
上周五的时候,在杜老师的聊天室聊天,hehe 提到一个关于家里 ipv6 地址申请的问题。这时候才想到自己家里的网络应该也是有 ipv6 的地址的。至于地址是不是公网的那就不知道了。
而至于想要弄这个东西,其实还有一个原因是 he.net 的 ipv6 徽章已经很久没更新了,还差最后一步 ipv6 only 的网络访问测试,而测试的域名就是 h4ck.org.cn。

为了通过这个测试,自然要折腾一下。通过之后,he说会免费邮寄一个 T 恤衫,尺码和地址都更新了。不过这跨国的快递,不知道能不能收到。

至于能不能收到,这就只能耐心等待啦。
远程登录路由器,直接访问 ip 地址,然后高级的一幕就出现了,竟然直接打开了路由器的登录页面:

那么也就是说联通在 v6 协议下竟然没有封禁 80 端口,这样的话我忽然就有了个大胆的想法。如果路由器将 v6 的映射打开,直接访问 v6 的地址,忽略证书错误。然后网站就顺利打开了:

既然如此,那么这一来也解决了自己的 cdn 流量超限的问题。

这个月流量超限之后,买了 100G 的扩展包,结果就用了四天就又没了。为了解决流量问题,文章中的视频,直接通过 url 转发了。而至于首页右下角的图片就直接去掉了。不知道是访问量还是神马问题,这些图片一天跑十几个 G 的流量。
然而,到现在就出现了另外几个问题,要想让网站直接在互联网上访问,没有任何的防护措施,的确感觉不怎么靠谱。
1.家里的 V6 地址也是动态的,需要能够动态更新 ipv6 的 AAAA 记录。
2.在家里的主机上安装 waf 系统,提供基础的防御功能。
3.其他的未知问题。
AAAA 记录
在测试的时候,添加 AAAA 记录,会因为存在 cname 记录而导致添加失败,AAAA 记录和 CNAME 记录有冲突,请先删除或暂停现有的 CNAME 记录后重试:

此时针对不同的线路分别添加解析就 ok 了:

那么,在这之后就来到了第二个问题,怎么获取本地的公网 ipv6地址。
最直接的想法是直接通过获取 ipv4 地址类似的写法,来获取 ipv6 的地址,让 cursor 给写了类似的代码:
def get_ipv6_by_httpbin():
"""通过 httpbin.org 获取 IPv6 地址"""
url = 'https://api6.ipify.org?format=json'
try:
resp = request.urlopen(url=url, timeout=10).read()
data = json.loads(resp.decode("utf-8"))
if 'ip' in data:
return data['ip']
return None
except Exception as e:
logging.warning("get_ipv6_by_httpbin FAILED, error: %s", str(e))
return None
def get_ipv6_by_icanhazip():
"""通过 icanhazip.com 获取 IPv6 地址"""
url = 'https://icanhazip.com'
try:
resp = request.urlopen(url=url, timeout=10).read()
ip = resp.decode("utf-8").strip()
if regex_ipv6.match(ip):
return ip
return None
except Exception as e:
logging.warning("get_ipv6_by_icanhazip FAILED, error: %s", str(e))
return None
def get_ipv6_by_ident_me():
"""通过 ident.me 获取 IPv6 地址"""
url = 'https://v6.ident.me'
try:
resp = request.urlopen(url=url, timeout=10).read()
ip = resp.decode("utf-8").strip()
if regex_ipv6.match(ip):
return ip
return None
except Exception as e:
logging.warning("get_ipv6_by_ident_me FAILED, error: %s", str(e))
return None
实际证明,代码写的不错,在自己的 mac 电脑上的确可以获取到 ipv6 的地址。
然而,在家里的服务器上却使用无法获取 ip 地址,所有 v6 协议的服务都是超时状态。搜索了一堆,问了一大圈的 ai,最终都没解决问题。
后来猜测是不是路由器的问题,于是重新登录路由器的 v6 配置页面,来回切换配置:

看网上有文章会所需要改为 slaac 模式,改过去之后无效,切换成原来的自动,继续沿用上面的配置。断线重连结果网络就好啦。注意,这两个 dns 是腾讯的 dns,不是联通默认的 dns。
然而,此时就出现了另外一个问题,直到这时候我才发现,获取到的这个地址是本地的 v6 地址,而不是路由器的 v6 地址,当然,更恐怖的是这个 v6 地址也是可以在互联网直接访问的。

