Spark-TTS是什么?基于 Qwen2.5 的下一代文本转语音系统
Spark-TTS 是什么
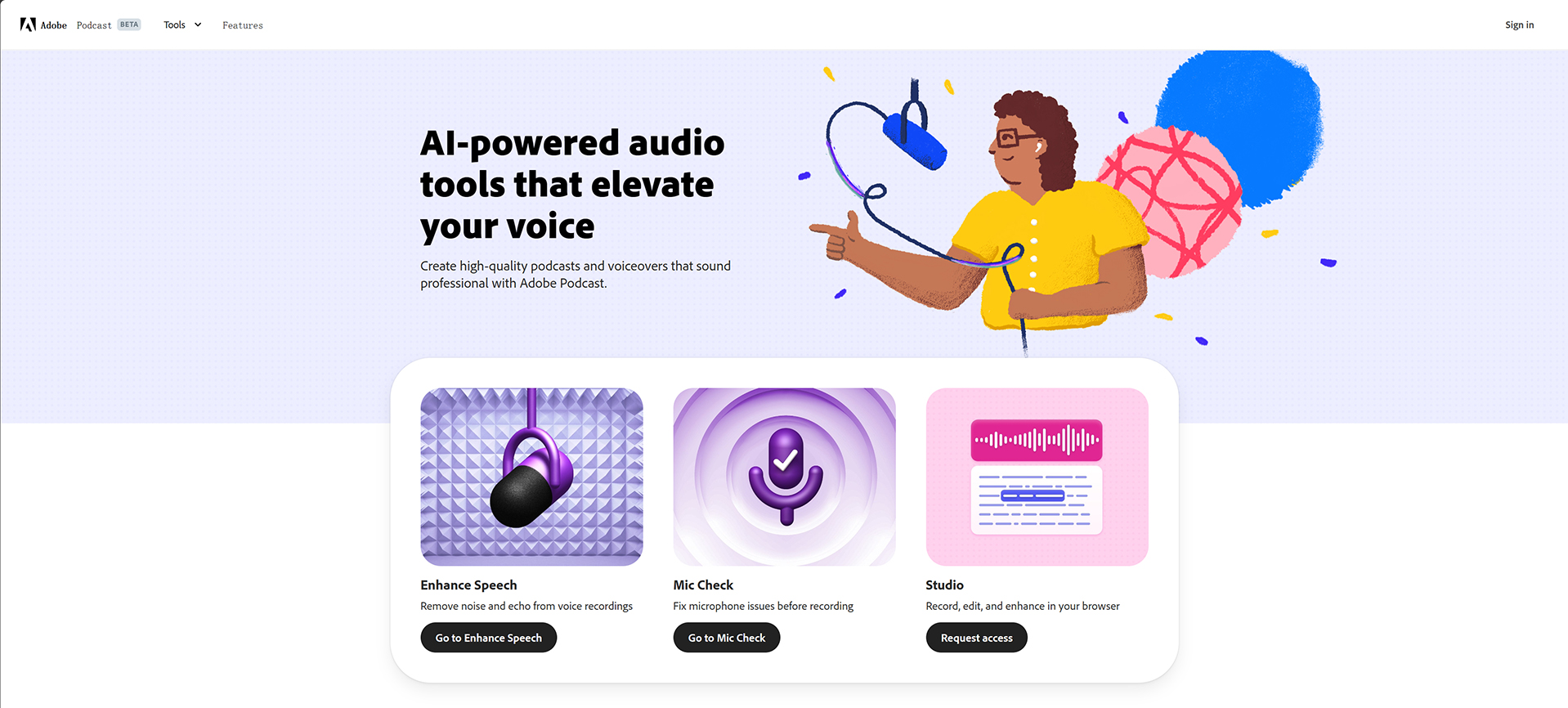
Spark-TTS 是一种先进的文本到语音系统,它利用大型语言模型(Qwen2.5 LLM)的强大功能实现高度准确和自然的语音合成。该系统设计高效、灵活、功能强大,既可用于研究,也可用于生产。
![]()
Spark-TTS 开源地址及体验地址
- Hugging Face:SparkAudio/Spark-TTS-0.5B
- Github:SparkAudio/Spark-TTS
- Hugging Face 在线体验地址:Spark TTS
- 项目演示地址:Spark-TTS
主要功能
- 简单高效:Spark-TTS 完全基于 Qwen2.5 构建,无需额外的生成模型(如流匹配)。它不依赖单独的模型来生成声音特征,而是直接从 LLM 预测的代码中重建音频。这种方法简化了流程,提高了效率,降低了复杂性。
- 高质量语音克隆:支持零镜头语音克隆,这意味着即使没有特定的语音训练数据,它也能复制说话者的语音。这非常适合跨语言和代码转换场景,可实现语言和语音之间的无缝转换,而无需对每种语言和语音进行单独培训。
- 双语支持:支持中英文两种语言,并能针对跨语言和代码转换场景进行零镜头语音克隆,使模型能以高自然度和准确度合成多语言语音。
- 可控语音生成:通过调整性别、音调和语速等参数,支持创建虚拟发言人。
![]()
Spark-TTS的创新点
-
基于Qwen2.5大模型的一体化架构
