X Window 与 Wayland 不仅代表了图形界面技术不同发展阶段,更体现了设计理念、架构模式及应用场景的显著差异。本文将从历史背景、技术特点、应用场景及未来展望等多个维度,对 X Window 和 Wayland 进行深入剖析。
历史背景演变
X11 诞生于 1984 年,由麻省理工学院 MIT 开发,旨在满足分布式计算环境下图形界面需求。其设计哲学强调网络透明性,允许用户在远程服务器运行应用程序,并在本地终端显示结果,极大地拓展 GUI 的可用性和灵活性。随着时间推移,X11 凭借其广泛的硬件和软件支持,逐渐成为 Linux 桌面环境的标准图形界面后端。
随着计算需求增长,X11 的一些设计局限逐渐显现,例如架构复杂、性能瓶颈和安全性问题。2008 年,Kristian 提出 Wayland 项目,旨在创建一个更加现代、高效窗口系统。Wayland 的设计重点在于简化架构、提高性能和增强安全性,采用客户端 Compositor 通信模型,减少了中间层,提升了效率和响应速度。
技术特点比较
X11 采用 C/S 模型,客户端通过 X 协议与服务器通信,而 X 服务器负责处理所有图形和输入事件。相比之下,Wayland 采用了客户端 Compositor 模型,客户端可直接与 Compositor 通信,Compositor 负责了窗口管理、合成、输出。Wayland 的架构更加贴合现代图形硬件特性,可以更高效地利用 GPU 和现代显示技术。
X11 在安全性方面存在了固有弱点,其复杂协议和广泛权限易被恶意利用。Wayland 通过限制客户端权限以及简化通信模型,显著提高了安全性。例如,Wayland 禁止了应用程序直接访问底层硬件,只允许了它们与 Compositor 通信,从而增强系统的安全性。
这篇文章介绍了视频音量的重要性及其调整方法。文中提到,视频音量过低会影响观看体验,特别是在信息流中与其他大声视频竞争时。为了解决这一问题,文章引入了LUFS(Loudness Units Full Scale)作为衡量音频响度的标准,并解释了其在广播和流媒体中的应用。作者推荐使用ffmpeg工具来测量视频的LUFS值,并提供了具体的操作命令和参数说明。最后,文章还详细解读了测量结果中各项参数的意义,帮助用户更好地调整视频音量以符合不同平台的要求。
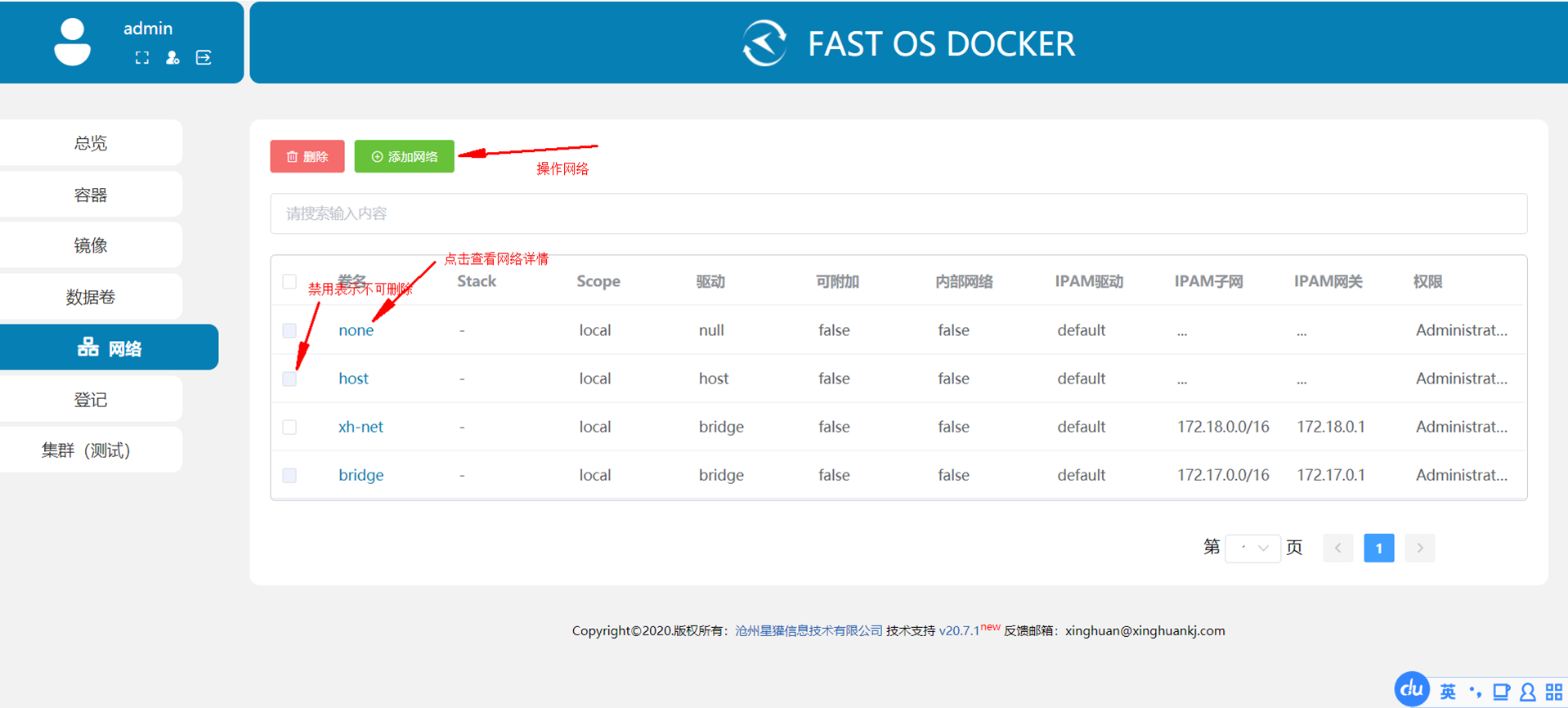
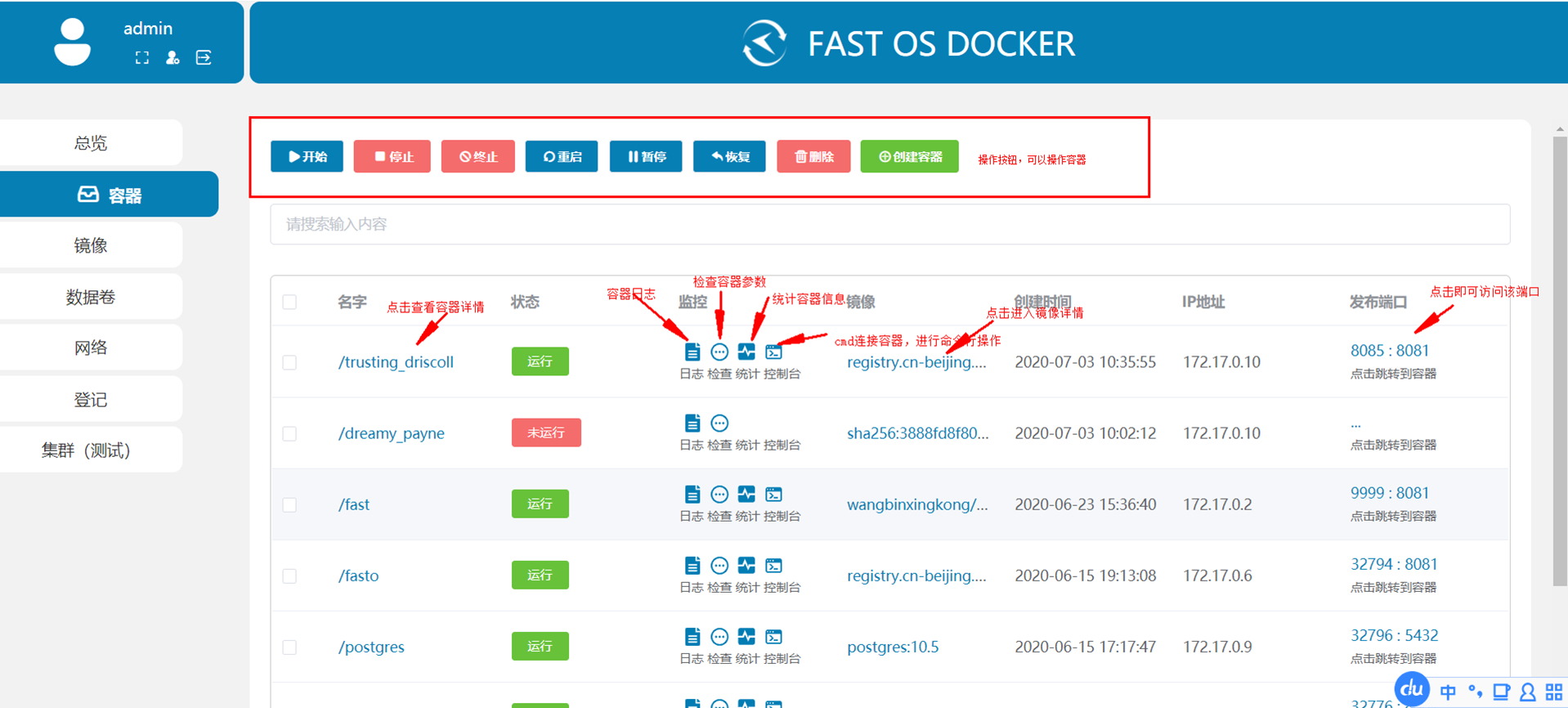
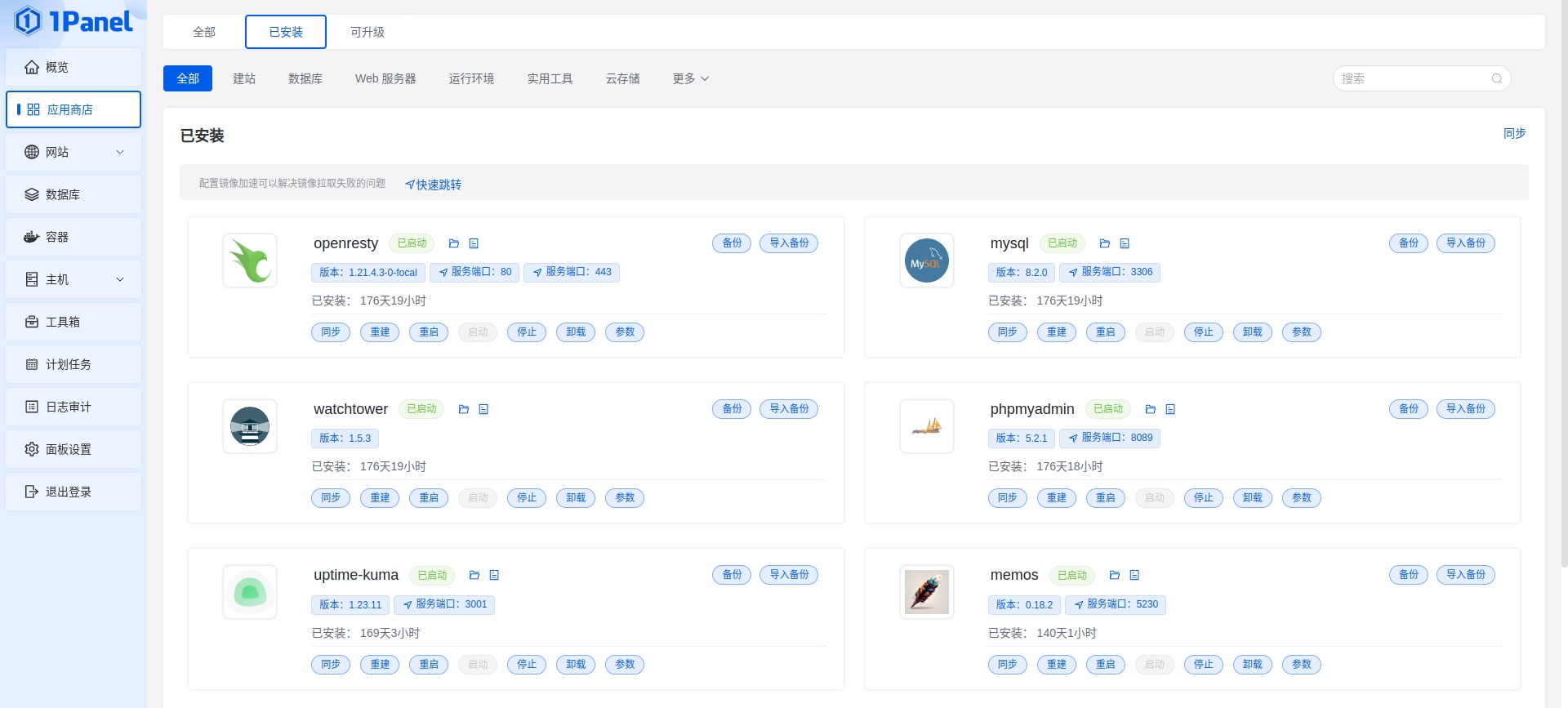
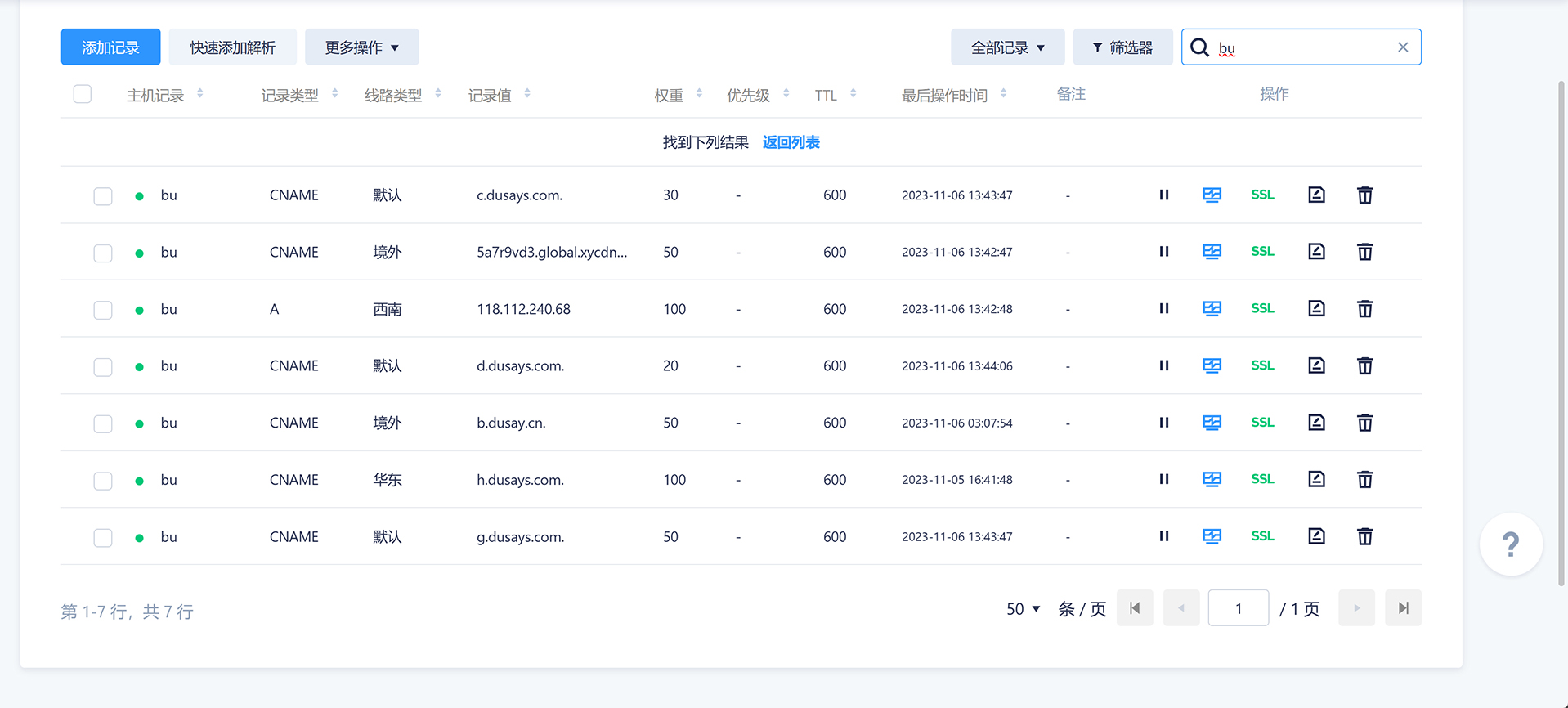
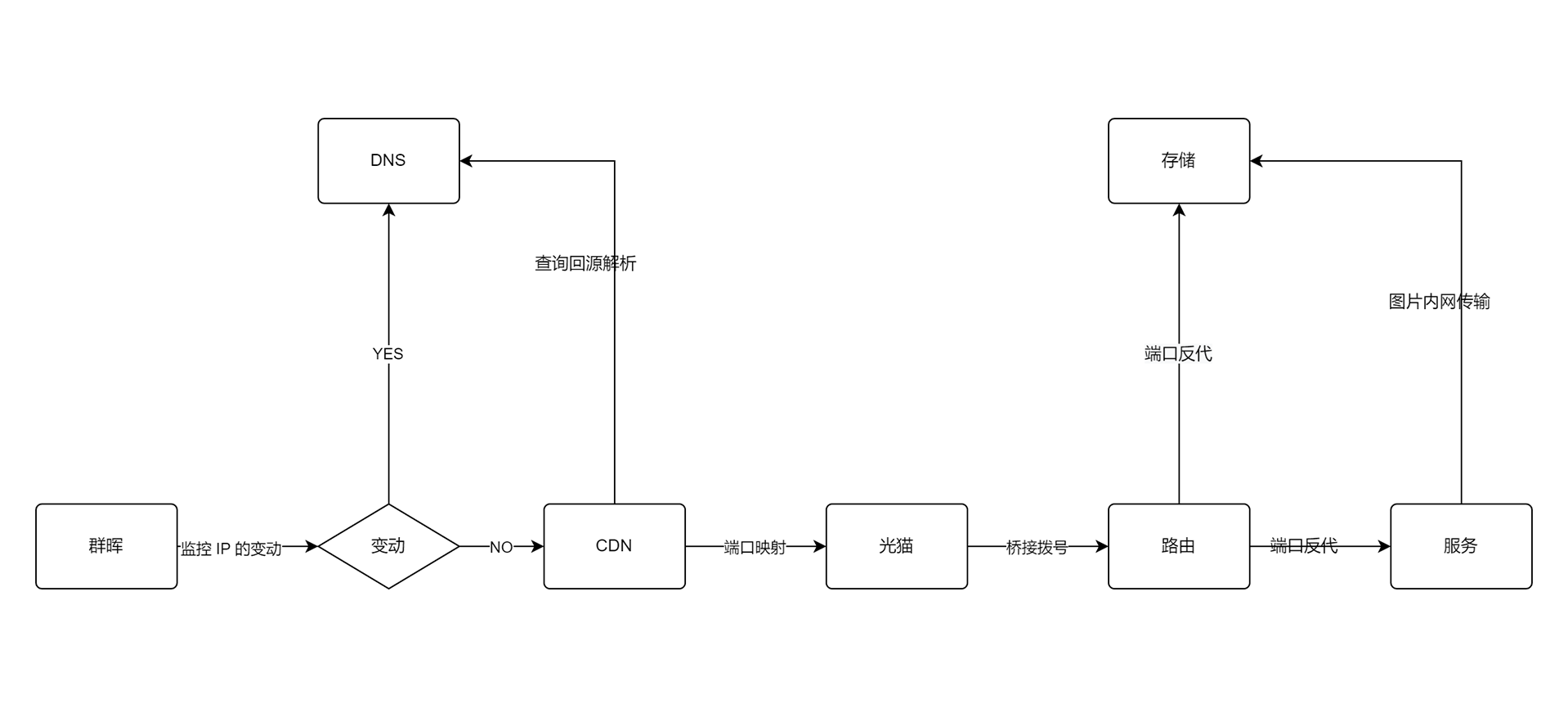
这篇文章介绍了如何在使用 docker-compose 部署的环境中为容器设置固定的 IP 地址,以解决容器在重启后因 IP 自动变化导致无法上网的问题。文章首先创建了一个名为 heo_global_network 的自定义桥接网络,并将其 IP 地址段设置为 172.168.0.0/16。然后修改 docker-compose 文件,将容器连接到该外部网络并指定静态 IPv4 地址。通过这些步骤,用户可以确保容器在网络重启后保持稳定的 IP 地址,并成功实现上网功能。
The downloaded packages were saved in cache until the next successful transaction. You can remove cached packages by executing 'yum clean packages'. Error: Transaction test error: file /usr/share/doc/ipmitool/ChangeLog from install of ipmitool-1.8.19-1.p01.ky10.x86_64 conflicts