广播,顾名思义就是把一个信息传播出去,在Android中也提供了广播和广播接收器BroadcastReceiver,用来监听特定的事件和发送特定的消息。不过广播分为全局广播和本地广播,本地广播是在Android Jetpack库中所提供,其实现也是基于Handler和消息循环机制,并且这个类Android官方也不推荐使用了。我们这里就来看看Android全局的这个广播。
应用开发者可以自己发送特定的广播,而更多场景则是接收系统发送的广播。注册广播接收器有在AndroidManifest文件中声明和使用代码注册两种方式,在应用的target sdk大于等于Android 8.0(Api Version 26)之后,系统会限制在清单文件中注册。通过清单方式注册的广播,代码中没有注册逻辑,只有PMS中读取它的逻辑,我们这里不进行分析。
注册广播接收器
首先是注册广播接收器,一般注册一个广播接收器的代码如下:
1
2
3
|
val br: BroadcastReceiver = MyBroadcastReceiver()
val filter = IntentFilter(ACTION_CHARGING)
activity.registerReceiver(br, filter)
|
使用上面的代码就能注册一个广播接收器,当手机开始充电就会收到通知,会去执行MyBroadcastReceiver的onReceive方法。
那我们就从这个registerReceiver来时往里面看,因为Activity是Context的子类,这个注册的方法的实现则是在ContextImpl当中,其中最终调用的方法为registerReceiverInternal,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
private Intent registerReceiverInternal(BroadcastReceiver receiver, int userId,
IntentFilter filter, String broadcastPermission,
Handler scheduler, Context context, int flags) {
IIntentReceiver rd = null;
if (receiver != null) {
if (mPackageInfo != null && context != null) {
if (scheduler == null) {
scheduler = mMainThread.getHandler();
}
rd = mPackageInfo.getReceiverDispatcher(
receiver, context, scheduler,
mMainThread.getInstrumentation(), true);
} else {
...
}
}
try {
ActivityThread thread = ActivityThread.currentActivityThread();
Instrumentation instrumentation = thread.getInstrumentation();
if (instrumentation.isInstrumenting()
&& ((flags & Context.RECEIVER_NOT_EXPORTED) == 0)) {
flags = flags | Context.RECEIVER_EXPORTED;
}
final Intent intent = ActivityManager.getService().registerReceiverWithFeature(
mMainThread.getApplicationThread(), mBasePackageName, getAttributionTag(),
AppOpsManager.toReceiverId(receiver), rd, filter, broadcastPermission, userId,
flags);
if (intent != null) {
intent.setExtrasClassLoader(getClassLoader());
intent.prepareToEnterProcess(
ActivityThread.isProtectedBroadcast(intent),
getAttributionSource());
}
return intent;
} catch (RemoteException e) {
...
}
}
|
我们在注册广播的时候只传了两个参数,但是实际上它还可以传不少的参数,这里userId就是注册的用户id,会被自动 填充成当前进程的用户Id,broadcastPermission表示这个广播的权限,也就是说需要有该权限的应用发送的广播,这个接收者才能接收到。scheduler就是一个Handler,默认不传,在第8行可以看到,会拿当前进程的主线程的Handler,flag是广播的参数,这里比较重要的就是RECEIVER_NOT_EXPORTED,添加了它则广播不会公开暴露,其他应用发送的消息不会被接收。
在第10行,这里创建了一个广播的分发器,在24行,通过AMS去注册广播接收器,只有我们的broadcast会用到contentprovider或者有sticky广播的时候,30行才会执行到,这里跳过。
获取广播分发器
首先来看如何获取广播分发器,这块的代码在LoadedApk.java中,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
public IIntentReceiver getReceiverDispatcher(BroadcastReceiver r,
Context context, Handler handler,
Instrumentation instrumentation, boolean registered) {
synchronized (mReceivers) {
LoadedApk.ReceiverDispatcher rd = null;
ArrayMap<BroadcastReceiver, LoadedApk.ReceiverDispatcher> map = null;
if (registered) {
map = mReceivers.get(context);
if (map != null) {
rd = map.get(r);
}
}
if (rd == null) {
rd = new ReceiverDispatcher(r, context, handler,
instrumentation, registered);
if (registered) {
if (map == null) {
map = new ArrayMap<BroadcastReceiver, LoadedApk.ReceiverDispatcher>();
mReceivers.put(context, map);
}
map.put(r, rd);
}
} else {
rd.validate(context, handler);
}
rd.mForgotten = false;
return rd.getIIntentReceiver();
}
}
|
先来说一下mReceivers,它的结构为ArrayMap<Context, ArrayMap<BroadcastReceiver, ReceiverDispatcher>>,也就是嵌套了两层的ArrayMap,外层是以Context为key,内层以Receiver为key,实际存储的为ReceiverDispatcher。ReceiverDispatcher内部所放的IIntentReceiver比较重要,也就是我们这个方法所返回的值,它实际是IIntentReceiver.Stub,也就是它的Binder实体类。
这段代码的逻辑也比较清晰,就是根据Context和Receiver到map中去查找看是否之前注册过,如果注册过就已经有这个Dispatcher了,如果没有就创建一个,并且放到map中去,最后返回binder对象出去。
AMS注册广播接收器
在AMS注册的代码很长,我们这里主要研究正常的普通广播注册,关于黏性广播,instantApp的广播,以及广播是否导出等方面都省略不予研究。以下为我们关注的核心代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
public Intent registerReceiverWithFeature(IApplicationThread caller, String callerPackage,
String callerFeatureId, String receiverId, IIntentReceiver receiver,
IntentFilter filter, String permission, int userId, int flags) {
...
synchronized(this) {
ReceiverList rl = mRegisteredReceivers.get(receiver.asBinder());
if (rl == null) {
rl = new ReceiverList(this, callerApp, callingPid, callingUid,
userId, receiver);
if (rl.app != null) {
final int totalReceiversForApp = rl.app.mReceivers.numberOfReceivers();
if (totalReceiversForApp >= MAX_RECEIVERS_ALLOWED_PER_APP) {
throw new IllegalStateException("Too many receivers, total of "
+ totalReceiversForApp + ", registered for pid: "
+ rl.pid + ", callerPackage: " + callerPackage);
}
rl.app.mReceivers.addReceiver(rl);
} else {
try {
receiver.asBinder().linkToDeath(rl, 0);
} catch (RemoteException e) {
return sticky;
}
rl.linkedToDeath = true;
}
mRegisteredReceivers.put(receiver.asBinder(), rl);
} else {
// 处理userId, uid,pid 等不同的错误
}
BroadcastFilter bf = new BroadcastFilter(filter, rl, callerPackage, callerFeatureId,
receiverId, permission, callingUid, userId, instantApp, visibleToInstantApps,
exported);
if (rl.containsFilter(filter)) {
} else {
rl.add(bf);
mReceiverResolver.addFilter(getPackageManagerInternal().snapshot(), bf);
}
}
...