那么怎么自动更新这个 dns 记录就成了问题,总不能自己去天天改啊。
问小杜无果之后,继续尝试通过路由或者 tracerout 的方式获取,最终都以失败告终。至此,简单的方法算是彻底没了招了,那么就剩下一条路了,之计通过路由器获取,然鹅,tplink 的企业路由器并没有开放相关的 api。只能自己去找接口。
结果在登录页面就被来了个下马威,获取到接口,让 cursor 写完代码之后登录不了。

看起来页面很简单不是,但是这个东西恶心的地方在于登录的密码是加密过得,直接使用明文密码是登录不了的。不过好在这个密码不是动态加密的,直接使用密码登录,截取登录的加密后密码进行登录就 ok 了。剩下的就是获取 ipv6 地址,更新 dnspod 的aaaa 记录:
tplink 相关代码:
import requests
import json
import urllib.parse
def login_tplink(ip, username, password):
"""
Login to TP-Link router
:param ip: Router IP address
:param username: Login username
:param password: Login password
:return: Response from the router and stok if successful
"""
url = f"http://{ip}/"
headers = {
'Accept': 'text/plain, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Type': 'application/json; charset=UTF-8',
'Origin': f'http://{ip}',
'Pragma': 'no-cache',
'Referer': f'http://{ip}/login.htm',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
data = {
"method": "do",
"login": {
"username": username,
"password": password
}
}
try:
response = requests.post(
url,
headers=headers,
json=data,
verify=False
)
if response.status_code == 200:
try:
response_data = response.json()
if 'stok' in response_data:
return response_data['stok']
except json.JSONDecodeError:
print("Failed to parse login response as JSON")
return None
except requests.exceptions.RequestException as e:
print(f"Login error occurred: {e}")
return None
def get_network_info(ip, stok):
"""
Get network information from TP-Link router
:param ip: Router IP address
:param stok: Session token from login
:return: Network information response
"""
url = f"http://{ip}/stok={stok}/ds"
headers = {
'Accept': 'text/plain, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Type': 'application/json; charset=UTF-8',
'Origin': f'http://{ip}',
'Pragma': 'no-cache',
'Referer': f'http://{ip}/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
data = {
"method": "get",
"network": {
"table": "if_info"
}
}
try:
response = requests.post(
url,
headers=headers,
json=data,
verify=False
)
return response
except requests.exceptions.RequestException as e:
print(f"Network info error occurred: {e}")
return None
def get_wan1_pppoe_addresses(response_data):
"""
Parse IPv4 and IPv6 addresses from network info response
:param response_data: JSON response data
:return: Dictionary containing IPv4 and IPv6 addresses
"""
addresses = {
'ipv4': None,
'ipv6': None
}
try:
if_info = response_data.get('network', {}).get('if_info', [])
for interface in if_info:
if 'wan1_pppoe' in interface:
wan_data = interface['wan1_pppoe']
if 'ipaddr' in wan_data:
addresses['ipv4'] = wan_data['ipaddr']
if 'ip6addr' in wan_data:
addresses['ipv6'] = urllib.parse.unquote(wan_data['ip6addr'])
break
except Exception as e:
print(f"Error parsing wan1_pppoe addresses: {e}")
return addresses
def update_ipv6_nat_mapping(ip, stok, dest_ip):
"""
Update IPv6 NAT mapping on TP-Link router
:param ip: Router IP address
:param stok: Session token from login
:param dest_ip: Destination IPv6 address
:return: Response from the router
"""
url = f"http://{ip}/stok={stok}/ds"
headers = {
'Accept': 'text/plain, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Type': 'application/json; charset=UTF-8',
'Origin': f'http://{ip}',
'Pragma': 'no-cache',
'Referer': f'http://{ip}/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
# URL encode the IPv6 address
encoded_dest_ip = urllib.parse.quote(dest_ip)
data = {
"method": "set",
"firewall": {
"redirect_4313056213": {
"name": "mac_server_v6",
"ip_proto": "IPv6",
"if": ["WAN"],
"src_dport": "443",
"dest_port": "443",
"dest_ip": encoded_dest_ip,
"proto": "ALL",
"loopback_ipaddr": "",
"enable": "on",