with file from package ipmitool-help-1.8.18-19.p02.ky10.noarch file /usr/share/doc/ipmitool/README from install of ipmitool-1.8.19-1.p01.ky10.x86_64 conflicts with file from package ipmitool-help-1.8.18-19.p02.ky10.noarch file /usr/share/man/man1/ipmitool.1.gz from install of ipmitool-1.8.19-1.p01.ky10.x86_64 conflicts with file from package ipmitool-help-1.8.18-19.p02.ky10.noarch
Bro.. I thought you’re like senior…
Yes, I am senior!
You should know how to do it then..
I’ll ask ChatGPT..
Bro, you don’t need ChatGPT..
OK, we can talk about it next lesson.
毕竟现在右侧有文章分类、随机文章、热门文章三个模块。系统化整理文章、提高可发现性性上已经足够了。
在 SEO 优化上文章归档页固然归可以帮助搜索引擎更好地抓取和索引博客内容,不过在已经有 xml 站点地图的时候,文章归档页对于提供博客的 SEO 优化上作用不大,相较这种 html 格式站点地图,xml 格式的站点地图对搜索引擎会更加友好一些。
from statistics import mode
data = [1, 2, 2, 3, 4]
result = mode(data)
print(result) # 输出: 2
字符串作为数据
from statistics import mode
data = ["apple", "banana", "apple", "cherry"]
result = mode(data)
print(result) # 输出: "apple"
多模态数据(引发错误)
如果有多个众数,mode() 会引发 StatisticsError。
from statistics import mode
data = [1, 1, 2, 2, 3]
try:
result = mode(data)
except StatisticsError as e:
print(e) # 输出: "no unique mode; found 2 equally common values"
无重复值(引发错误)
如果数据集中没有值重复,mode() 会引发 StatisticsError。
from statistics import mode
data = [1, 2, 3, 4, 5]
try:
result = mode(data)
except StatisticsError as e:
print(e) # 输出: "no unique mode; found 5 equally common values"
空数据集(引发错误)
如果数据集为空,mode() 会引发 StatisticsError。
from statistics import mode
data = []
try:
result = mode(data)
except StatisticsError as e:
print(e) # 输出: "no mode for empty data"
string, a number 就这俩,之前我一度尝试使用byte[],或者从js发送内存指针都提示参数类型不正确。 下面是文档摘录。 Where objectName is the name of an object in your scene; methodName is the name of a method in the script, currently attached to that object; value can be a string, a number, or can be empty. For example:
if (request.result == UnityWebRequest.Result.Success) { var imageObject = GameObject.Find("ImageObject"); var sprite = Sprite.Create(texDl.texture, new Rect(0, 0, texDl.texture.width, texDl.texture.height), new Vector2(0.5f, 0.5f)); imageObject.GetComponent<UnityEngine.UI.Image>().sprite = sprite; } else { Debug.LogError("Error downloading image: " + request.error); }
request.Dispose(); }
需要获取运行实例
下面摘录自官方文档,大致意思是js要调用unity的逻辑需要找到对应已创建的实例。
1 2 3 4
However, if you are planning to call the internal JavaScript functions from the global scope of the embedding page, you should always assume that there are multiple builds embedded on the page, so you should explicitly specify which build you are referencing to. For example, if your game has been instantiated as: var gameInstance = UnityLoader.instantiate("gameContainer", "Build/build.json", {onProgress: UnityProgress}); Then you can send a message to the build using gameInstance.SendMessage(), or access the build Module object like this gameInstance.Module.
import requests
import json
api_key = "x_ai ..."
# Define the API endpoint and headers
url = "https://api.x.ai/v1/chat/completions"
headers = {
"Content-Type": "application/json",
f"Authorization": "Bearer {api_key}",
}
# Define a system message for context
system_message = {"role": "system", "content": "You are a test assistant."}
print("Welcome to the Grok, an AI chatbot. Type 'bye' to exit.\n")
while True:
# Prompt the user for input
user_input = input("You: ").strip()
# Check if the user wants to exit
if user_input.lower() == "bye":
print("Goodbye!")