}
|
在前面ContextImpl中调用AMS注册Reciever的地方,我们传的就是Receiver的Binder实体,这里拿到的是binder引用。在代码中我们可以看到,首先会以我们传过来的receiver的binder对象为key,到mRegisterReceivers当中去获取ReceiverList,这里我们就知道receiver在System_server中是怎样存储的了。如果AMS当中没有,会去创建一个ReceiverList并放置到这个map当中去,如果存在则不需要做什么事情。但是这一步只是放置了Receiver,而我们的Receiver对应的关心的IntentFilter还没使用,这里就需要继续看31行的代码了。在这里这是使用了我们传过来的IntentFilter创建了一个BroadcastFilter对象,并且把它放到了ReceiverList当中,同时还放到了mReceiverResolver当中,这个对象它不是一个Map而是一个IntentResolver,其中会存储我们的BroadcastFilter,具体这里先不分析了。

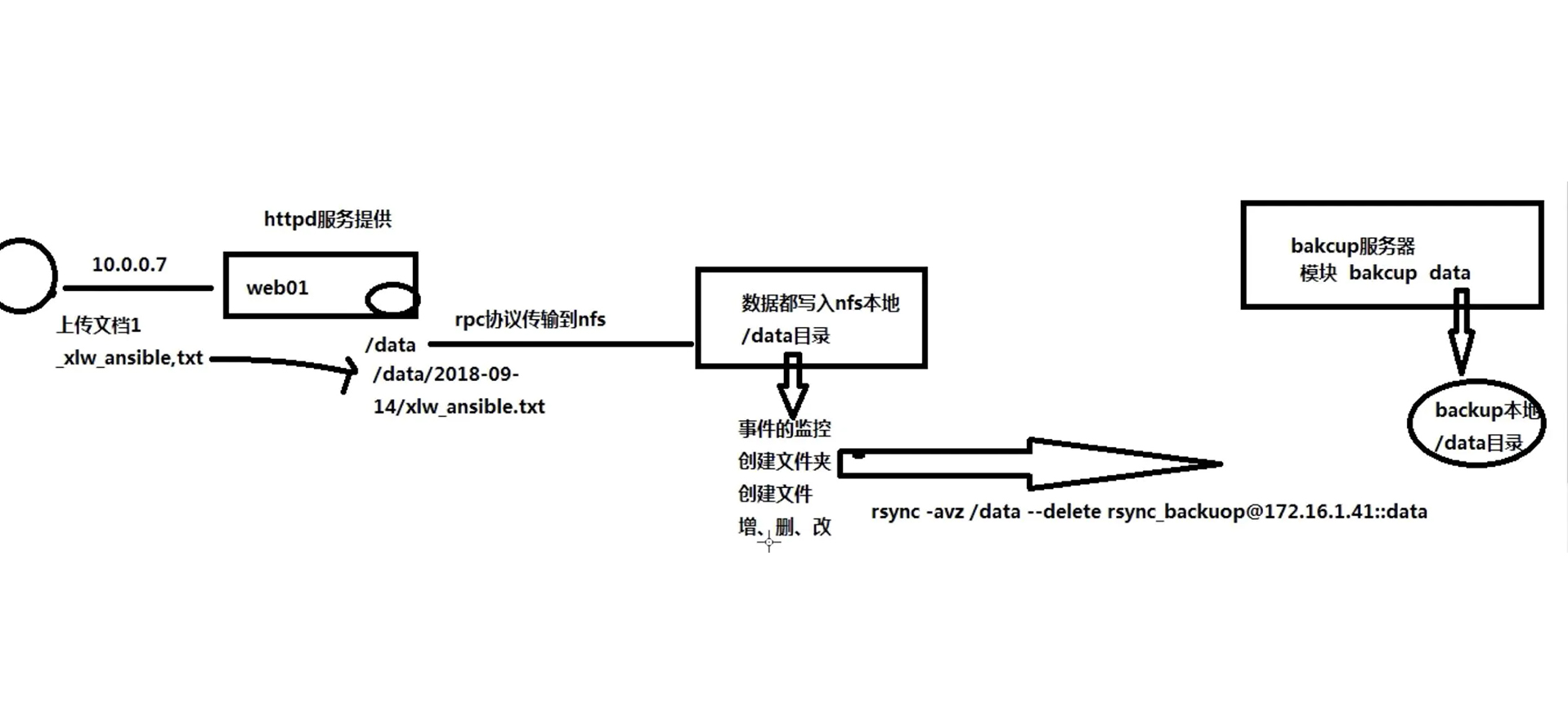
到这里我们就看完了广播接收器的注册,在App进程和System_Server中分别将其存储,具体两边的数据结构如上图所示。这里可以继续看看发送广播的流程了。
发送广播
一般我们发送广播会调用如下的代码:
1
2
3
4
5
|
Intent().also { intent ->
intent.setAction("com.example.broadcast.MY_NOTIFICATION")
intent.putExtra("data", "Nothing to see here, move along.")