Spark-TTS完全基于Qwen2.5大型语言模型构建,无需依赖传统TTS系统中的声学模型或流匹配模型。通过直接从LLM预测的代码重建音频,简化了语音合成的流程,显著提升了效率并降低了系统复杂性。 -
BiCodec编码技术
首创BiCodec单流语音编码器,将语音分解为两类核心标记:
• 语义标记:以超低码率(50 tokens/秒)捕捉语言内容;
• 全局标记:固定长度编码说话人属性(如音色、语调、性别)。
这种设计实现了语音内容与风格的解耦,支持灵活组合,推理速度提升30%以上。 -
零样本语音克隆
仅需3秒参考音频即可复现说话人音色,无需针对特定语音进行训练。该功能突破了传统技术对大量训练数据的依赖,支持跨语言和代码切换场景,音色一致性(SIM)指标超越同类模型。 -
细粒度语音控制
提供多层级参数调节:
- 粗粒度:一键切换性别、情感风格;
- 细粒度:精准调整音高(如A4=440Hz)、语速(每秒音节数)、停顿时长等。 用户甚至可通过文本描述(如“沉稳中年男声,语速加快20%”)生成虚拟音色。
-
VoxBox数据集支持
基于10万小时开源语音数据集VoxBox训练,涵盖多语言、多场景语音,并标注性别、音高、语速等精细属性,为模型的高可控性和自然度提供数据基础。
Spark-TTS解决的问题
-
传统TTS系统架构复杂
传统方法需多阶段处理(文本编码、声学模型、音频合成),效率低下且难以集成到LLM生态。Spark-TTS通过端到端生成架构,直接由LLM完成语音合成,减少计算开销。
-
代码本预测困难
传统TTS依赖多流(multi-stream)代码预测,需多个模型协作,导致推理复杂度高。BiCodec的单流编码设计简化了这一流程,降低计算资源需求。