break
if user_input == "":
continue
# Define the payload
payload = {
"messages": [
system_message,
{"role": "user", "content": user_input}
],
"model": "grok-beta",
"stream": False,
"temperature": 0
}
try:
# Make the request
response = requests.post(url, headers=headers, json=payload)
# Check the response status
if response.status_code == 200:
data = response.json()
assistant_response = data["choices"][0]["message"]["content"]
print(f"Grok: {assistant_response}\n")
else:
print(f"Error: {response.status_code} - {response.text}")
except Exception as e:
print(f"An error occurred: {e}")
所以它接口函数和 WordPress 的 Option API (get_option, add_option, update_option, delete_option))基本一样,唯一区别就是 Transients API 有一个过期时间,并且它没有 add 方法,统一合并成 set 了,所以 WordPress Transients API 有以下三个函数:
String.format = function () { if (arguments.length == 0) returnnull; var str = arguments[0]; for (var i = 1; i < arguments.length; i++) { var re = newRegExp('\\{' + (i - 1) + '\\}', 'gm'); str = str.replace(re, arguments[i]); } return str; }
let data = {} let index = 0
functionrefreshContentInterval() { if (index >= 4) index = 0; index++; var firstData = data[index] var result = firstData.snippet; if (result.length > 30) { result = result.slice(0, 30) + "..."; } let post_index = "改成转跳的页面"; const descriptionDiv = document.getElementById('description'); descriptionDiv.innerHTML = ''; const aTag = document.createElement('a');