activity.sendBroadcast(intent)
}
|
我们通过设置Action来匹配对应的广播接收器,通过设置Data或者Extra,这样广播接收器中可以接收到对应的数据,最后调用sendBroadcast来发送。而sendBroadcast的实现也是在ContextImpl中,源码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
@Override
public void sendBroadcast(Intent intent) {
warnIfCallingFromSystemProcess();
String resolvedType = intent.resolveTypeIfNeeded(getContentResolver());
try {
intent.prepareToLeaveProcess(this);
ActivityManager.getService().broadcastIntentWithFeature(
mMainThread.getApplicationThread(), getAttributionTag(), intent, resolvedType,
null, Activity.RESULT_OK, null, null, null, null /*excludedPermissions=*/,
null, AppOpsManager.OP_NONE, null, false, false, getUserId());
} catch (RemoteException e) {
throw e.rethrowFromSystemServer();
}
}
|
这里代码比较简单,就是直接调用AMS的broadcastIntentWithFeature来发送广播。
AMS发送广播
这里我们可以直接看AMS中的broadcastIntentWithFeature的源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
@Override
public final int broadcastIntentWithFeature(IApplicationThread caller, String callingFeatureId,
Intent intent, String resolvedType, IIntentReceiver resultTo,
int resultCode, String resultData, Bundle resultExtras,
String[] requiredPermissions, String[] excludedPermissions,
String[] excludedPackages, int appOp, Bundle bOptions,
boolean serialized, boolean sticky, int userId) {
enforceNotIsolatedCaller("broadcastIntent");
synchronized(this) {
intent = verifyBroadcastLocked(intent);
final ProcessRecord callerApp = getRecordForAppLOSP(caller);
final int callingPid = Binder.getCallingPid();
final int callingUid = Binder.getCallingUid();
final long origId = Binder.clearCallingIdentity();
try {
return broadcastIntentLocked(callerApp,
callerApp != null ? callerApp.info.packageName : null, callingFeatureId,
intent, resolvedType, resultTo, resultCode, resultData, resultExtras,
requiredPermissions, excludedPermissions, excludedPackages, appOp, bOptions,
serialized, sticky, callingPid, callingUid, callingUid, callingPid, userId);
} finally {
Binder.restoreCallingIdentity(origId);
}
}
}
|
第10行代码,主要验证Intent,比如检查它的Flag,检查它是否传文件描述符之类的,里面的代码比较简单清晰,这里不单独看了。后面则是获取调用者的进程,uid,pid之类的,最后调用broadcastIntentLocked,这个方法的代码巨多,接近1000行代码,我们同样忽略sticky的广播,也忽略顺序广播,然后来一点一点的看:
1
2
3
4
5
6
7
8
9
10
|
//ActivityManagerService.java
//final int broadcastIntentLocked(...)
intent = new Intent(intent);
intent.addFlags(Intent.FLAG_EXCLUDE_STOPPED_PACKAGES);
if (!mProcessesReady && (intent.getFlags()&Intent.FLAG_RECEIVER_BOOT_UPGRADE) == 0) {
intent.addFlags(Intent.FLAG_RECEIVER_REGISTERED_ONLY);
}
userId = mUserController.handleIncomingUser(callingPid, callingUid, userId, true,
ALLOW_NON_FULL, "broadcast", callerPackage);
final String action = intent.getAction();
|
首先这里的代码是对Intent做一下封装,并且如果系统还在启动,不允许启动应用进程,以及获取当前的用户ID,大部分情况下,我们只需要考虑一个用户的情况。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
if (action != null) {
...
switch (action) {
...
case Intent.ACTION_PACKAGE_DATA_CLEARED:
{
Uri data = intent.getData();
String ssp;
if (data != null && (ssp = data.getSchemeSpecificPart()) != null) {
mAtmInternal.onPackageDataCleared(ssp, userId);
}
break;
}
case Intent.ACTION_TIMEZONE_CHANGED:
mHandler.sendEmptyMessage(UPDATE_TIME_ZONE);
break;
...
}
}
|
对于一些系统的广播事件,除了要发送广播给应用之外,在AMS中,还会根据其广播,来调用相关的服务或者执行相关的逻辑,也会在这里调用其代码。这里我罗列了清除应用数据和时区变化两个广播,其他的感兴趣的可以自行阅读相关代码。
1
2
3
4
5
6
|
int[] users;
if (userId == UserHandle.USER_ALL) {
users = mUserController.getStartedUserArray();
} else {
users = new int[] {userId};
}
|
以上代码为根据前面拿到的userId,来决定广播要发送给所有人还是仅仅发送给当前用户,并且把userId保存到users数组当中。
获取广播接收者
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
List receivers = null;
List<BroadcastFilter> registeredReceivers = null;
if ((intent.getFlags() & Intent.FLAG_RECEIVER_REGISTERED_ONLY) == 0) {
receivers = collectReceiverComponents(
intent, resolvedType, callingUid, users, broadcastAllowList);
}
if (intent.getComponent() == null) {
final PackageDataSnapshot snapshot = getPackageManagerInternal().snapshot();
if (userId == UserHandle.USER_ALL && callingUid == SHELL_UID) {
...
} else {
registeredReceivers = mReceiverResolver.queryIntent(snapshot, intent,
resolvedType, false /*defaultOnly*/, userId);
}
}
|
以上为获取我们注册的所有的接收器的代码,其中FLAG_RECEIVER_REGISTERED_ONLY意味着仅仅接收注册过的广播,前面在判断当前系统还未启动完成的时候有添加这个FLAG,其他情况一般不会有这个Flag,这里我们按照没有这个flag处理。那也就会执行第4行的代码。另外下面还有从mReceiverResolver从获取注册的接收器的代码,因为大部分情况不是从shell中执行的,因此也忽略了其代码。
首先看collectReceiverComponents的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
|
private List<ResolveInfo> collectReceiverComponents(Intent intent, String resolvedType,
int callingUid, int[] users, int[] broadcastAllowList) {
int pmFlags = STOCK_PM_FLAGS | MATCH_DEBUG_TRIAGED_MISSING;
List<ResolveInfo> receivers = null;
HashSet<ComponentName> singleUserReceivers = null;
boolean scannedFirstReceivers = false;
for (int user : users) {
List<ResolveInfo> newReceivers = mPackageManagerInt.queryIntentReceivers(
intent, resolvedType, pmFlags, callingUid, user, true /* forSend */); //通过PMS,根据intent和uid读取Manifest中注册的接收器
if (user != UserHandle.USER_SYSTEM && newReceivers != null) {
for (int i = 0; i < newReceivers.size(); i++) {
ResolveInfo ri = newReceivers.get(i);
//如果调用不是系统用户,移除只允许系统用户接收的接收器
if ((ri.activityInfo.flags & ActivityInfo.FLAG_SYSTEM_USER_ONLY) != 0) {
newReceivers.remove(i);
i--;
}
}
}
// 把别名替换成真实的接收器
if (newReceivers != null) {
for (int i = newReceivers.size() - 1; i >= 0; i--) {
final ResolveInfo ri = newReceivers.get(i);
final Resolution<ResolveInfo> resolution =
mComponentAliasResolver.resolveReceiver(intent, ri, resolvedType,
pmFlags, user, callingUid, true /* forSend */);
if (resolution == null) {
// 未找到对应的接收器,删除这个记录
newReceivers.remove(i);
continue;
}
if (resolution.isAlias()) {
//找到对应的真实的接收器,就把别名的记录替换成真实的目标
newReceivers.set(i, resolution.getTarget());
}
}
}
if (newReceivers != null && newReceivers.size() == 0) {
newReceivers = null;
}
if (receivers == null) {
receivers = newReceivers;
} else if (newReceivers != null) {
if (!scannedFirstReceivers) {
//查找单用户记录的接收器,并且保存
scannedFirstReceivers = true;
for (int i = 0; i < receivers.size(); i++) {
ResolveInfo ri = receivers.get(i);
if ((ri.activityInfo.flags&ActivityInfo.FLAG_SINGLE_USER) != 0) {
ComponentName cn = new ComponentName(
ri.activityInfo.packageName, ri.activityInfo.name);
if (singleUserReceivers == null) {
singleUserReceivers = new HashSet<ComponentName>();
}
singleUserReceivers.add(cn);
}
}
}
for (int i = 0; i < newReceivers.size(); i++) {
ResolveInfo ri = newReceivers.get(i);
if ((ri.activityInfo.flags & ActivityInfo.FLAG_SINGLE_USER) != 0) {
ComponentName cn = new ComponentName(
ri.activityInfo.packageName, ri.activityInfo.name);
if (singleUserReceivers == null) {
singleUserReceivers = new HashSet<ComponentName>();
}
if (!singleUserReceivers.contains(cn)) {
//对于单用户的接收器,只存一次到返回结果中
singleUserReceivers.add(cn);
receivers.add(ri);
}
} else {
receivers.add(ri);
}
}
}
}
...