"src_dport_start": "65536",
"src_dport_end": "65536",
"dest_port_start": "65536",
"dest_port_end": "65536"
}
}
}
try:
response = requests.post(
url,
headers=headers,
json=data,
verify=False
)
return response
except requests.exceptions.RequestException as e:
print(f"Error updating IPv6 NAT mapping: {e}")
return None
if __name__ == "__main__":
# Disable SSL warnings
requests.packages.urllib3.disable_warnings()
# Router credentials
ip = '192.168.1.1'
username = 'obaby'
password = '123456***加密后密码'
# First login to get stok
stok = login_tplink(ip, username, password)
if stok:
print(f"Login successful! Got stok: {stok}")
# Get network information using the stok
network_response = get_network_info(ip, stok)
if network_response:
try:
response_data = network_response.json()
addresses = get_wan1_pppoe_addresses(response_data)
print("\nWAN1 PPPoE Addresses:")
if addresses['ipv4']:
print(f"IPv4: {addresses['ipv4']}")
if addresses['ipv6']:
print(f"IPv6: {addresses['ipv6']}")
# Update NAT mapping with the IPv6 address
nat_response = update_ipv6_nat_mapping(ip, stok, addresses['ipv6'])
if nat_response:
print(f"NAT mapping update response: {nat_response.text}")
else:
print("Failed to update NAT mapping")
except json.JSONDecodeError:
print("Failed to parse network response as JSON")
else:
print("Failed to get network information")
else:
print("Login failed!")
至此第一个问题解决了。
开始第二个小问题,更新 aaaa 记录,这个就比较简单了,直接让 curosr 写就行了:
def get_record_id(domain, sub_domain, record_type='A', record_line='默认'):
"""获取记录ID,支持A和AAAA记录,以及不同的记录线路"""
url = 'https://dnsapi.cn/Record.List'
params = parse.urlencode({
'login_token': cfg['login_token'],
'format': 'json',
'domain': domain
})
req = request.Request(url=url, data=params.encode('utf-8'), method='POST', headers=header())
try:
resp = request.urlopen(req).read().decode()
except (error.HTTPError, error.URLError, socket.timeout):
return None
records = json.loads(resp).get('records', {})
for item in records:
if (item.get('name') == sub_domain and
item.get('type') == record_type and
item.get('line') == record_line):
return item.get('id')
return None
def update_ipv6_record(current_ipv6):
"""更新IPv6记录,支持多个记录和不同的记录线路"""
ipv6_count = int(cfg.get('ipv6_count', '1'))
ipv6_pool = cfg.get('ipv6_pool', '').split(',')[:ipv6_count]
cfg['current_ipv6'] = current_ipv6
if current_ipv6 not in ipv6_pool:
logging.info("new IPv6 found: %s", current_ipv6)
ipv6_pool.insert(0, current_ipv6)
cfg['ipv6_pool'] = ','.join([str(x) for x in ipv6_pool[:ipv6_count]])
# 获取所有需要更新的AAAA记录配置
aaaa_records = cfg.get('aaaa_records', '').split(',')
for record in aaaa_records:
if not record.strip():
continue
try:
sub_domain, record_line = record.strip().split(':')
if update_record('AAAA', current_ipv6, record_line, sub_domain):
logging.info(f"成功更新AAAA记录: {sub_domain}.{cfg['domain']} 线路: {record_line}")
else:
logging.error(f"更新AAAA记录失败: {sub_domain}.{cfg['domain']} 线路: {record_line}")
except ValueError:
logging.error(f"无效的AAAA记录配置: {record}")
save_config()
else:
logging.info('IPv6 地址无变化,跳过更新')
到这里网站就能正常访问了。
WAF:雷池&南墙
至于 waf 系统,其实自己之前也没怎么系统了解过,也是杜老师推荐了这两个。首先尝试的是雷池,也是杜老师最开始推荐的。
雷池:
个人版是免费的,相对来说配置也比较简单。
官网地址:https://waf-ce.chaitin.cn
自动安装一行命令即可:
bash -c "$(curl -fsSLk https://waf-ce.chaitin.cn/release/latest/manager.sh)"
安装为 docker 模式,相对来说侵入性比较小一些。并且不需要占用 80,443 端口,这一点其实相对比南墙安装配置要求要低一些。
安装之后就可以通过 9443 端口登录了。相关功能示例:

系统概览,不知道是不是因为是 v6 地址的原因,左侧地图都是空白的。

同样,这个地球上也是空白的,底部的功能都需要专业版才能查看

防护模块是全部可用的

加强防御需要专业版

通用配置模块也是 ok 的。
整体来说安装过程比较顺畅也没遇到什么问题,不过访问 ip 由于是通过路由转发进来的需要从 x-forward-for中取这个信息。
南墙
开源免费的 waf 系统
官网地址:https://waf.uusec.com/#/
在使用过程中遇到点问题,不过最后在他们的技术帮助下顺利解决了。在安装之后,首先遇到的问题就是获取的 ip 地址有问题,都是本地的地址。并且不管怎么选择地址,最后都是同一个 ip 地址。