这篇文章介绍了如何在中国大陆使用AirPods Pro 2进行听力检测。用户需要通过Safari打开特定链接进入听力检测,确保在安静环境下佩戴耳机并调整贴合度,以获取准确结果。在测试期间,耳机会播放不同频率和音量的声音,用户需在听到声音时轻点屏幕以完成检测。文章还分享了作者的测试结果,显示左耳和右耳均为10 dBHL或更低的细微损伤或无损伤状态。
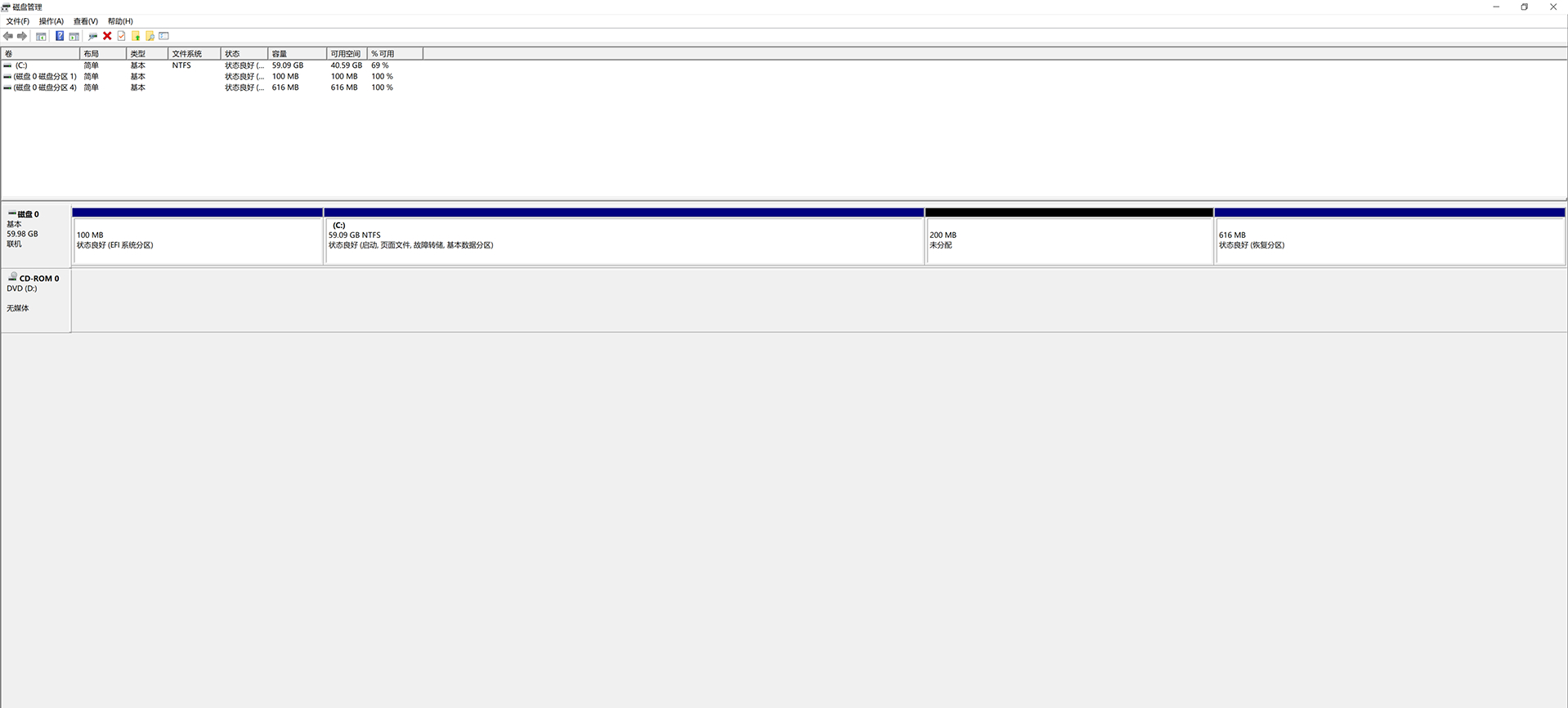
本文介绍如何解决 Windows 更新时出现的错误代码 0x80070643,原因是 WinRE 恢复环境空间不足。先通过进入命令提示符,禁用掉 WinRE,调整磁盘管理工具,扩展 C 盘空间并创建新的 WinRE 分区,最终重启 WinRE 并完成系统更新。
问题截图
如果最近更新 Windows 时,在安装的状态卡了一会,随后报错,并显示错误代码 0x80070643:
首先明确故障来源,错误代码 0x80070643 对应的是系统的 WinRE 恢复盘分区容量不足。这个 RE 盘在资源管理器中是看不到的,可通过磁盘管理器查看它的分区容量。我们可以通过右键点击开始——磁盘管理看到如下界面。可以看到恢复分区不足 750 兆,需要对其扩容:
压缩分区
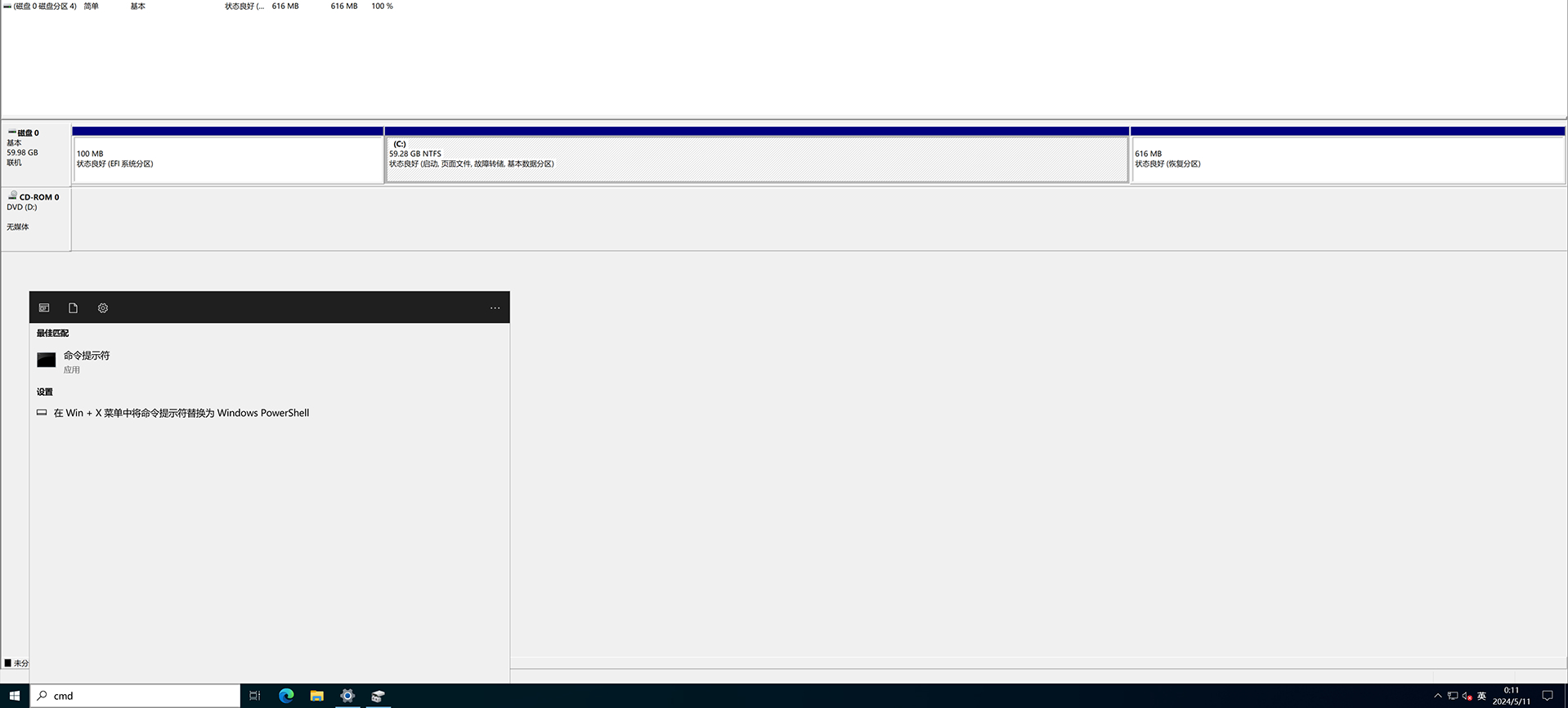
通过上面截图可以看出,恢复分区的临近分区是 C 盘,我们接下来要从 C 盘中,获取一定的空间给恢复分区。首先要进入命令提示符界面,在搜索框中输入 cmd,右键点击命令提示符并在弹出菜单中选择以管理员身份运行:
打开命令提示符界面后,我们将 WinRE 恢复功能临时禁用,便于后续分区修改:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
C:\Users\Administrator>reagentc /info Windows 恢复环境(Windows RE)和系统初始化配置 信息: Windows RE 状态: Enabled Windows RE 位置: \\?\GLOBALROOT\device\harddisk0\partition4\Recovery\WindowsRE 引导配置数据(BCD)标识符: c9a5b046-496f-11ec-b9e7-ed5c24c96968 恢复映像位置: 恢复映像索引: 0 自定义映像位置: 自定义映像索引: 0
开启磁盘管理工具,进入目标磁盘 C 盘。接下来输入 list disk,先检查下磁盘列表,确定我们要进入的是磁盘 0,则输入 sel disk 0。接下来检查磁盘 0 的分区列表输入 list partition。找到 C 盘对应分区号 3 后输入 sel part 3。使用 shrink desired=200 minimum=200 命令从目标分区切出 200 兆容量备用:
C:\Users\Administrator>reagentc /info Windows 恢复环境(Windows RE)和系统初始化配置 信息: Windows RE 状态: Enabled Windows RE 位置: \\?\GLOBALROOT\device\harddisk0\partition3\Recovery\WindowsRE 引导配置数据(BCD)标识符: c9a5b048-496f-11ec-b9e7-ed5c24c96968 恢复映像位置: 恢复映像索引: 0 自定义映像位置: 自定义映像索引: 0