return receivers;
}
|
以上就根据信息通过PMS获取所有通过Manifest静态注册的广播接收器,对其有一些处理,详见上面的注释。
对于我们在代码中动态注册的接收器,则需要看mReceiverResolver.queryIntent的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
protected final List<R> queryIntent(@NonNull PackageDataSnapshot snapshot, Intent intent,
String resolvedType, boolean defaultOnly, @UserIdInt int userId, long customFlags) {
ArrayList<R> finalList = new ArrayList<R>();
F[] firstTypeCut = null;
F[] secondTypeCut = null;
F[] thirdTypeCut = null;
F[] schemeCut = null;
if (resolvedType == null && scheme == null && intent.getAction() != null) {
firstTypeCut = mActionToFilter.get(intent.getAction());
}
FastImmutableArraySet<String> categories = getFastIntentCategories(intent);
Computer computer = (Computer) snapshot;
if (firstTypeCut != null) {
buildResolveList(computer, intent, categories, debug, defaultOnly, resolvedType,
scheme, firstTypeCut, finalList, userId, customFlags);
}
sortResults(finalList); //按照IntentFilter的priority优先级降序排序
return finalList;
}
|
以上代码中,这个mActionToFilter就是我们前面注册广播时候,将BroadcastFilter添加进去的一个ArrayMap,这里会根据Action去其中取出所有的BroadcastFilter,之后调用buildResolveList将其中的不符合本次广播接收要求的广播接收器给过滤掉,最后按照IntentFilter的优先级降序排列。
到这里我们就有两个列表receivers存放Manifest静态注册的将要本次广播接收者,和registeredReceivers通过代码手动注册的广播接收者。
广播入队列
首先来看通过代码注册的接收器不为空,并且不是有序广播的情况,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
int NR = registeredReceivers != null ? registeredReceivers.size() : 0;
if (!ordered && NR > 0) {
...
final BroadcastQueue queue = broadcastQueueForIntent(intent);
BroadcastRecord r = new BroadcastRecord(queue, intent, callerApp, callerPackage,
callerFeatureId, callingPid, callingUid, callerInstantApp, resolvedType,
requiredPermissions, excludedPermissions, excludedPackages, appOp, brOptions,
registeredReceivers, resultTo, resultCode, resultData, resultExtras, ordered,
sticky, false, userId, allowBackgroundActivityStarts,
backgroundActivityStartsToken, timeoutExempt);
...
final boolean replaced = replacePending
&& (queue.replaceParallelBroadcastLocked(r) != null);
if (!replaced) {
queue.enqueueParallelBroadcastLocked(r);
queue.scheduleBroadcastsLocked();
}
registeredReceivers = null;
NR = 0;
}
|
在这里,第4行会首先根据intent的flag获取对应的BroadcastQueue,这里有四个Queue,不看其代码了,不过逻辑如下:
- 如果有
FLAG_RECEIVER_OFFLOAD_FOREGROUND 标记,则使用mFgOffloadBroadcastQueue。
- 如果当前开启了offloadQueue,也就是
mEnableOffloadQueue,并且有FLAG_RECEIVER_OFFLOAD标记,则使用mBgOffloadBroadcastQueue。
- 如果有
FLAG_RECEIVER_FOREGROUND,也就是前台时候才接收广播,则使用mFgBroadcastQueue。
- 如果没有上述标记,则使用
mBgBroadcastQueue。
拿到queue之后,会创建一条BroadcastRecord,其中会记录传入的参数,intent,以及接收的registeredReceivers,调用queue的入队方法,最后把registeredReceivers设置为null,计数也清零。具体入队的代码,我们随后再看,这里先看其他情况下的广播入队代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
int ir = 0;
if (receivers != null) {
String skipPackages[] = null;
//对于添加应用,删除应用数据之类的广播,不希望变化的应用能够接收到对应的广播
//这里设置忽略它们
if (Intent.ACTION_PACKAGE_ADDED.equals(intent.getAction())
|| Intent.ACTION_PACKAGE_RESTARTED.equals(intent.getAction())
|| Intent.ACTION_PACKAGE_DATA_CLEARED.equals(intent.getAction())) {
Uri data = intent.getData();
if (data != null) {
String pkgName = data.getSchemeSpecificPart();
if (pkgName != null) {
skipPackages = new String[] { pkgName };
}
}
} else if (Intent.ACTION_EXTERNAL_APPLICATIONS_AVAILABLE.equals(intent.getAction())) {
skipPackages = intent.getStringArrayExtra(Intent.EXTRA_CHANGED_PACKAGE_LIST);
}
if (skipPackages != null && (skipPackages.length > 0)) {
//如果Manifest注册的广播接收器的包名和skip的一样,那就移除它们
for (String skipPackage : skipPackages) {
if (skipPackage != null) {
int NT = receivers.size();
for (int it=0; it<NT; it++) {
ResolveInfo curt = (ResolveInfo)receivers.get(it);
if (curt.activityInfo.packageName.equals(skipPackage)) {
receivers.remove(it);
it--;
NT--;
}
}
}
}
}
int NT = receivers != null ? receivers.size() : 0;
int it = 0;
ResolveInfo curt = null;
BroadcastFilter curr = null;
while (it < NT && ir < NR) {
if (curt == null) {
curt = (ResolveInfo)receivers.get(it);
}
if (curr == null) {
curr = registeredReceivers.get(ir);
}
if (curr.getPriority() >= curt.priority) {
//如果动态注册的广播优先级比静态注册的等级高,就把它添加到静态注册的前面。
receivers.add(it, curr);
ir++;
curr = null;
it++;
NT++;
} else {
// 如果动态注册的广播优先级没有静态注册的等级高,那就移动静态注册的游标,下一轮在执行相关的判断。
it++;
curt = null;
}
}
}
while (ir < NR) { //如果registeredReceivers中的元素没有全部放到receivers里面,就一个一个的遍历并放进去。
if (receivers == null) {
receivers = new ArrayList();
}
receivers.add(registeredReceivers.get(ir));
