原标题是“独立博客创作者的暂时解药”,讨论“独立博客”是个浩大的工程,它是个标准无法统一的、令人不悦的、观点纠缠的话题。它的定义可以先留在这里,就单单从博客创作者来讨论这件事,在今天的话题里,或许又能在过程中找到“独立博客创作者”的定义。
我想从另一个视角来聊聊火了一阵的信息流整合订阅平台Follow。
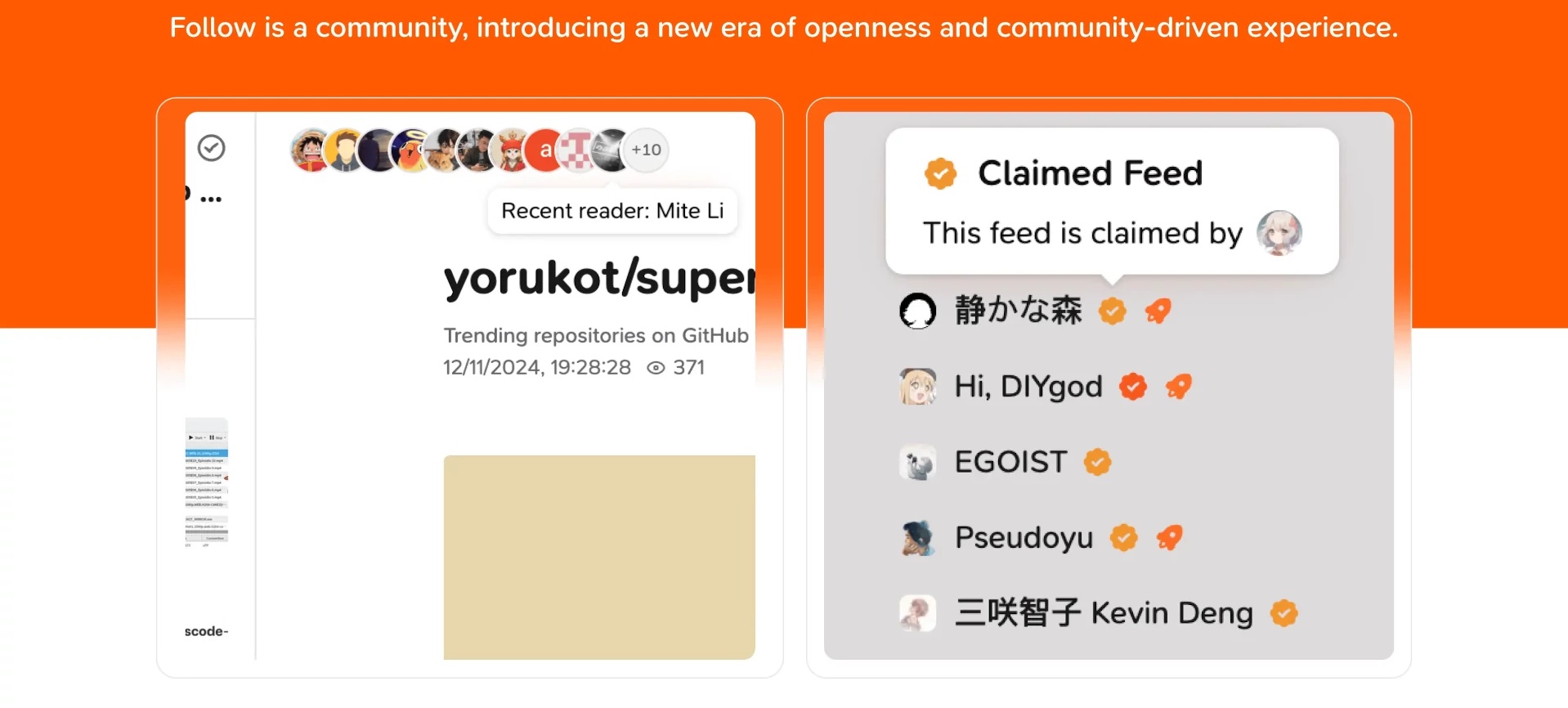
Follow是治疗信息焦虑的良药吗?