使用测速工具测速之后,ip 地址还是一个,这肯定是有问题的。在群里问了一下,给了个指令修复这个问题:
firewall-cmd --permanent --zone=internal --change-interface=docker0
systemctl restart firewalld && systemctl daemon-reload && systemctl restart docker
不过这么执行之后可能会出现的问题就是所有的服务都访问不了了,需要在 public 区域重新开放相关服务:
sudo firewall-cmd --zone=public --permanent --add-port=10043/tcp
sudo firewall-cmd --zone=public --permanent --add-port=14443/tcp
sudo firewall-cmd --zone=public --permanent --add-port=880/tcp
sudo firewall-cmd --zone=public --permanent --add-port=3306/tcp
sudo firewall-cmd --zone=public --permanent --add-port=9443/tcp
sudo firewall-cmd --zone=public --permanent --add-port=8443/tcp
其他需要开放的服务和端口自行添加即可。
然而,这个命令并没有解决问题。包括卸载重装,其实重装这件事情对我来说有些麻烦,因为服务器的默认 80 和 443 都映射到公网了,如果直接改了也比较麻烦,只能去工控机上停掉 80 的监听,443 的修改端口重新添加映射,毕竟这台主机上相对服务少一些。
重新安装依然没解决问题,这时候提议安装主机版。
然而,更尴尬的事情粗线了,那就是主机版不支持 ubuntu,只能作罢继续使用 docker 版本。
并且安装主机版,需要提前备份数据库,安装脚本会重装 mysql。这一点一定要注意!

这时候管理员提议远程协助,于是将端口映射出去,提供账号密码,等管理员修复。


管理说可能是映射的问题,然而,雷池的没问题,那么说明一定是有解决办法的,管理提到 docker 的网络配置不一样的,于是提议修改网络配置。
最终,亲爱的管理员,成功的修复了问题:

这样这个问题算是解决了,整体而言,感觉雷池的在 v6 测速的时候更绿一些。
好啦,相对来说雷池基本所有的模块都是开放的,除了机器学习部分:

安全态势

系统信息

用户管理

日志

证书管理,这个证书管理直接上传即可,不需要去进行绑定。

cdn 加速,其实感觉更像缓存配置。

规则管理

网站管理,得添加多个。
整体来说体验还是不错的,然而,刚才去看了配置文件感觉还是 bridge 啊。奇怪了。

不过既然问题解决了,那也就不纠结了。
官方文档说明:
https://waf.uusec.com/#/guide/problems?id=%f0%9f%8d%8b-%e5%a6%82%e4%bd%95%e8%a7%a3%e5%86%b3%e5%8d%97%e5%a2%99docker%e7%89%88%e8%8e%b7%e5%8f%96%e7%9a%84%e5%ae%a2%e6%88%b7%e7%ab%afip%e4%b8%ba172%e7%9a%84%e9%97%ae%e9%a2%98%ef%bc%9f
1.将Docker网桥加入到防火墙的internal区域,以便获取到真实的IP地址, 假设Docker网桥名称为docker0。
firewall-cmd --permanent --zone=internal --change-interface=docker0
systemctl restart firewalld && systemctl daemon-reload && systemctl restart docker
2.如果方法1无效,可以修改docker-compose.yml文件,将uuwaf容器的网络设置为network_mode: host,同时修改数据库连接环境变量UUWAF_DB_DSN中的wafdb为127.0.0.1,并映射wafdb容器的3306端口,重启后生效。
其他问题
鉴于主机获取的 ipv6 地址能直接访问,其实我一度想直接把主机的地址更新到 dns aaaa 记录上,但是这么一搞,暴露主机的确不是我最终想要的。
于是想着映射本地的链路地址,然而,端口映射通过链路地址通过路由器的 v6 地址却打不开网站,但是这个链路地址在内网的主机上又能打开网站,于是只能放弃这个做法。获取 ipv6 地址的代码:
import re
import logging
import json
import subprocess
import socket
import os
from urllib import request, error, parse
# 匹配合法 IPv6 地址
regex_ipv6 = re.compile(
r"(?:inet6\s+)?(fe80:[0-9a-fA-F:]+|" # 特别处理链路本地地址格式
+ r"(?:[0-9a-fA-F]{1,4}:){7}[0-9a-fA-F]{1,4}|" # 标准格式
+ r"(?:[0-9a-fA-F]{1,4}:){6}:[0-9a-fA-F]{1,4}|" # 压缩格式
+ r"(?:[0-9a-fA-F]{1,4}:){5}(?::[0-9a-fA-F]{1,4}){1,2}|"
+ r"(?:[0-9a-fA-F]{1,4}:){4}(?::[0-9a-fA-F]{1,4}){1,3}|"
+ r"(?:[0-9a-fA-F]{1,4}:){3}(?::[0-9a-fA-F]{1,4}){1,4}|"
+ r"(?:[0-9a-fA-F]{1,4}:){2}(?::[0-9a-fA-F]{1,4}){1,5}|"
+ r"(?:[0-9a-fA-F]{1,4}:){1}(?::[0-9a-fA-F]{1,4}){1,6}|"
+ r"(?::[0-9a-fA-F]{1,4}){1,7}|"
+ r"::"
+ r")")
# 特别匹配链路本地 IPv6 地址,确保能匹配到 fe80:: 开头的地址
regex_link_local_ipv6 = re.compile(r"inet6\s+(fe80:[0-9a-fA-F:]+)")
def get_ipv6():
"""获取公网 IPv6 地址,使用多个备选方法"""
return (get_ipv6_by_ifconfig() # 优先使用本地接口地址
or get_ipv6_by_httpbin()
or get_ipv6_by_icanhazip()
or get_ipv6_by_ident_me()
or get_ipv6_by_socket())
def get_ipv6_by_ifconfig():
"""通过 ifconfig 命令获取本地 IPv6 地址"""
try:
# Windows 系统使用 ipconfig
if os.name == 'nt':
cmd = ['ipconfig']
output = subprocess.check_output(cmd, text=True)
# Linux/Unix 系统使用 ifconfig
else:
cmd = ['ifconfig']
output = subprocess.check_output(cmd, text=True)
# 按行分割输出
lines = output.split('\n')
for line in lines:
# 查找包含 inet6 的行
if 'inet6' in line:
# 使用正则表达式提取 IPv6 地址
matches = regex_ipv6.findall(line)
if matches:
ipv6 = matches[0]
# 排除本地回环地址
if not ipv6.startswith('::1'):
logging.info(f"Found IPv6 address: {ipv6}")
return ipv6
except Exception as e:
logging.warning("get_ipv6_by_ifconfig FAILED, error: %s", str(e))
return None
def get_ipv6_by_socket():
"""通过 Python socket 库获取本地 IPv6 地址"""
try:
# 创建一个 IPv6 socket
s = socket.socket(socket.AF_INET6, socket.SOCK_DGRAM)
# 连接到一个外部地址(这里使用 Google 的 IPv6 DNS)
s.connect(('2001:4860:4860::8888', 80))
# 获取本地地址
local_addr = s.getsockname()[0]
s.close()
return local_addr
except Exception as e:
logging.warning("get_ipv6_by_socket FAILED, error: %s", str(e))
return None
def get_ipv6_by_httpbin():
"""通过 httpbin.org 获取 IPv6 地址"""
url = 'https://api6.ipify.org?format=json'
try:
resp = request.urlopen(url=url, timeout=10).read()