ir++;
}
|
以上的代码所做的事情就是首先移除静态注册的广播当中需要忽略的广播接收器,随后将静态注册和动态注册的广播接收器,按照优先级合并到同一个列表当中,当然如果动态注册的前面已经入队过了,这里实际上是不会在合并的。关于合并的代码,就是经典的两列表合并的算法,具体请看代码和注释。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
if ((receivers != null && receivers.size() > 0)
|| resultTo != null) {
BroadcastQueue queue = broadcastQueueForIntent(intent);
BroadcastRecord r = new BroadcastRecord(queue, intent, callerApp, callerPackage,
callerFeatureId, callingPid, callingUid, callerInstantApp, resolvedType,
requiredPermissions, excludedPermissions, excludedPackages, appOp, brOptions,
receivers, resultTo, resultCode, resultData, resultExtras,
ordered, sticky, false, userId, allowBackgroundActivityStarts,
backgroundActivityStartsToken, timeoutExempt);
final BroadcastRecord oldRecord =
replacePending ? queue.replaceOrderedBroadcastLocked(r) : null;
if (oldRecord != null) {
if (oldRecord.resultTo != null) {
final BroadcastQueue oldQueue = broadcastQueueForIntent(oldRecord.intent);
try {
oldRecord.mIsReceiverAppRunning = true;
oldQueue.performReceiveLocked(oldRecord.callerApp, oldRecord.resultTo,
oldRecord.intent,
Activity.RESULT_CANCELED, null, null,
false, false, oldRecord.userId, oldRecord.callingUid, callingUid,
SystemClock.uptimeMillis() - oldRecord.enqueueTime, 0);
} catch (RemoteException e) {
}
}
} else {
queue.enqueueOrderedBroadcastLocked(r);
queue.scheduleBroadcastsLocked();
}
}else {
//对于无人关心的广播,也做一下记录
if (intent.getComponent() == null && intent.getPackage() == null
&& (intent.getFlags()&Intent.FLAG_RECEIVER_REGISTERED_ONLY) == 0) {
addBroadcastStatLocked(intent.getAction(), callerPackage, 0, 0, 0);
}
}
|
以上的代码,跟前面入队的代码也差不多,不过这里如果采用的方法是enqueueOrderedBroadcastLocked,并且多了关于已经发送的广播的替换的逻辑,这里我们先不关注。如果receivers为空,并且符合条件的隐式广播,系统也会对其进行记录,具体,我们这里也不进行分析了。
BroadcastQueue 入队
我们知道前面入队的时候有两个方法,分别是enqueueParallelBroadcastLocked和enqueueOrderedBroadcastLocked,我们先来分析前者。
1
2
3
4
5
6
7
|
public void enqueueParallelBroadcastLocked(BroadcastRecord r) {
r.enqueueClockTime = System.currentTimeMillis();
r.enqueueTime = SystemClock.uptimeMillis();
r.enqueueRealTime = SystemClock.elapsedRealtime();
mParallelBroadcasts.add(r);
enqueueBroadcastHelper(r);
}
|
这里就是将BroadcastRecord放到mParallelBroadcasts列表中,随后执行enqueueBroadcastHelper,我们先看继续看一下enqueueOrderedBroadcastLocked方法。
1
2
3
4
5
6
7
|
public void enqueueOrderedBroadcastLocked(BroadcastRecord r) {
r.enqueueClockTime = System.currentTimeMillis();
r.enqueueTime = SystemClock.uptimeMillis();
r.enqueueRealTime = SystemClock.elapsedRealtime();
mDispatcher.enqueueOrderedBroadcastLocked(r);
enqueueBroadcastHelper(r);
}
|
这里跟上面很类似,差别是这里把BroadcastRecord入队了mDispatcher,对于普通广播,其内部是把这个记录放到了mOrderedBroadcasts列表。
而enqueueBroadcastHelper方法仅仅用于trace,我们这里不需要关注。
到了这里,我们把广播放到对应的列表了,但是广播还是没有分发出去。
AMS端广播的分发
以上是代码入了BroadcastQueu,接下来就可以看看队列中如何处理它了。首先需要注意一下,记录在入队的同时还调用了BroadcastQueue的scheduleBroadcastsLock方法,代码如下:
1
2
3
4
5
6
7
|
public void scheduleBroadcastsLocked() {
if (mBroadcastsScheduled) {
return;
}
mHandler.sendMessage(mHandler.obtainMessage(BROADCAST_INTENT_MSG, this));
mBroadcastsScheduled = true;
}
|
这里使用了Handler发送了一条BROADCAST_INTENT_MSG消息,我们可以去看一下BroadcastHandler的handleMessage方法。其中在处理这个消息的时候调用了processNextBroadcast方法,我们可以直接去看其实现:
1
2
3
4
5
|
private void processNextBroadcast(boolean fromMsg) {
synchronized (mService) {
processNextBroadcastLocked(fromMsg, false);
}
}
|
这里开启了同步块调用了processNextBroadcastLocked方法,这个方法依然很长,其中涉及到广播的权限判断,对于静态注册的广播,可能还涉及到对应进程的启动等。
动态广播的分发
动态注册的无序广播相对比较简单,这里我们仅仅看一下其中无序广播的分发处理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
|
if (fromMsg) {
mBroadcastsScheduled = false; //通过handleMessage过来,把flag设置为false
}
while (mParallelBroadcasts.size() > 0) {
r = mParallelBroadcasts.remove(0);
r.dispatchTime = SystemClock.uptimeMillis();
r.dispatchRealTime = SystemClock.elapsedRealtime();
r.dispatchClockTime = System.currentTimeMillis();
r.mIsReceiverAppRunning = true;
final int N = r.receivers.size();
for (int i=0; i<N; i++) {
Object target = r.receivers.get(i);
deliverToRegisteredReceiverLocked(r,
(BroadcastFilter) target, false, i); //分发
}
addBroadcastToHistoryLocked(r); //把广播添加的历史记录中
}
这里就是遍历`ParallelBroadcasts`中的每一条`BroadcastRecord`,其中会再分别遍历每一个`BroadcastFilter`,调用`deliverToRegisteredReceiverLocked`来分发广播。
```java
private void deliverToRegisteredReceiverLocked(BroadcastRecord r,
BroadcastFilter filter, boolean ordered, int index) {
boolean skip = false;
...