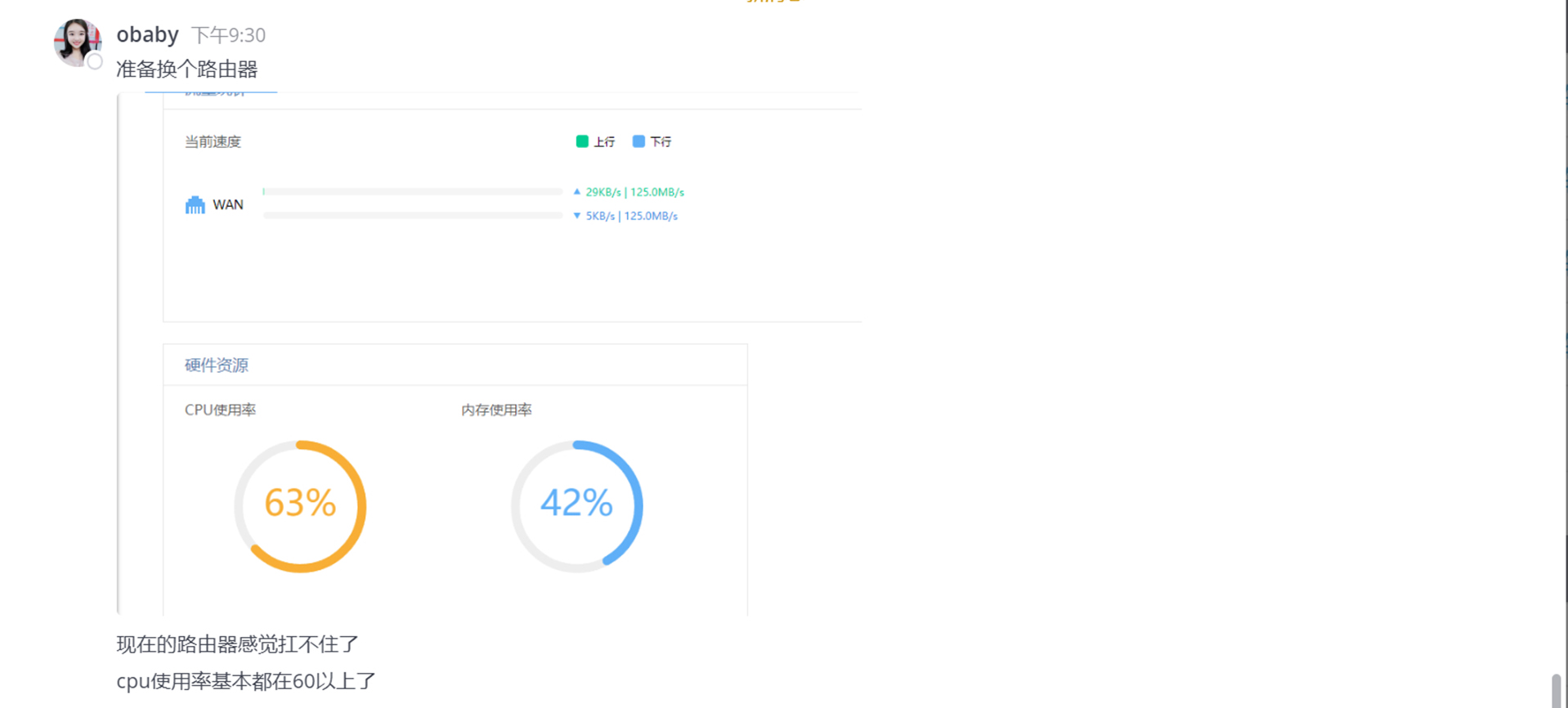
宝塔有 Windows/Linux 双平台的面板,不管什么系统都能运行,且支持 ARM 架构。网站相关服务软件版本齐全,简单配置即可上线站点。该夸的都夸了,下面说说它的缺点,其实也不算是缺点。首先是插件收费的问题,当然有些小伙伴会通过和谐手段跳过收费,但还是不可避免的要求在线验证「使用面板前要登录账号」
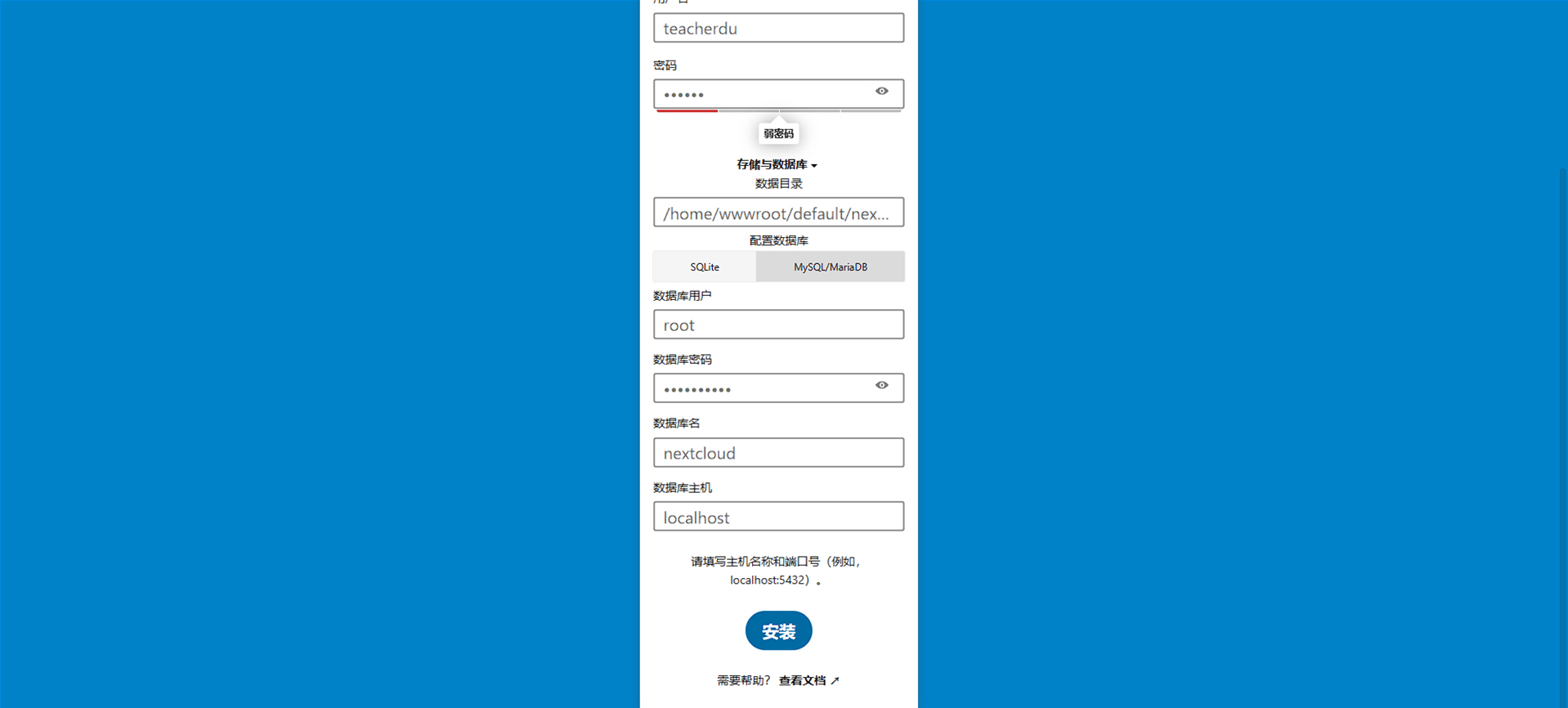
+------------------------------------------------------------------------+ | LNMP V1.9 for CentOS Linux Server, Written by Licess | +------------------------------------------------------------------------+ | A tool to auto-compile & install LNMP/LNMPA/LAMP on Linux | +------------------------------------------------------------------------+ | For more information please visit https://lnmp.org | +------------------------------------------------------------------------+ You have 11 options for your DataBase install. 1: Install MySQL 5.1.73 2: Install MySQL 5.5.62 (Default) 3: Install MySQL 5.6.51 4: Install MySQL 5.7.38 5: Install MySQL 8.0.30 6: Install MariaDB 5.5.68 7: Install MariaDB 10.3.35 8: Install MariaDB 10.4.25 9: Install MariaDB 10.5.16 10: Install MariaDB 10.6.8 0: DO NOT Install MySQL/MariaDB Enter your choice (1, 2, 3, 4, 5, 6, 7, 8, 9, 10 or 0): 4 Using Generic Binaries [y/n]: y You will install MySQL 5.7.38 Using Generic Binaries. =========================== Please setup root password of MySQL. Please enter: Dusays@1234 MySQL root password: Dusays@1234 =========================== Do you want to enable or disable the InnoDB Storage Engine? Default enable,Enter your choice [Y/n]: Y You will enable the InnoDB Storage Engine =========================== You have 9 options for your PHP install. 