data = json.loads(resp.decode("utf-8"))
if 'ip' in data:
return data['ip']
return None
except Exception as e:
logging.warning("get_ipv6_by_httpbin FAILED, error: %s", str(e))
return None
def get_ipv6_by_icanhazip():
"""通过 icanhazip.com 获取 IPv6 地址"""
url = 'https://icanhazip.com'
try:
resp = request.urlopen(url=url, timeout=10).read()
ip = resp.decode("utf-8").strip()
if regex_ipv6.match(ip):
return ip
return None
except Exception as e:
logging.warning("get_ipv6_by_icanhazip FAILED, error: %s", str(e))
return None
def get_ipv6_by_ident_me():
"""通过 ident.me 获取 IPv6 地址"""
url = 'https://v6.ident.me'
try:
resp = request.urlopen(url=url, timeout=10).read()
ip = resp.decode("utf-8").strip()
if regex_ipv6.match(ip):
return ip
return None
except Exception as e:
logging.warning("get_ipv6_by_ident_me FAILED, error: %s", str(e))
return None
def get_link_local_ipv6():
"""专门获取链路本地 IPv6 地址"""
try:
# Windows 系统使用 ipconfig
if os.name == 'nt':
cmd = ['ipconfig']
output = subprocess.check_output(cmd, text=True)
# Linux/Unix 系统使用 ifconfig
else:
cmd = ['ifconfig']
output = subprocess.check_output(cmd, text=True)
# 按行分割输出
lines = output.split('\n')
for line in lines:
# 查找包含 inet6 的行
if 'inet6' in line:
# 提取 IPv6 地址和 prefixlen
if 'prefixlen 64' in line and 'scopeid 0x20<link>' in line:
# 调试输出
logging.debug(f"Processing line: {line}")
# 使用特定正则表达式提取链路本地 IPv6 地址
matches = regex_link_local_ipv6.findall(line)
if matches:
ipv6 = matches[0]
logging.info(f"Found link-local IPv6 address with new regex: {ipv6}")
return ipv6
# 如果特定正则表达式没有匹配到,尝试使用一般性正则表达式
matches = regex_ipv6.findall(line)
if matches:
ipv6 = matches[0]
logging.debug(f"Original regex matched: {ipv6}")
# 只返回链路本地地址
if ipv6.startswith('fe80'):
logging.info(f"Found link-local IPv6 address with original regex: {ipv6}")
return ipv6
elif 'fe80' in line:
# 如果行中包含fe80但匹配失败,记录错误
logging.warning(f"Regex failed to match fe80 in: {line}")
except Exception as e:
logging.warning("get_link_local_ipv6 FAILED, error: %s", str(e))
return None
# 测试
if __name__ == '__main__':
logging.basicConfig(level=logging.DEBUG)
# 测试特定的 IPv6 地址匹配
test_line = "inet6 fe80::e4d:e9ff:fec9:9de3 prefixlen 64 scopeid 0x20<link>"
print("Testing regex with line:", test_line)
# 测试链路本地特定正则
matches = regex_link_local_ipv6.findall(test_line)
if matches:
print("Link-local regex matched:", matches[0])
else:
print("Link-local regex failed to match")
# 测试一般 IPv6 正则
matches = regex_ipv6.findall(test_line)
if matches:
print("General IPv6 regex matched:", matches[0])
else:
print("General IPv6 regex failed to match")
print("\n--- Regular program output ---")
print("Method 1 (httpbin):", get_ipv6_by_httpbin())
print("Method 2 (icanhazip):", get_ipv6_by_icanhazip())
print("Method 3 (ident.me):", get_ipv6_by_ident_me())
print("Method 4 (ifconfig):", get_ipv6_by_ifconfig())
print("Method 5 (socket):", get_ipv6_by_socket())
print("Link-local IPv6:", get_link_local_ipv6())
获取到 v6 地址,就可以通过 tplink 的映射代码update_ipv6_nat_mapping进行地址映射了。
如果要用这个代码,需要根据自己的路由器配置获取映射的 id。
整体来说,速度还是可以的: 
The post 是 IPv6 吖 — V6 重生记 appeared first on obaby@mars.






