if (filter.requiredPermission != null) {
int perm = mService.checkComponentPermission(filter.requiredPermission,
r.callingPid, r.callingUid, -1, true);
if (perm != PackageManager.PERMISSION_GRANTED) {
skip = true;
} else {
final int opCode = AppOpsManager.permissionToOpCode(filter.requiredPermission);
if (opCode != AppOpsManager.OP_NONE
&& mService.getAppOpsManager().noteOpNoThrow(opCode, r.callingUid,
r.callerPackage, r.callerFeatureId, "Broadcast sent to protected receiver")
!= AppOpsManager.MODE_ALLOWED) {
skip = true;
}
}
}
...
if (skip) {
r.delivery[index] = BroadcastRecord.DELIVERY_SKIPPED;
return;
}
r.delivery[index] = BroadcastRecord.DELIVERY_DELIVERED;
...
try {
if (filter.receiverList.app != null && filter.receiverList.app.isInFullBackup()) {
if (ordered) {
skipReceiverLocked(r);
}
} else {
r.receiverTime = SystemClock.uptimeMillis();
maybeAddAllowBackgroundActivityStartsToken(filter.receiverList.app, r);
maybeScheduleTempAllowlistLocked(filter.owningUid, r, r.options);
maybeReportBroadcastDispatchedEventLocked(r, filter.owningUid);
performReceiveLocked(filter.receiverList.app, filter.receiverList.receiver,
new Intent(r.intent), r.resultCode, r.resultData,
r.resultExtras, r.ordered, r.initialSticky, r.userId,
filter.receiverList.uid, r.callingUid,
r.dispatchTime - r.enqueueTime,
r.receiverTime - r.dispatchTime);
if (filter.receiverList.app != null
&& r.allowBackgroundActivityStarts && !r.ordered) {
postActivityStartTokenRemoval(filter.receiverList.app, r);
}
}
if (ordered) {
r.state = BroadcastRecord.CALL_DONE_RECEIVE;
}
} catch (RemoteException e) {
...
if (ordered) {
r.receiver = null;
r.curFilter = null;
filter.receiverList.curBroadcast = null;
}
}
}
|
在这个方法中有大段的代码是判断是否需要跳过当前这个广播,我这里仅仅保留了几句权限检查的代码。对于跳过的记录会将其BroadcastRecord的delivery[index]值设置为DELIVERY_SKIPPED, 而成功分发的会设置为DELIVERY_DELIVERED。对于有序广播的分发我们这里也不予分析,直接看无序广播的分发,在分发之前会尝试给对应的接收进程添加后台启动Activity的权限,这个会在分发完成之后恢复原状,调用的是maybeAddAllowBackgroundActivityStartsToken,就不具体分析了。
之后会调用performReceiveLocked去进行真正的分发,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
void performReceiveLocked(ProcessRecord app, IIntentReceiver receiver,
Intent intent, int resultCode, String data, Bundle extras,
boolean ordered, boolean sticky, int sendingUser,
int receiverUid, int callingUid, long dispatchDelay,
long receiveDelay) throws RemoteException {
if (app != null) {
final IApplicationThread thread = app.getThread();
if (thread != null) {
try {
thread.scheduleRegisteredReceiver(receiver, intent, resultCode,
data, extras, ordered, sticky, sendingUser,
app.mState.getReportedProcState());
} catch (RemoteException ex) {
...
throw ex;
}
} else {
...
throw new RemoteException("app.thread must not be null");
}
} else {
receiver.performReceive(intent, resultCode, data, extras, ordered,
sticky, sendingUser);
}
...
}
|
在执行分发的代码中,如果我们的ProcessRecord不为空,并且ApplicationThread也存在的情况下,会调用它的scheduleRegisterReceiver方法。如果进程记录为空,则会直接使用IIntentReceiver的performReceiver方法。我们在App中动态注册的情况,ProcessRecord一定是不为空的,我们也以这种情况继续向下分析。
动态注册广播分发App进程逻辑
1
2
3
4
5
6
7
|
public void scheduleRegisteredReceiver(IIntentReceiver receiver, Intent intent,
int resultCode, String dataStr, Bundle extras, boolean ordered,
boolean sticky, int sendingUser, int processState) throws RemoteException {
updateProcessState(processState, false);
receiver.performReceive(intent, resultCode, dataStr, extras, ordered,
sticky, sendingUser);
}
|
在应用进程中,首先也只是根据AMS传过来的processState更新一下进程的状态,随后还是调用了IIntentReceiver的performReceive方法,performReceive在LoadedApk当中,为内部类InnerReceiver的方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
public void performReceive(Intent intent, int resultCode, String data,
Bundle extras, boolean ordered, boolean sticky, int sendingUser) {
final LoadedApk.ReceiverDispatcher rd;
if (intent == null) {
rd = null;
} else {
rd = mDispatcher.get(); //获取ReceiverDispatcher
}
if (rd != null) {
rd.performReceive(intent, resultCode, data, extras,
ordered, sticky, sendingUser);
} else {
IActivityManager mgr = ActivityManager.getService();
try {
if (extras != null) {
extras.setAllowFds(false);
}
mgr.finishReceiver(this, resultCode, data, extras, false, intent.getFlags());
} catch (RemoteException e) {
throw e.rethrowFromSystemServer();
}
}
}
|
在应用进程中,首先会获取ReceiverDisptcher,这个一般不会为空。但是系统代码比较严谨,也考虑了,不存在的情况会调用AMS的finishReceiver完成整个流程。
对于存在的情况,会调用ReceiverDispatcher的performReceive方法继续分发。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public void performReceive(Intent intent, int resultCode, String data,
Bundle extras, boolean ordered, boolean sticky, int sendingUser) {
final Args args = new Args(intent, resultCode, data, extras, ordered,
sticky, sendingUser);
..
if (intent == null || !mActivityThread.post(args.getRunnable())) {
if (mRegistered && ordered) {
IActivityManager mgr = ActivityManager.getService();
..
args.sendFinished(mgr);
}
}
}
|
这里的代码有点绕,不过也还比较清晰,首先是创建了一个Args对象,之后根据java的语法,如果intent不为空的时候会执行如下代码:
1
|
mActivityThread.post(args.getRunnable())
|
当这个执行失败的时候,才会看情况执行8行到第10行的代码。而这个Runnable就是应用端真正分发的逻辑,其代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
public final Runnable getRunnable() {
return () -> {
final BroadcastReceiver receiver = mReceiver;
final boolean ordered = mOrdered;
final IActivityManager mgr = ActivityManager.getService();
final Intent intent = mCurIntent;
mCurIntent = null;
mDispatched = true;
mRunCalled = true;
if (receiver == null || intent == null || mForgotten) {
...
