if [ $? -ne 0 ]; then
handle_error "配置文件无效"
fi
# 提取信息
echo "正在从 mobileprovision 提取信息..."
PROFILE_TEAM_ID=$(echo "$PROFILE_INFO" | plutil -extract TeamIdentifier.0 raw -)
PROFILE_APP_ID=$(echo "$PROFILE_INFO" | plutil -extract Entitlements.application-identifier raw -)
PROFILE_EXPIRATION=$(echo "$PROFILE_INFO" | plutil -extract ExpirationDate raw -)
echo "Profile Team ID: $PROFILE_TEAM_ID"
echo "Profile Application ID: $PROFILE_APP_ID"
echo "Profile Expiration: $PROFILE_EXPIRATION"
# 验证 Team ID
if [ "$PROFILE_TEAM_ID" != "$TEAM_ID" ]; then
echo "警告: Team ID 不匹配"
echo "Profile中的: $PROFILE_TEAM_ID"
echo "设置的: $TEAM_ID"
handle_error "请确保使用正确的 mobileprovision 文件"
fi
# 验证设备 UDID
echo "验证设备 UDID..."
if ! security cms -D -i "$MOBILEPROVISION" | grep -A 20 ProvisionedDevices | grep -q "$DEVICE_UDID"; then
echo "错误: 设备 UDID $DEVICE_UDID 未包含在 provisioning profile 中"
echo "包含的设备:"
security cms -D -i "$MOBILEPROVISION" | grep -A 20 ProvisionedDevices
handle_error "设备未授权"
fi
echo "设备 UDID 验证通过: $DEVICE_UDID"
# 设置完整的 Bundle ID
FULL_BUNDLE_ID="$PROFILE_APP_ID"
echo "使用 Bundle ID: $FULL_BUNDLE_ID"
# 清理旧的签名
echo "清理旧的签名..."
rm -rf "$APP_PATH/_CodeSignature" 2>/dev/null
# 复制 mobileprovision 并设置权限
echo "复制 mobileprovision..."
cp "$MOBILEPROVISION" "$APP_PATH/embedded.mobileprovision"
chmod 644 "$APP_PATH/embedded.mobileprovision"
# 处理 Entitlements
if [ ! -z "$ENTITLEMENTS_FILE" ]; then
echo "使用自定义 Entitlements 文件: $ENTITLEMENTS_FILE"
cp "$ENTITLEMENTS_FILE" temp_entitlements.plist
else
echo "从 mobileprovision 提取 Entitlements..."
security cms -D -i "$MOBILEPROVISION" | plutil -extract Entitlements xml1 -o - - > temp_entitlements.plist
fi
# 显示 entitlements 内容
echo "Entitlements 内容:"
plutil -p temp_entitlements.plist
# 设置正确的文件权限
echo "设置文件权限..."
chmod -R 755 "$APP_PATH"
find "$APP_PATH" -type f -exec chmod 644 {} \;
find "$APP_PATH" -name "*.dylib" -exec chmod 755 {} \;
[ -f "$APP_PATH/AirWall" ] && chmod 755 "$APP_PATH/AirWall"
[ -f "$APP_PATH/AirWallHelper" ] && chmod 755 "$APP_PATH/AirWallHelper"
[ -f "$APP_PATH/trollstorehelper" ] && chmod 755 "$APP_PATH/trollstorehelper"
# 移除空文件(特别是0字节的PNG文件)
echo "移除空文件..."
find "$APP_PATH" -type f -size 0 -delete
echo "已移除空文件"
# 修正Info.plist中的Bundle ID
echo "修正Info.plist中的Bundle ID..."
plutil -replace CFBundleIdentifier -string "$PROFILE_APP_ID" "$APP_PATH/Info.plist"
echo "Bundle ID已设置为: $(plutil -extract CFBundleIdentifier raw "$APP_PATH/Info.plist")"
# 对可执行文件进行签名
echo "对可执行文件进行签名..."
if [ -f "$APP_PATH/AirWallHelper" ]; then
echo "签名 AirWallHelper..."
codesign -f -s "$CERTIFICATE" --entitlements temp_entitlements.plist "$APP_PATH/AirWallHelper" || handle_error "AirWallHelper 签名失败"
fi
if [ -f "$APP_PATH/trollstorehelper" ]; then
echo "签名 trollstorehelper..."
codesign -f -s "$CERTIFICATE" --entitlements temp_entitlements.plist "$APP_PATH/trollstorehelper" || handle_error "trollstorehelper 签名失败"
fi
# 对所有的 frameworks 和 dylibs 进行签名
echo "签名 frameworks 和 dylibs..."
find "$APP_PATH" -name "*.framework" -o -name "*.dylib" | while read -r file; do
echo "签名: $file"
codesign -f -s "$CERTIFICATE" "$file" || handle_error "Framework/dylib 签名失败: $file"
done
# 对整个应用进行签名
echo "对整个应用进行签名..."
codesign -f -s "$CERTIFICATE" --entitlements temp_entitlements.plist --deep "$APP_PATH" || handle_error "应用签名失败"
# 验证签名
echo "验证签名..."
codesign -vv -d "$APP_PATH"
# 检查_CodeSignature目录
echo "检查_CodeSignature目录..."
if [ -d "$APP_PATH/_CodeSignature" ]; then
echo "✓ _CodeSignature 目录存在"
ls -la "$APP_PATH/_CodeSignature/"
else
echo " _CodeSignature 目录不存在,这可能导致安装失败"
fi
# 显示更多签名信息
echo "显示详细签名信息..."
codesign -d --entitlements :- "$APP_PATH"
# 验证所有签名
echo "验证所有签名..."
if codesign --verify --deep --strict --verbose=4 "$APP_PATH"; then
echo "✓ 严格验证通过"
else
echo " 严格验证失败,但基本签名可能仍然有效"
fi
# 清理临时文件
cleanup
# 重新打包
echo "重新打包..."
rm -f signed_AirWall.ipa
zip -qry signed_AirWall.ipa Payload
echo "签名完成!"
_CodeSignature 目录不存在,这可能导致安装失败"
fi
# 显示更多签名信息
echo "显示详细签名信息..."
codesign -d --entitlements :- "$APP_PATH"
# 验证所有签名
echo "验证所有签名..."
if codesign --verify --deep --strict --verbose=4 "$APP_PATH"; then
echo "✓ 严格验证通过"
else
echo " 严格验证失败,但基本签名可能仍然有效"
fi
# 清理临时文件
cleanup
# 重新打包
echo "重新打包..."
rm -f signed_AirWall.ipa
zip -qry signed_AirWall.ipa Payload
echo "签名完成!"
然而,在测试的时候发现com.apple.private私有权限,签名之后安装全部被拒绝了。那么,也就是说目前是没办法在非越狱系统访问这个文件的,自然也就没法更改壁纸。
原来是想把代码开源的,结果上传之后把自己的证书也放进去了。所以就没发开园啦,主要原理也说了,结论就是,目前不越狱是没办法修改carplay的壁纸的,所以可以不用尝试了。
附视频链接:
The post 苹果Carplay 自定义壁纸实现逻辑分析 appeared first on obaby@mars.





























































































































{kind=link}