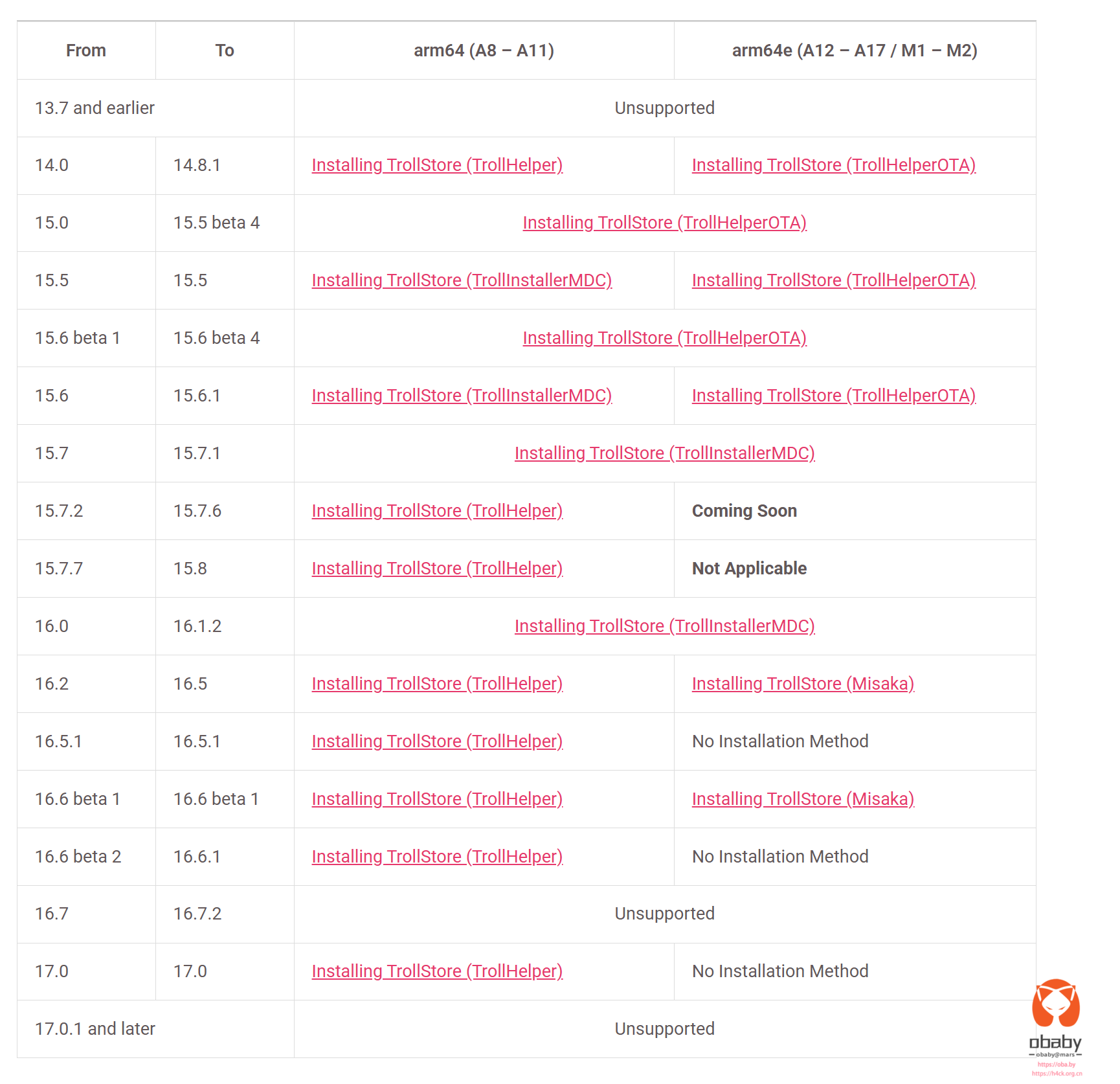
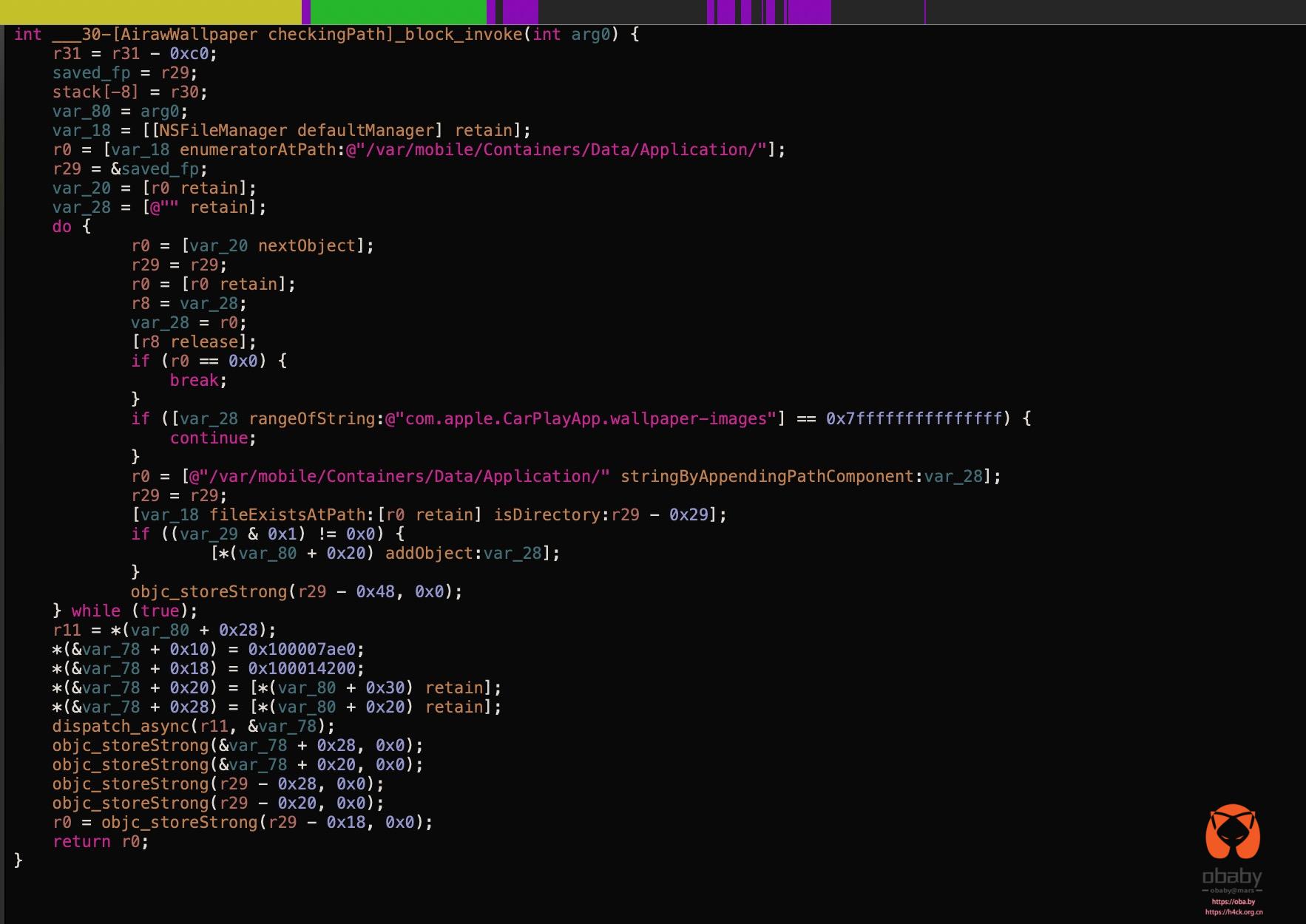
 _CodeSignature 目录不存在,这可能导致安装失败"
fi
# 显示更多签名信息
echo "显示详细签名信息..."
codesign -d --entitlements :- "$APP_PATH"
# 验证所有签名
echo "验证所有签名..."
if codesign --verify --deep --strict --verbose=4 "$APP_PATH"; then
echo "✓ 严格验证通过"
else
echo "
_CodeSignature 目录不存在,这可能导致安装失败"
fi
# 显示更多签名信息
echo "显示详细签名信息..."
codesign -d --entitlements :- "$APP_PATH"
# 验证所有签名
echo "验证所有签名..."
if codesign --verify --deep --strict --verbose=4 "$APP_PATH"; then
echo "✓ 严格验证通过"
else
echo "




























































































































































