每个人都有自己使用Follow的方法,在这里就不赘述。我跟@杜郎俊赏一样,一开始是希望利用这个软件整合不同平台的信息源,从而解决“红点”带来的信息焦虑感。但事实上,信息订阅软件并不会因为订阅的方式和流程变化,从而缩减或取代人在阅读时所需要付出的时间和思考。
或许一直害怕被主流社会淘汰,这只是下意识的抵抗。但最终不得不承认,这个时代的信息过载越来越严重,即便我主动追寻都赶不上最新业态了,我的精力也跟不上。接受这种必然之后,心态平和了一些,但留下信息焦虑的病根治不好了。
——《Follow 治不好我的信息焦虑》 |杜郎俊赏
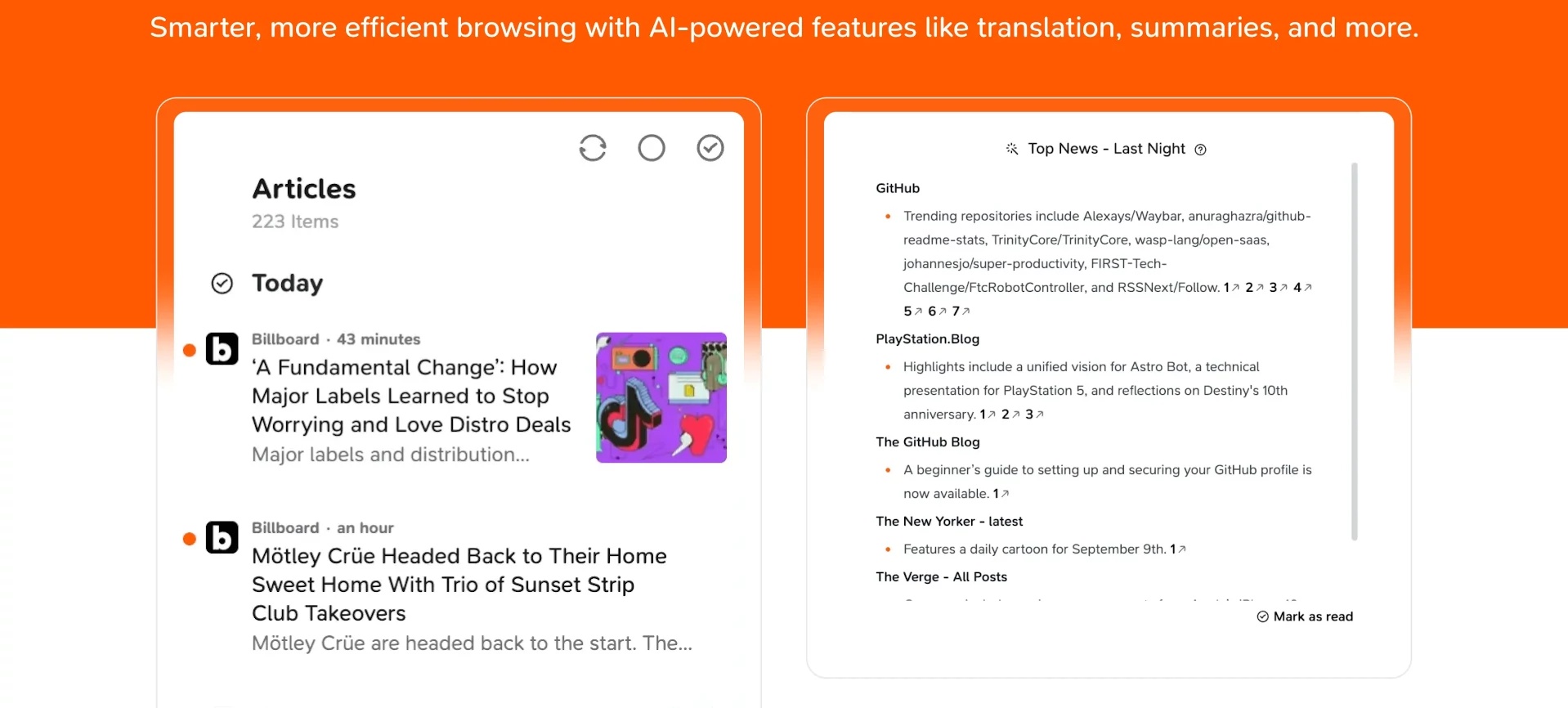
目前,Follow已经接入了简单的AI功能,无论多长的文章,都可以提炼成简单易读的一段话。我不知道有多少人是依赖这个功能的,用这种方式最快地读“完”他人的文章。我个人对AI的依赖程度不大,AI总结或许是一个不错的“导读”,但阅读全文我是为了理解创作者的内在逻辑和观点的推演过程。
我相信未来AI接入会更加的彻底和丝滑,甚至可以通过“重构”的方式将创作者的内容完全拆解,压缩内容、精简逻辑、拆除个人情感。那时候,会不会完全变成一个充满恐怖谷效应的AI加工品?
AI是否是创作者的毒药?
这是一节题外话,接续上面的话题。我相信未来AI的功能会更加强大,并形成“创作者-AI-读者”的关系。AI或许可以为读者提供越来越多的便利,但如果读者完全依赖AI的功能时,那还需要“创作者”吗?
前段时间,大量的创作者从X平台逃离。是因为新版X服务条款提到,平台打算把用户的文字、图像、视频用来训练AI,而且会出售给第三方合作伙伴。其中并未提到退出机制,换句话说,在11月条款正式生效后,用户在X里发布的内容都将成为训练AI的素材。