-
语音控制能力有限
传统方法难以精准调节音高、语速等参数,且多依赖参考音频模拟。Spark-TTS通过参数化控制与文本描述生成,实现从“情感风格”到“逐句微调”的全面可控性。
-
跨语言支持不足
传统模型需针对不同语言单独训练。Spark-TTS支持中英文无缝切换,输入中文可生成英文语音(反之亦然),且能自然处理数字、混合文本的断句问题,满足全球化场景需求。
好,我现在要整理用户提供的关于Spark-TTS的使用教程。用户给了很多搜索结果,我需要从中提取关键步骤和注意事项。首先看网页1和网页2,都是关于克隆仓库、安装Conda环境、安装依赖项、下载模型,然后运行推理或启动Web UI。网页3和6也提到了类似的步骤,可能是一些重复的信息。网页4和9讨论了在Mac和Windows上的部署,特别是Windows用户需要处理CUDA和PyTorch的安装,还有可能遇到的环境变量问题。网页8提到了在Windows安装时遇到的libiomp5md.dll冲突,解决方法需要删除该文件或者设置环境变量。网页5和7是关于云端部署,可能用户想本地部署的话这部分暂时不用考虑。网页10的内容似乎和Spark-TTS无关,是关于Apache Spark的,所以忽略。
接下来需要综合这些信息,整理出一个结构化的使用教程。可能分为环境准备、安装步骤、模型下载、运行推理、Web UI启动、问题解决等部分。需要注意的是不同操作系统下的差异,比如Windows可能需要额外处理CUDA和PyTorch版本,而Mac可能需要修改代码使用CPU模式。另外,国内用户可能需要使用镜像源加速安装,这也是一个重点。零样本克隆和参数调节功能在多个网页中被提到,应该作为使用示例和高级功能来介绍。最后,常见问题如依赖冲突、端口访问问题、克隆效果不佳的注意事项也需要总结。
