# 遍历目录 A for filename in os.listdir(dir_a): file_a_path = os.path.join(dir_a, filename) # 检查是否为图片 if not filename.lower().endswith(('.png', '.jpg', '.jpeg', '.gif', '.bmp')): continue hash_a = get_image_hash(file_a_path) if hash_a is None: continue
# 遍历目录 B 寻找相似图片 for b_filename in os.listdir(dir_b): file_b_path = os.path.join(dir_b, b_filename) # 检查是否为图片 if not b_filename.lower().endswith(('.png', '.jpg', '.jpeg', '.gif', '.bmp')): continue hash_b = get_image_hash(file_b_path) if hash_b is None: continue
def download_images(url, save_folder): # 确保保存目录存在 if not os.path.exists(save_folder): os.makedirs(save_folder)
# 发送HTTP请求获取网页内容 response = requests.get(url) if response.status_code != 200: print(f"Failed to retrieve the webpage. Status code: {response.status_code}") return
# 保存图片 with open(save_path, 'wb') as f: f.write(img_response.content) print(f"Downloaded and saved {img_url} as {save_path}") else: print(f"Failed to download {img_url}. Status code: {img_response.status_code}")
# 读取网址列表文件 def read_urls_from_file(file_path): with open(file_path, 'r') as file: urls = file.readlines() return [url.strip() for url in urls]
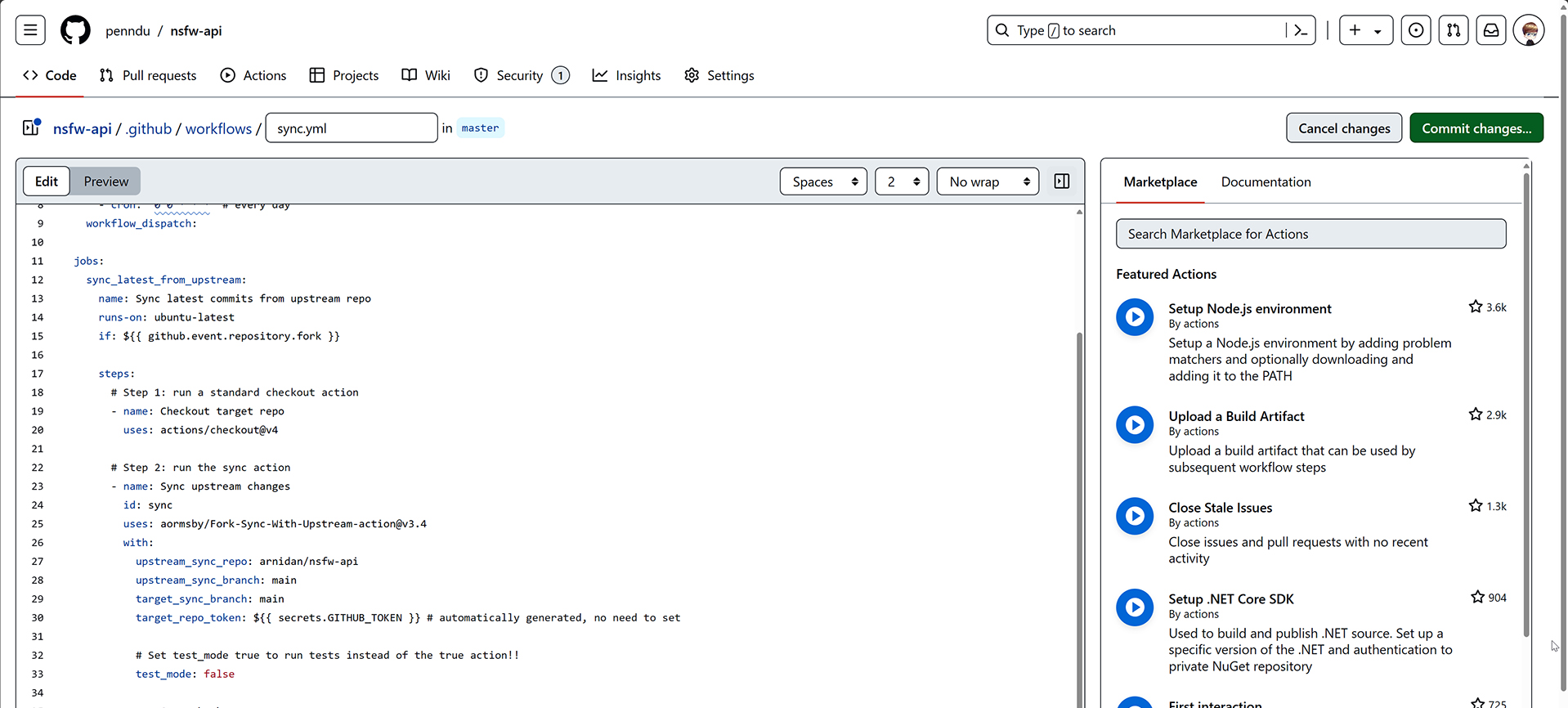
steps: # Step 1: run a standard checkout action -name:Checkouttargetrepo uses:actions/checkout@v4
# Step 2: run the sync action -name:Syncupstreamchanges id:sync uses:aormsby/Fork-Sync-With-Upstream-action@v3.4 with: upstream_sync_repo:arnidan/nsfw-api upstream_sync_branch:main target_sync_branch:main target_repo_token:${{secrets.GITHUB_TOKEN}}# automatically generated, no need to set
# Set test_mode true to run tests instead of the true action!! test_mode:false
-name:Synccheck if:failure() run:| echo "[Error] 由于上游仓库的 workflow 文件变更,导致 GitHub 自动暂停了本次自动更新,您需要手动 Sync Fork 一次。" echo "[Error] Due to a change in the workflow file of the upstream repository, GitHub has automatically suspended the scheduled automatic update. You need to manually sync your fork." exit 1