 ,忽然觉得抽到那么多隐藏款也不是什么特别让人开心的事情,不过宝子已经决定把这个敖光送人了。知我的蓝胖子后面的卡片,都是我买的,并且都是最低级的卡。这运气不得不说,区别有点大。当然宝子不可能就这几个,柜子里已经塞了很多了。
,忽然觉得抽到那么多隐藏款也不是什么特别让人开心的事情,不过宝子已经决定把这个敖光送人了。知我的蓝胖子后面的卡片,都是我买的,并且都是最低级的卡。这运气不得不说,区别有点大。当然宝子不可能就这几个,柜子里已经塞了很多了。





 ,昨晚睡觉的时候我跟对象说,我每天流鼻涕也能轻二两,助力了我的减肥事业。
,昨晚睡觉的时候我跟对象说,我每天流鼻涕也能轻二两,助力了我的减肥事业。




































 多开心,后面就会与多后悔。这一切看似非常人性化的体验升级,带来的是自己多跑了一百公里的代价。其实车子上了环湾过了跨海之后就开始提示信号弱,然后说什么开启北斗定位模式。这种情况之前也遇到过,想着应该没什么大问题,就继续前进了。
多开心,后面就会与多后悔。这一切看似非常人性化的体验升级,带来的是自己多跑了一百公里的代价。其实车子上了环湾过了跨海之后就开始提示信号弱,然后说什么开启北斗定位模式。这种情况之前也遇到过,想着应该没什么大问题,就继续前进了。































 解决部分南墙容器版获取的客户端ip为网桥ip的问题?
解决部分南墙容器版获取的客户端ip为网桥ip的问题?