Spark-TTS 使用教程
一、环境准备
- 系统要求
- 操作系统:支持 Windows 10/11、Linux、macOS(M1/M2/M4 芯片需调整代码适配 CPU/MPS)
- Python 版本:需 Python 3.12 或更高
- 硬件要求:
- 内存:至少 8GB,推荐 16GB 以上
- GPU(可选):NVIDIA GPU(显存 ≥4GB)可加速推理,CPU 也可运行但速度较慢
- 依赖工具安装
- Git 和 Git LFS:用于克隆仓库和下载大模型文件
- Conda:推荐使用 Conda 管理虚拟环境,避免依赖冲突
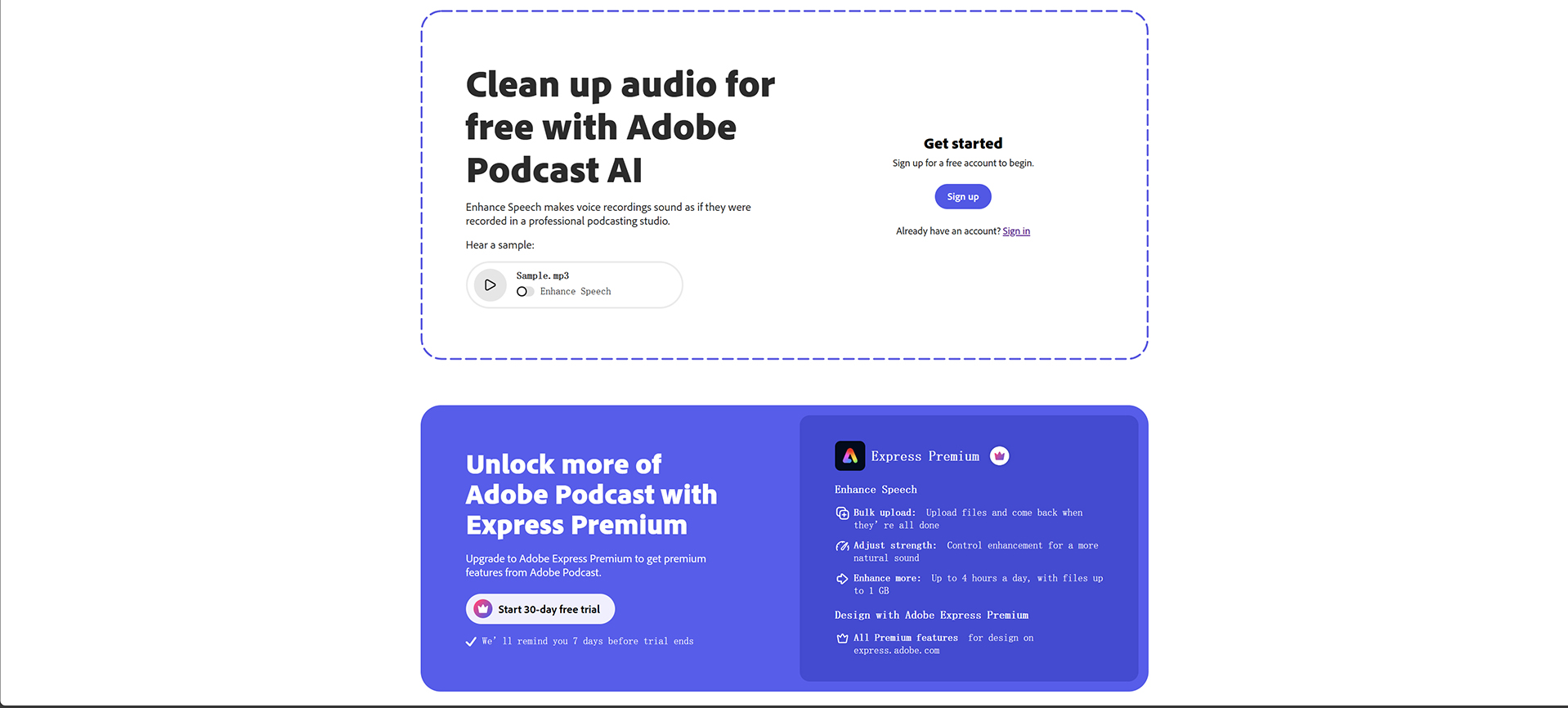
二、安装步骤
-
克隆仓库
git clone https://github.com/SparkAudio/Spark-TTS.git cd Spark-TTS -
创建并激活 Conda 环境
conda create -n sparktts -y python=3.12 conda activate sparktts -
安装依赖
pip install -r requirements.txt # 国内用户加速安装 pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com• GPU 用户额外安装:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124 # 适配 CUDA 12.4 -