1: Install PHP 5.2.17 2: Install PHP 5.3.29 3: Install PHP 5.4.45 4: Install PHP 5.5.38 5: Install PHP 5.6.40 (Default) 6: Install PHP 7.0.33 7: Install PHP 7.1.33 8: Install PHP 7.2.34 9: Install PHP 7.3.33 10: Install PHP 7.4.30 11: Install PHP 8.0.20 12: Install PHP 8.1.7 Enter your choice (1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12): 11 You will install PHP 8.0.20 =========================== You have 3 options for your Memory Allocator install. 1: Don't install Memory Allocator. (Default) 2: Install Jemalloc 3: Install TCMalloc Enter your choice (1, 2 or 3): 1 You will install not install Memory Allocator. =========================== Please enter Administrator Email Address: teacherdu@dusays.com =========================== Server Administrator Email: teacherdu@dusays.com =========================== =========================== You have 2 options for your Apache install. 1: Install Apache 2.2.34 2: Install Apache 2.4.53 (Default) Enter your choice (1 or 2): 2 You will install Apache 2.4.53
Press any key to install...or Press Ctrl+c to cancel
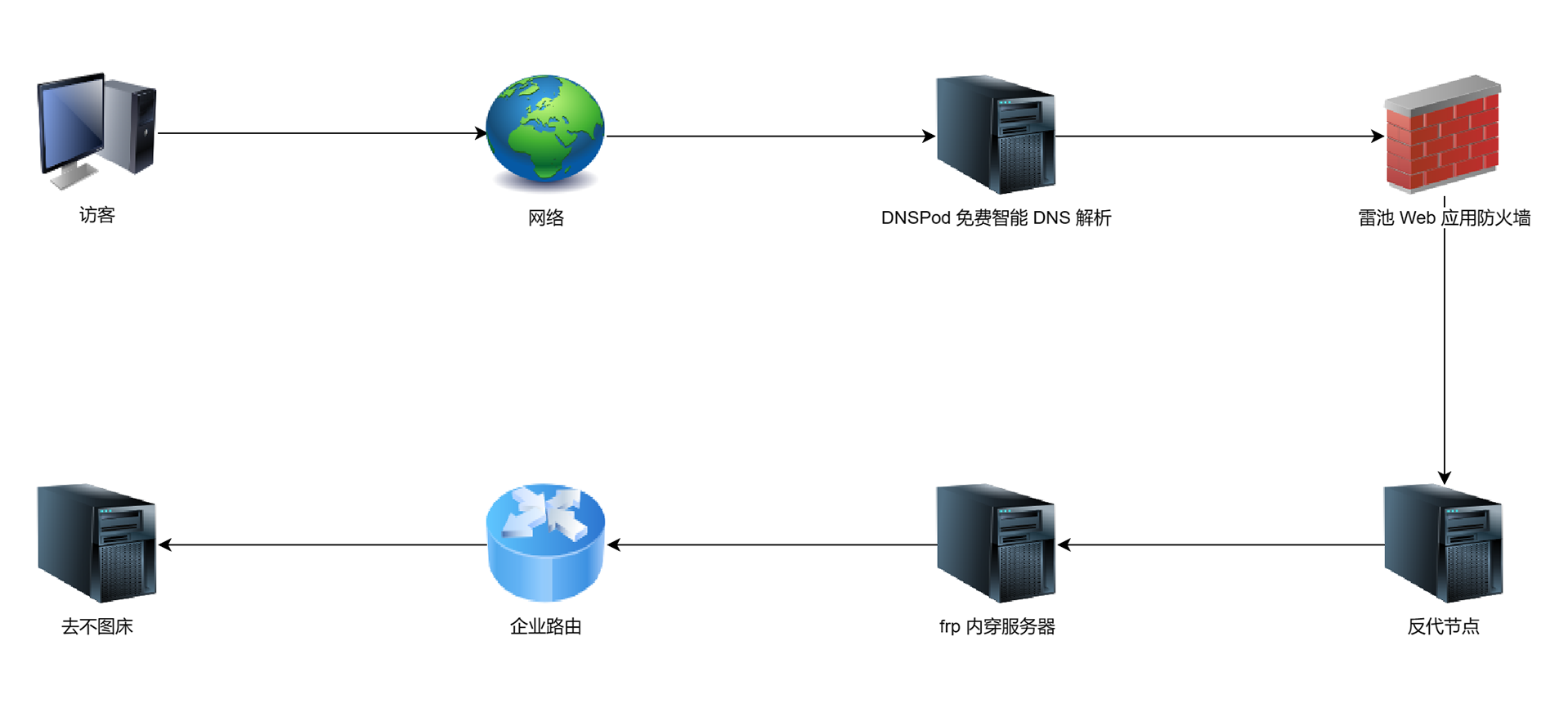
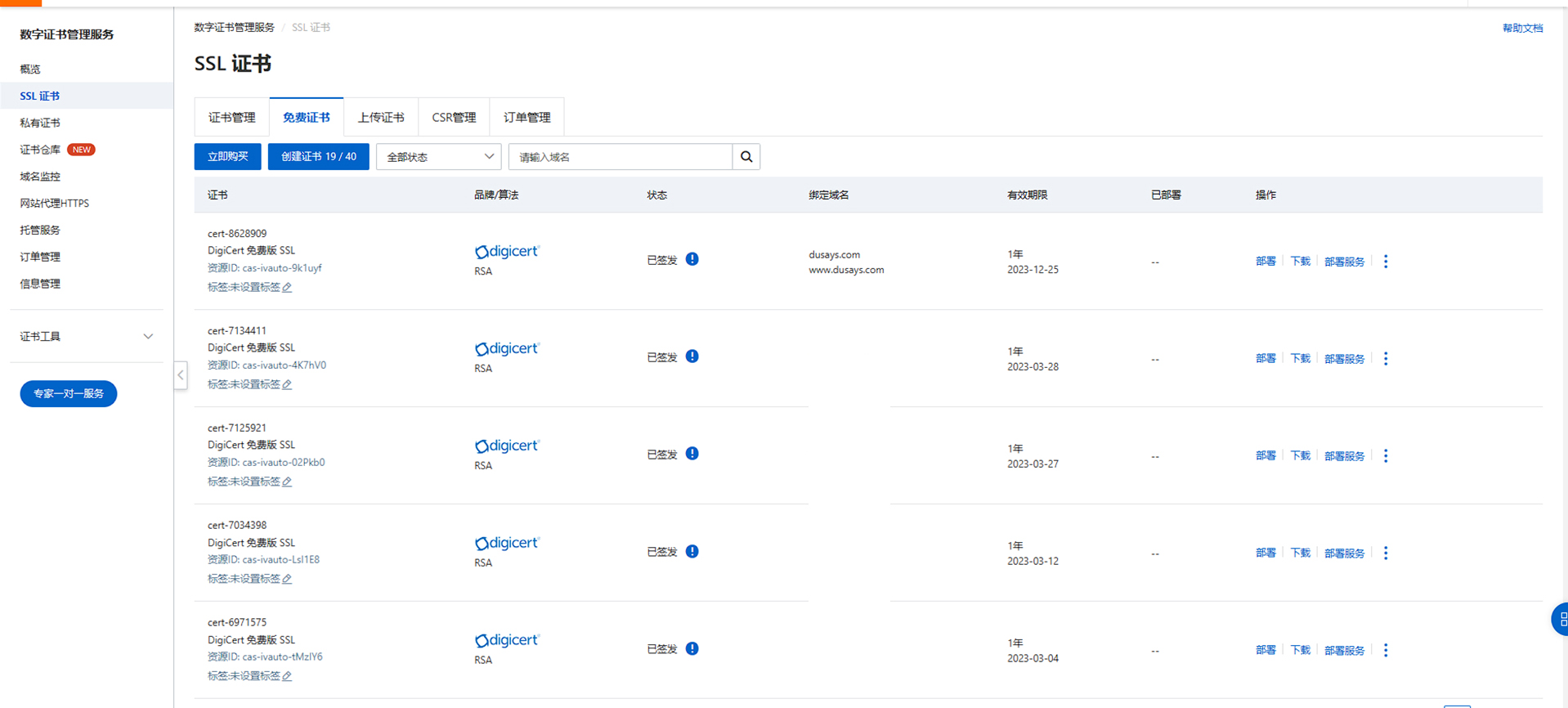
现在很多平台都在提供免费证书,常见的有 SSL For Free 及一些大厂,两者的区别是:SSL For Free 只能使用三个月,但是支持无限续期;其它大厂每次申请可用一年,不过不能续期,到期后需重新申请,且有申请限制,目前套路云和凉心云每年有 20 个申请名额,其它平台暂未关注,还请小伙伴们补充:
NAT 是英文 Network Address Translation 的简写,中文意为网络地址转换。当在专用网内部的一些主机本来已经分配到了本地 IP 地址即仅在本专用网内使用的专用地址,但又想和因特网上的主机通信并不需要加密时,可使用 NAT 方法。
这种方法需要在专用网私网 IP 连接到因特网公网 IP 的路由器上安装 NAT 软件。装有 NAT 软件的路由叫做 NAT 路由器,它至少有一个有效外部全球 IP 地址公网 IP 地址。这样,所有使用本地地址私网 IP 地址的主机和外界通信时,都要在 NAT 路由器上将其本地地址转换成全球 IP 地址,才能和因特网连接。
另外,这种通过使用少量的全球 IP 地址公网 IP 地址代表较多的私有 IP 地址的方式,将有助于减缓可用的 IP 地址空间枯竭。在 RFC 2663 中有对 NAT 说明。
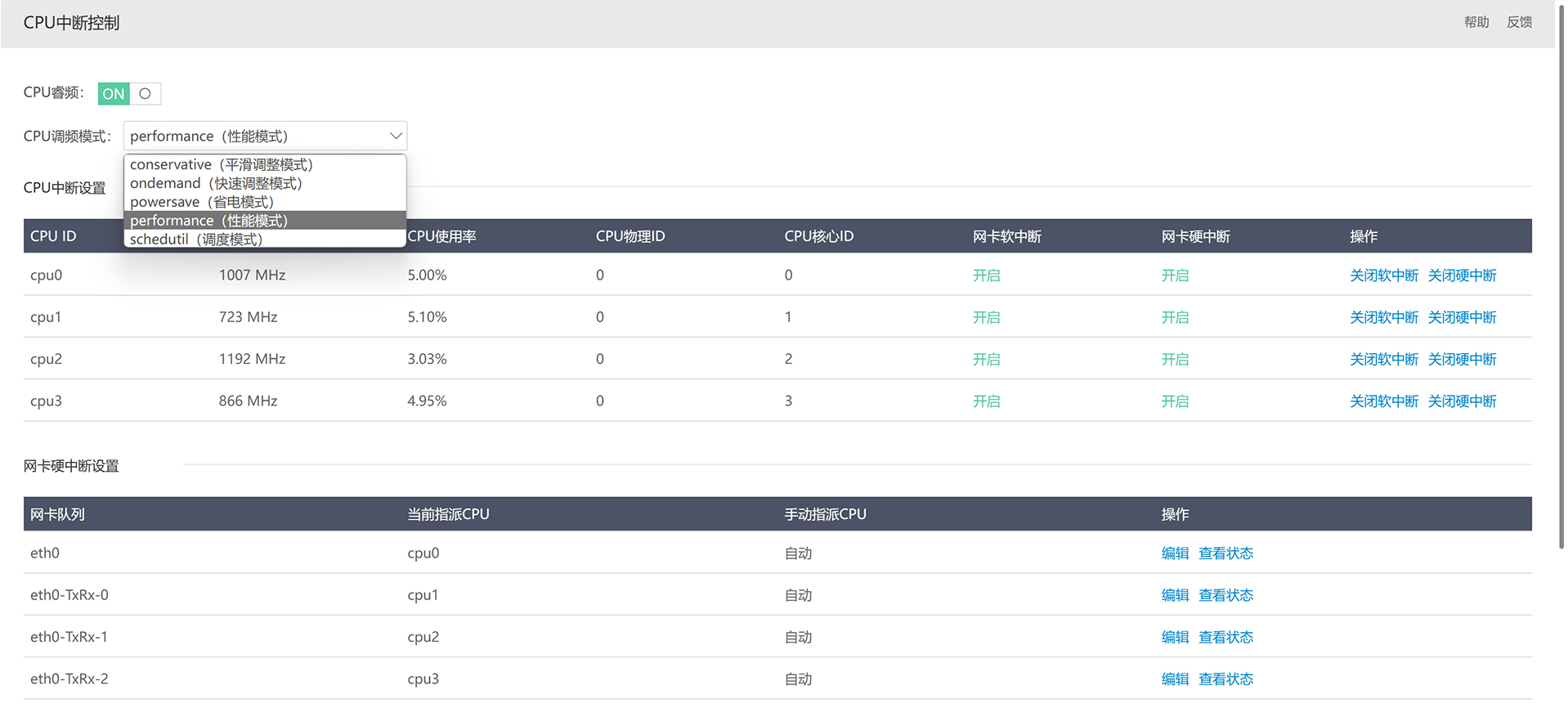
指定容器在一个 CFS 调度周期中可使用 CPU 的时间,单位毫秒。通常和--cpu-period=VALUE 一起使用,一般使用--cpus=VALUE 更方便。
--cpuset-cpus=VALUE:
限制容器可以使用指定的 CPU。如果有多个 CPU,可以以逗号分隔或者使用连字符进行指定。
--cpu-shares=VALUE:
容器使用 CPU 的权重,默认是1024,不设置或者将其设置为 0 都将使用默认值,数值越大权重越大。这是个软限制,只有 CPU 资源不足时才会生效。当 CPU 的资源充足时,各个容器可在不超过资源限制的条件下使用 CPU 资源;当 CPU 资源不足,并有多个容器竞争 CPU 资源时,系统会根据每个容器的权值和所有容器权值的比例来给容器分配 CPU 的使用时间,如果器 A 设置为--cpu-shares=2048,容器 B 设置 --cpu-shares=1024,则容器 A 会被分配约 66%的 CPU 时间,容器 B 被分配约 33%的 CPU 时间。
--cap-add=sys_nice:
赋予容器 CAP_SYS_NICE 的能力,允许容器增加进程的友好值、设置实时调度策略、设置 CPU 亲和性和其它的操作。














 Grok (X.AI) Python 人工智能 (AI) 折腾 教娃 教程 教育 程序员 程序设计")
 Grok (X.AI) Python 人工智能 (AI) 折腾 教娃 教程 教育 程序员 程序设计")
 Grok (X.AI) Python 人工智能 (AI) 折腾 教娃 教程 教育 程序员 程序设计")
 Grok (X.AI) Python 人工智能 (AI) 折腾 教娃 教程 教育 程序员 程序设计")
 Grok (X.AI) Python 人工智能 (AI) 折腾 教娃 教程 教育 程序员 程序设计")
 Grok (X.AI) Python 人工智能 (AI) 折腾 教娃 教程 教育 程序员 程序设计")
 Grok (X.AI) Python 人工智能 (AI) 折腾 教娃 教程 教育 程序员 程序设计")


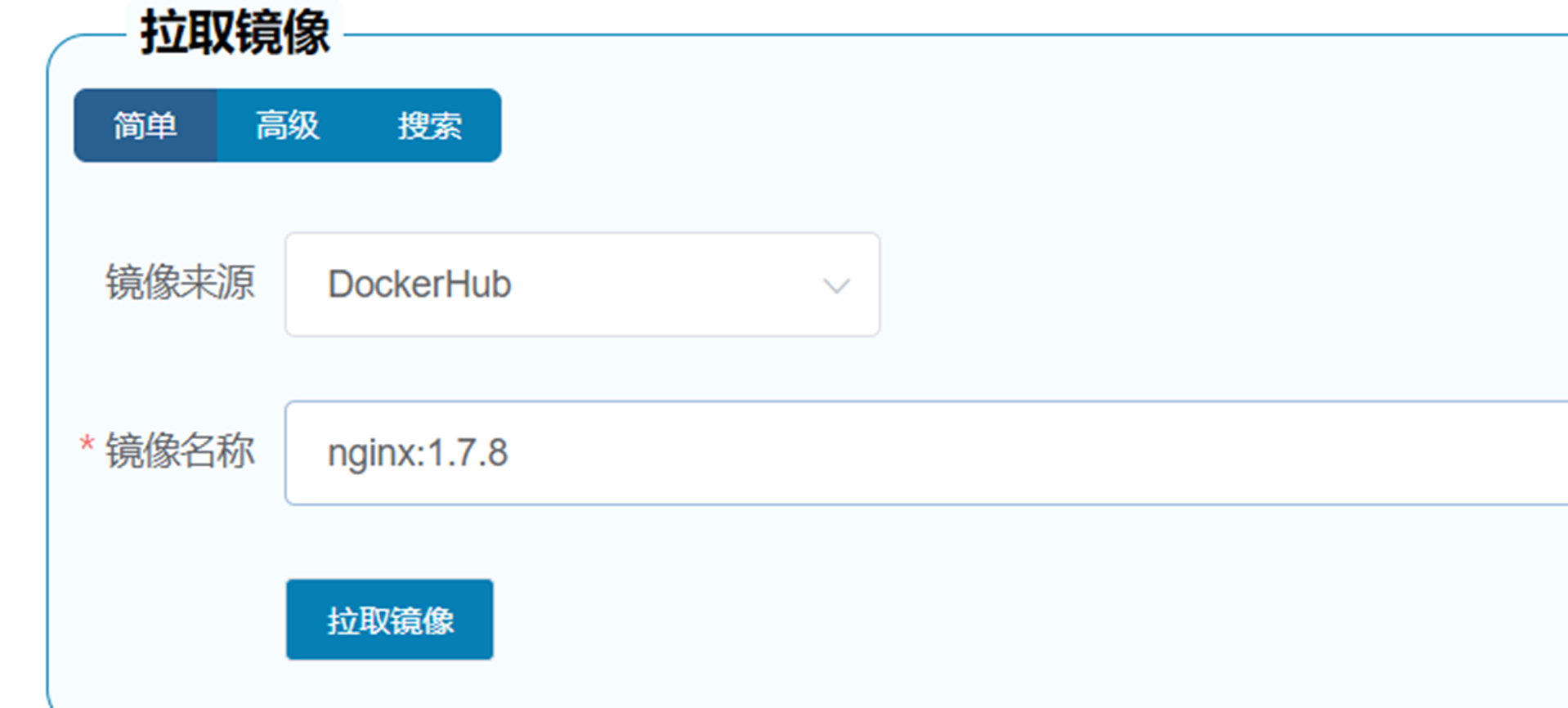
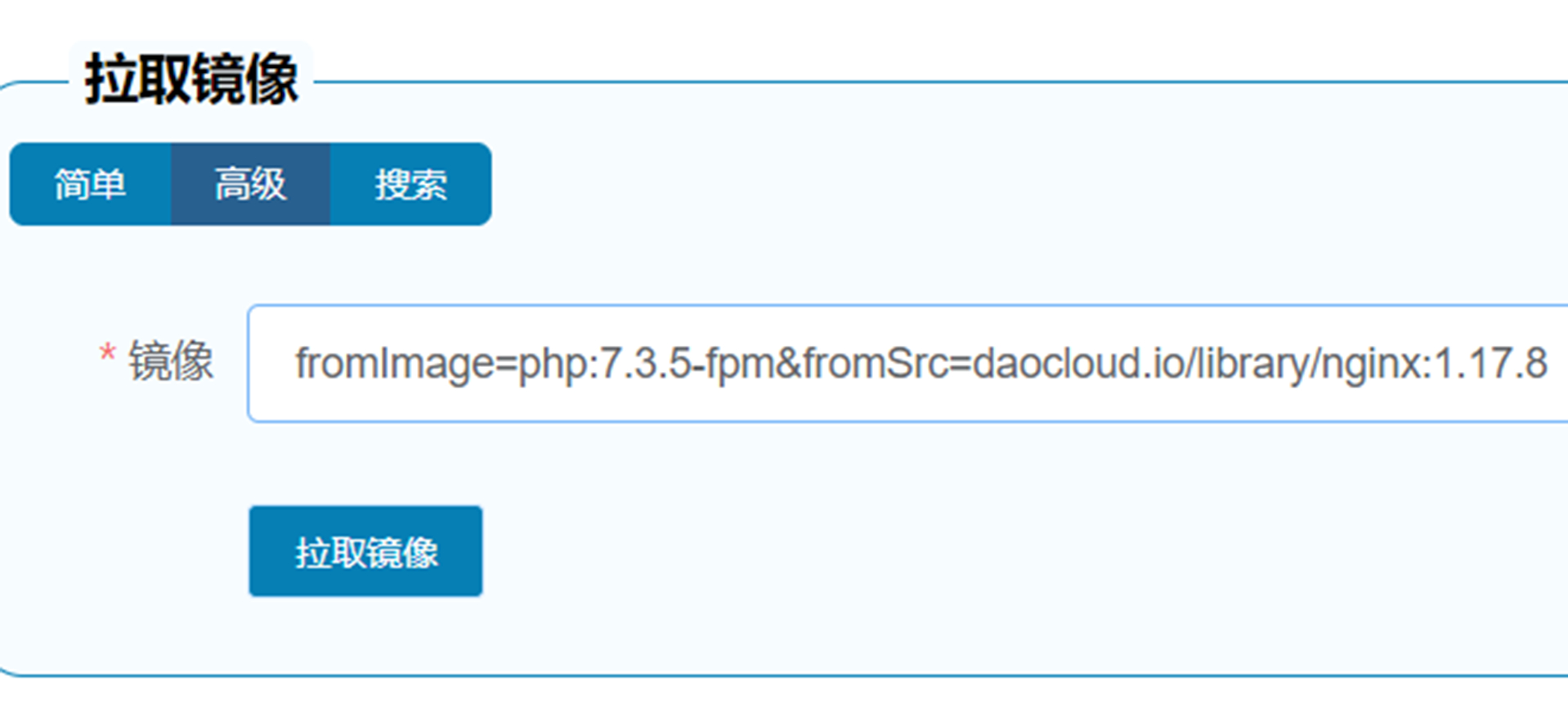
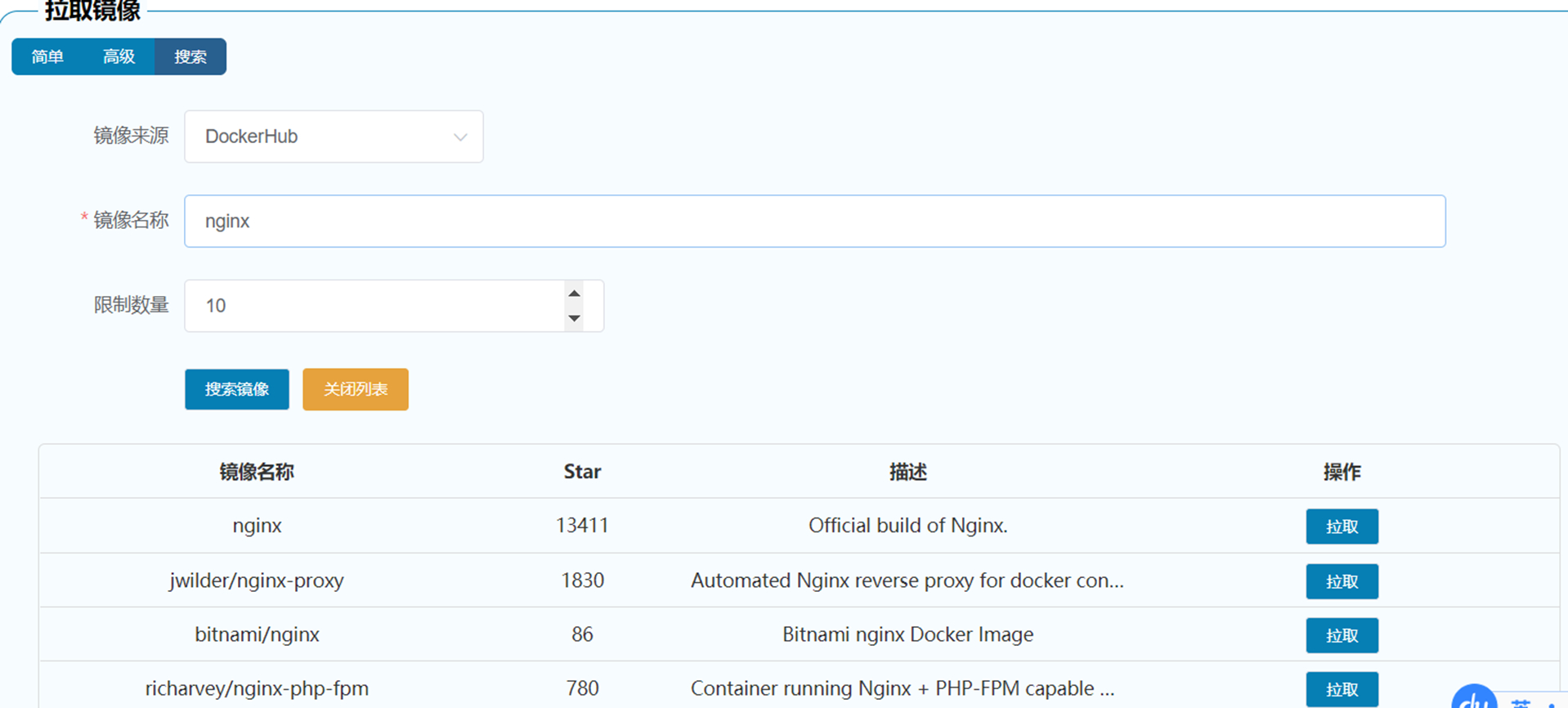














{kind=link}