for DB in$DB_LIST; do BACKUP_NAME=$BACKUP_DIR/${DB}_${DATE}.sql if ! mysqldump -h$HOST -u$USER -p$PASS -B $DB >$BACKUP_NAME 2>/dev/null; then echo"$BACKUP_NAME 备份失败!" fi done
#禁用 SELinux 防火墙 sed -i '/SELINUX/{s/permissive/disabled/}' /etc/selinux/config
#关闭各版本防火墙 if egrep "7.[0-9]" /etc/redhat-release &>/dev/null; then systemctl stop firewalld systemctl disable firewalld elif egrep "6.[0-9]" /etc/redhat-release &>/dev/null; then service iptables stop chkconfig iptables off fi
#历史命令显示操作时间 if ! grep HISTTIMEFORMAT /etc/bashrc; then echo'export HISTTIMEFORMAT="%F %T `whoami` "' >>/etc/bashrc fi
#SSH 的超时时间 if ! grep "TMOUT=600" /etc/profile &>/dev/null; then echo"export TMOUT=600" >>/etc/profile fi
#禁止 root 的远程登录 sed -i 's/#PermitRootLogin yes/PermitRootLogin no/' /etc/ssh/sshd_config
#禁止定时任务发送邮件 sed -i 's/^MAILTO=root/MAILTO=""/' /etc/crontab
#设置最大打开的文件数 if ! grep "* soft nofile 65535" /etc/security/limits.conf &>/dev/null; then cat >>/etc/security/limits.conf <<EOF * soft nofile 65535 * hard nofile 65535 EOF fi
编写脚本,给系统中所有已存在的用户打个招呼,格式参考为 hello penndu and your id is 1000。
参考答案
一题:
1 2 3 4 5 6 7
#!/bin/bash sum=0 for i in `seq 1 100` do sum=$[$i+$sum] done echo$sum
二题:
1 2 3 4 5 6 7 8 9 10 11 12
#!/bin/bash n=0 while [ $n -lt 1 ] do read -p "Please input a number, it must greater than 1: " n done sum=0 for i in `seq 1 $n` do sum=$[$i+$sum] done echo$sum
三题:
1 2 3 4 5 6 7 8
#!/bin/bash cd /root/ for f in `ls` do if[ -d $f ] ; then cd -r $f /tmp/ fi done
四题:
1 2 3 4 5 6
#!/bin/bash groupadd users for i in `seq -w 0 99` do useradd -g users user_$i done
五题:
1 2 3 4 5 6 7 8
#!/bin/bash cd /cjk/ for f in `ls` do if[ -f $f ] ; then mv$f$f.bak fi done
六题:
1 2 3 4 5 6 7
#!/bin/bash for i in `cat /etc/passwd` do username=`echo$i | cut -d : -f 1` id=`echo$i | cut -d : -f 3` echo"hello $username and your id is $id" done

{kind=link}