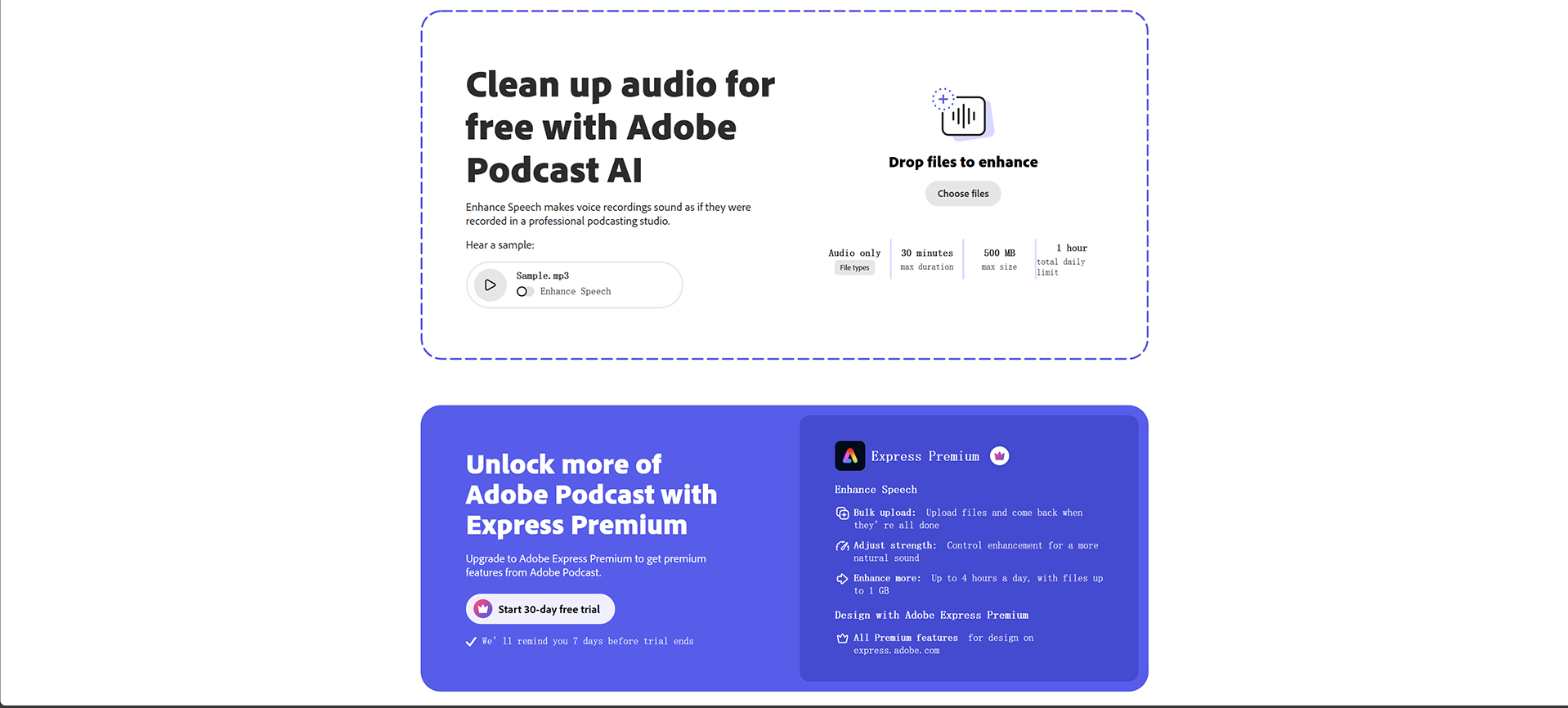
下载预训练模型
• 方法一(Python 下载):from huggingface_hub import snapshot_download snapshot_download("SparkAudio/Spark-TTS-0.5B", local_dir="pretrained_models/Spark-TTS-0.5B")• 方法二(Git 下载):
git lfs install git clone https://huggingface.co/SparkAudio/Spark-TTS-0.5B pretrained_models/Spark-TTS-0.5B
三、运行语音合成
-
基础用法(命令行)
python -m cli.inference \ --text "要合成的文本" \ --device 0 # 0 表示 GPU,CPU 用户改为 "cpu" \ --save_dir "保存路径" \ --model_dir pretrained_models/Spark-TTS-0.5B \ --prompt_text "参考音频的文本" \ --prompt_speech_path "参考音频路径"• 示例:克隆中文语音并转英文
python -m cli.inference --text "Hello, this is a test." --prompt_speech_path "path/to/chinese_audio.wav" -