return;
}
try {
ClassLoader cl = mReceiver.getClass().getClassLoader();
intent.setExtrasClassLoader(cl);
intent.prepareToEnterProcess(ActivityThread.isProtectedBroadcast(intent),
mContext.getAttributionSource());
setExtrasClassLoader(cl);
receiver.setPendingResult(this);
receiver.onReceive(mContext, intent);
} catch (Exception e) {
if (mRegistered && ordered) {
sendFinished(mgr);
}
if (mInstrumentation == null ||
!mInstrumentation.onException(mReceiver, e)) {
throw new RuntimeException(
"Error receiving broadcast " + intent
+ " in " + mReceiver, e);
}
}
if (receiver.getPendingResult() != null) {
finish();
}
};
}
|
这里的receiver就是我们注册时候的那个BroadcastReceiver,这里将当前的Args对象作为它的PendingResult,在这里调用了它的onReceive方法 ,最后看pendingResult是否为空,不为空则调用PendingResult的finish()方法。当我们在onReceive中编写代码的时候,如果调用了goAsync的话,那这里的PendingResult就会为空。
另外就是我们这个Runnable是使用的mActivityThread的post方法投递出去的,它是一个Handler对象,它是在注册广播接收器的时候指定的,默认是应用的主线程Handler,也就是说广播的执行会在主线程。
但是即使是我们使用goAsync的话,处理完成之后也是需要手动调用finish的,我们后面在来看相关的逻辑。
静态广播的发送
在前面分析的BroadcastQueue的processNextBroadcastLocked方法中,我们只分析了动态广播的发送,这里再看一下静态广播的发送,首先仍然是看processNextBroadcastLocked中的相关源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
BroadcastRecord r;
do {
r = mDispatcher.getNextBroadcastLocked(now);
if (r == null) {
...
return;
}
...
} while(r === null);
...
if (app != null && app.getThread() != null && !app.isKilled()) {
try {
app.addPackage(info.activityInfo.packageName,
info.activityInfo.applicationInfo.longVersionCode, mService.mProcessStats);
maybeAddAllowBackgroundActivityStartsToken(app, r);
r.mIsReceiverAppRunning = true;
processCurBroadcastLocked(r, app);
return;
} catch(RemoteException e) {
...
}
}
...
|
在第3行,会从mDispatcher中拿BroadcastRecord的记录,我们之前在AMS端入队的代码,对于静态注册的广播和有序广播都是放在mDispatcher当中的,这里拿到动态注册的有序广播也会从这里拿,它的后续逻辑跟前面分析的是一样的,这里不再看了。对于静态注册的广播,在调用后续的方法之前,需要先获取对应进程的ProcessRecord,和ApplicationThread,并且进行广播权限的检查,进程是否存活检查这些在我们11行的位置,都省略不看了。如果App进程存活则会走到我们12行的部分,否则会去创建对应的进程,创建完进程会再去分发广播。
动态注册的广播,会传一个IIntentReceiver的Binder到AMS,而静态注册的广播,我们跟着第18行代码processCurBroadcastLocked方法进去一览究竟:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
private final void processCurBroadcastLocked(BroadcastRecord r,
ProcessRecord app) throws RemoteException {
final IApplicationThread thread = app.getThread();
...
r.receiver = thread.asBinder();
r.curApp = app;
final ProcessReceiverRecord prr = app.mReceivers;
prr.addCurReceiver(r);
app.mState.forceProcessStateUpTo(ActivityManager.PROCESS_STATE_RECEIVER);
...
r.intent.setComponent(r.curComponent);
boolean started = false;
try {
mService.notifyPackageUse(r.intent.getComponent().getPackageName(),
PackageManager.NOTIFY_PACKAGE_USE_BROADCAST_RECEIVER);
thread.scheduleReceiver(new Intent(r.intent), r.curReceiver,
mService.compatibilityInfoForPackage(r.curReceiver.applicationInfo),
r.resultCode, r.resultData, r.resultExtras, r.ordered, r.userId,
app.mState.getReportedProcState());
started = true;
} finally {
if (!started) {
r.receiver = null;
r.curApp = null;
prr.removeCurReceiver(r);
}
}
}
|
在这个方法中,把App的ProcessRecord放到了BroadcastRecord当中,并且把ApplicationThread设置为receiver,最后是调用了ApplicationThread的scheduleReceiver,从而通过binder调用App进程。
静态注册广播分发App进程逻辑
通过Binder调用,在App的ApplicationThread代码中,调用的是如下方法:
1
2
3
4
5
6
7
8
9
10
|
public final void scheduleReceiver(Intent intent, ActivityInfo info,
CompatibilityInfo compatInfo, int resultCode, String data, Bundle extras,
boolean sync, int sendingUser, int processState) {
updateProcessState(processState, false);
ReceiverData r = new ReceiverData(intent, resultCode, data, extras,
sync, false, mAppThread.asBinder(), sendingUser);
r.info = info;
r.compatInfo = compatInfo;
sendMessage(H.RECEIVER, r);
}
|
这里是创建了一个ReceiverData把AMS传过来数据包裹其中,并且通过消息发出去,之后会调用ActivityThread的handleReceiver方法, 代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
private void handleReceiver(ReceiverData data) {
String component = data.intent.getComponent().getClassName();
LoadedApk packageInfo = getPackageInfoNoCheck(
data.info.applicationInfo, data.compatInfo);
IActivityManager mgr = ActivityManager.getService();
Application app;
BroadcastReceiver receiver;
ContextImpl context;
try {
app = packageInfo.makeApplicationInner(false, mInstrumentation);
context = (ContextImpl) app.getBaseContext();
if (data.info.splitName != null) {
context = (ContextImpl) context.createContextForSplit(data.info.splitName);
}
if (data.info.attributionTags != null && data.info.attributionTags.length > 0) {
final String attributionTag = data.info.attributionTags[0];
context = (ContextImpl) context.createAttributionContext(attributionTag);
}
java.lang.ClassLoader cl = context.getClassLoader();
data.intent.setExtrasClassLoader(cl);
data.intent.prepareToEnterProcess(
isProtectedComponent(data.info) || isProtectedBroadcast(data.intent),
context.getAttributionSource());
data.setExtrasClassLoader(cl);
receiver = packageInfo.getAppFactory()
.instantiateReceiver(cl, data.info.name, data.intent);
} catch (Exception e) {
data.sendFinished(mgr);
...