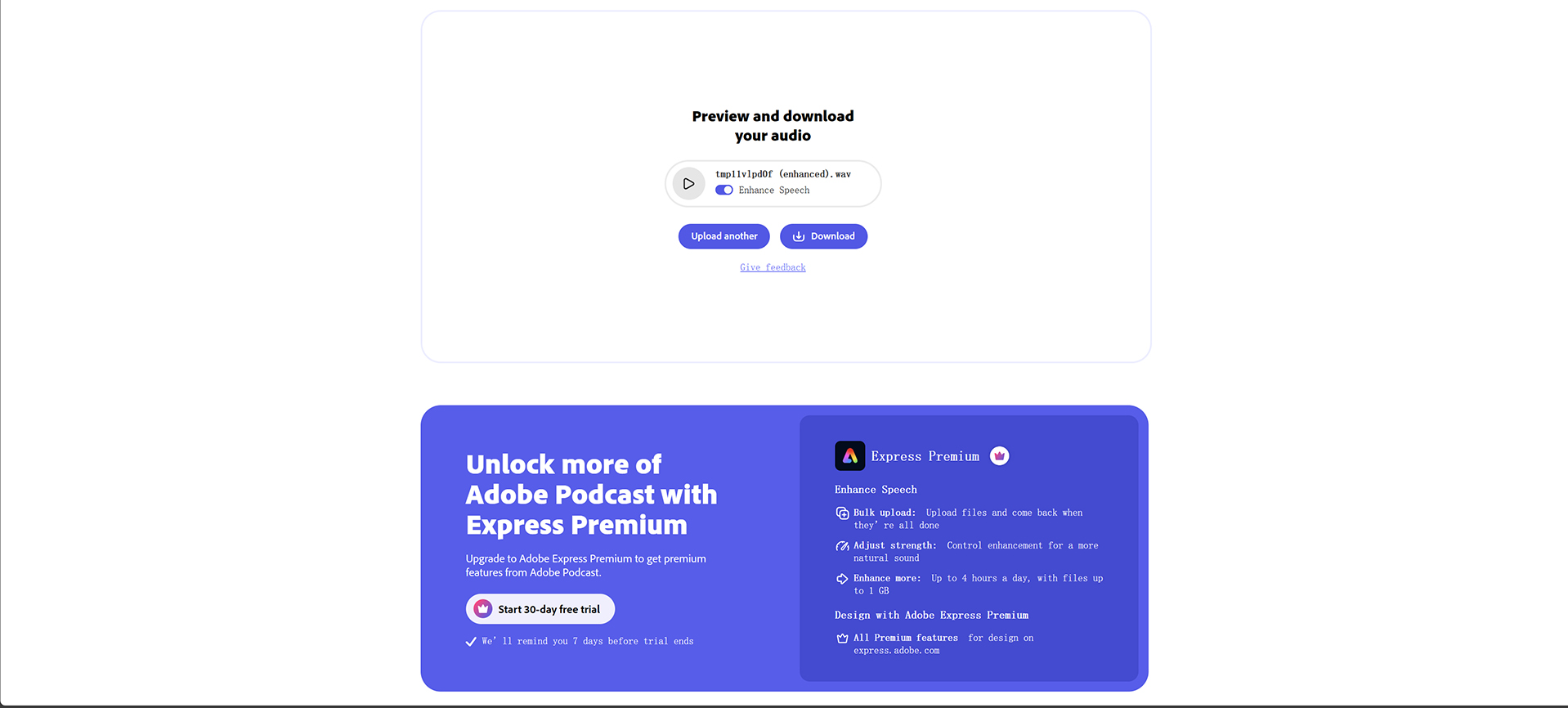
Web UI 操作
python webui.py --device 0 # 启动后访问 http://localhost:7860• 功能亮点:
◦ 上传 3-10 秒参考音频即可克隆音色
◦ 实时调节性别、语速(1-5 级)、音调(1-5 级) -
高级控制(参数调节)
- 粗粒度调节:通过
--gender指定男声/女声 - 细粒度调节: 音高:指定 Hz(如
--pitch 200) / 语速:指定每秒音节数(如--speed 4)
- 粗粒度调节:通过
常见问题解决
- 依赖冲突(Windows 特有)
- 错误:
libiomp5md.dll冲突 - 解决:删除
Anaconda安装路径/Library/bin/libiomp5md.dll或设置环境变量:set KMP_DUPLICATE_LIB_OK=TRUE
- 错误:
- GPU 无法识别
- 检查 CUDA 版本与 PyTorch 是否匹配(推荐 CUDA 12.4 + PyTorch 2.5.1)
- 克隆效果不佳
- 确保参考音频清晰(背景噪音低),时长 ≥3 秒
- 跨语言克隆时,提示文本需与参考音频语言一致
扩展功能
- 跨语言合成
- 输入中文文本生成英文语音(需提供英文参考音频),支持数字和混合文本自然断句
- 批量生成
- 修改
infer.sh脚本,循环处理多个文本文件
- 修改
- API 集成
- 通过
Spark Studio界面(需安装 PySide6)调用 API,支持企业级部署
- 通过