}
try {
sCurrentBroadcastIntent.set(data.intent);
receiver.setPendingResult(data);
receiver.onReceive(context.getReceiverRestrictedContext(),
data.intent);
} catch (Exception e) {
data.sendFinished(mgr);
} finally {
sCurrentBroadcastIntent.set(null);
}
if (receiver.getPendingResult() != null) {
data.finish();
}
}
|
这个代码中主要有两个try-catch的代码块,分别是两个主要的功能区。因为静态注册的广播,我们的广播接收器是没有构建的,AMS传过来的只是广播的类名,因此,第一块代码的功能就是创建广播接收器对象。第二块代码则是去调用广播接收器的onReceive方法,从而传递广播。另外这里会调用PendingResult的finish去执行广播处理完成之后的逻辑,以及告知AMS,不过这里的PendingResult就是前面创建的ReceiverData。
完成广播的发送
在分析前面的动态注册广播分发和静态注册广播分发的时候,最终在App进程它们都有一个Data,静态为ReceiverData, 动态为Args,他们都继承了PendingResult,最终都会调用PendingResult的finish方法来完成后面的收尾工作,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
public final void finish() {
if (mType == TYPE_COMPONENT) {
final IActivityManager mgr = ActivityManager.getService();
if (QueuedWork.hasPendingWork()) {
QueuedWork.queue(new Runnable() {
@Override public void run() {
sendFinished(mgr);
}
}, false);
} else {
sendFinished(mgr);
}
} else if (mOrderedHint && mType != TYPE_UNREGISTERED) {
final IActivityManager mgr = ActivityManager.getService();
sendFinished(mgr);
}
}
|
这里的QueuedWork主要用于运行SharedPreferences写入数据到磁盘,当然这个如果其中有未运行的task则会添加一个Task到其中来运行sendFinished,这样做的目的是为了保证如果当前除了广播接收器没有别的界面或者Service运行的时候,AMS不会杀掉当前的进程。否则会直接运行sendFinished方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
public void sendFinished(IActivityManager am) {
synchronized (this) {
if (mFinished) {
throw new IllegalStateException("Broadcast already finished");
}
mFinished = true;
try {
if (mResultExtras != null) {
mResultExtras.setAllowFds(false);
}
if (mOrderedHint) {
am.finishReceiver(mToken, mResultCode, mResultData, mResultExtras,
mAbortBroadcast, mFlags);
} else {
am.finishReceiver(mToken, 0, null, null, false, mFlags);
}
} catch (RemoteException ex) {
}
}
}
|
这里就是调用AMS的finishReceiver方法,来告诉AMS广播接收的处理已经执行完了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
public void finishReceiver(IBinder who, int resultCode, String resultData,
Bundle resultExtras, boolean resultAbort, int flags) {
if (resultExtras != null && resultExtras.hasFileDescriptors()) {
throw new IllegalArgumentException("File descriptors passed in Bundle");
}
final long origId = Binder.clearCallingIdentity();
try {
boolean doNext = false;
BroadcastRecord r;
BroadcastQueue queue;
synchronized(this) {
if (isOnFgOffloadQueue(flags)) {
queue = mFgOffloadBroadcastQueue;
} else if (isOnBgOffloadQueue(flags)) {
queue = mBgOffloadBroadcastQueue;
} else {
queue = (flags & Intent.FLAG_RECEIVER_FOREGROUND) != 0
? mFgBroadcastQueue : mBgBroadcastQueue;
}
r = queue.getMatchingOrderedReceiver(who);
if (r != null) {
doNext = r.queue.finishReceiverLocked(r, resultCode,
resultData, resultExtras, resultAbort, true);
}
if (doNext) {
}
trimApplicationsLocked(false, OomAdjuster.OOM_ADJ_REASON_FINISH_RECEIVER);
}
} finally {
Binder.restoreCallingIdentity(origId);
}
}
|
相关的逻辑从13行开始,首先仍然是根据广播的flag找到之前的BroadcastQueue,之后根据IBinder找到发送的这一条BroadcastRecord,调用Queue的finishReceiverLocked方法。根据它的返回值,再去处理队列中的下一个广播记录。最后的trimApplicationsLocked里面会视情况来决定是否停止App进程,我们这里就不进行分析了。
processNextBroadcastLocaked前面已经分析过了,这里只需要来看finishReceiverLocked方法,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
public boolean finishReceiverLocked(BroadcastRecord r, int resultCode,
String resultData, Bundle resultExtras, boolean resultAbort, boolean waitForServices) {
final int state = r.state;
final ActivityInfo receiver = r.curReceiver;
final long finishTime = SystemClock.uptimeMillis();
final long elapsed = finishTime - r.receiverTime;
r.state = BroadcastRecord.IDLE;
final int curIndex = r.nextReceiver - 1;
if (curIndex >= 0 && curIndex < r.receivers.size() && r.curApp != null) {
final Object curReceiver = r.receivers.get(curIndex);
}
...
r.receiver = null;
r.intent.setComponent(null);
if (r.curApp != null && r.curApp.mReceivers.hasCurReceiver(r)) {
r.curApp.mReceivers.removeCurReceiver(r);
mService.enqueueOomAdjTargetLocked(r.curApp);
}
if (r.curFilter != null) {
r.curFilter.receiverList.curBroadcast = null;
}
r.curFilter = null;
r.curReceiver = null;
r.curApp = null;
mPendingBroadcast = null;
r.resultCode = resultCode;
r.resultData = resultData;
r.resultExtras = resultExtras;
....
r.curComponent = null;
return state == BroadcastRecord.APP_RECEIVE
|| state == BroadcastRecord.CALL_DONE_RECEIVE;
}
|
在这里,我们最关注的代码就是17行开是的代码,从mReceivers列表中移除BroadcastRecord,并且把ReceiverList的curBroadcast设置为空,并且其他几个参数也设置为空,这样才算完成了广播的分发和处理。
总结
以上就是广播接收器的注册,以及动态、静态广播分发的分析了。关于取消注册是跟注册相关的过程,理解了注册的逻辑,取消注册也可以很快的搞清楚。关于sticky的广播,限于篇幅先不分析了。而有序广播,它在AMS端其实和静态注册的广播是差不多,不过它在调用App进程的时候是有差别的。另外关于权限相关的逻辑,以后在权限代码的分析中可以再进行关注。














 学习笔记 技术 程序员 程序设计 编程 计算机 软件工程 面试")
{kind=link}