如果AI将创作者的内容作为“血液”不停榨取,这或许是对创作者的一种不尊重。特别是当读者完全依赖AI,就算创作者统统离开,AI因为收集了足够的作品,是否也可以创造出读者已经习惯阅读的作品?
单从「写作场景」来看,这种“普遍认知”会持续分化“能写作的人”和“完全依赖 AI 的人”。这种分化不仅关乎写作技能,更关乎思考模式、思维能力、逻辑能力、认知能力、组织结构能力 、批判思维能力等等,甚至包括底层/本质的学习力和竞争力。
——废话集 ℠
中文博客圈的无可救药
我在《无聊的中文博客圈》 提到一个点——博客因为严重的滞后性,从创作发布、到被人看见、再到引发共鸣互动,因为观点的互动,本身会受限于“沉默螺旋”。 最近我找到一个非常精准的名词来形容中文博客圈——递归岛屿 。
图片由ChatGPT生成 中文博客圈首先就是一个巨大的孤岛,过时的载体、技术开发门槛及成本过高、备案后的“自我审查机制”、非即时性地信息呈现、普通阅读者获取路径复杂等;孤岛的内部是另一个海域里再分布着的不同孤岛,这些孤岛正是我们这些所谓的“独立博客”。有把域名当做宝的、有三天两头就捣鼓模板的、有不停创作孤芳自赏的、也有很长时间失联的……大部分时间,都是孤岛之间的自娱自乐,久而久之的抱团,互动的人群、模式、甚至是评论内容都变得公式化。
递归岛屿的内部孤岛之间翻起再大的浪花,也只能在这个孤岛内部的海域里无人问津。而中文博客圈孤岛以外的海域发生着朝代更迭的战争,个体的独立博客又还在自娱自乐。但是战火迟早会延烧到孤岛,但那个时候为时已晚——博客时代最终的结束,一定是当递归岛屿内部的所有所谓创作者都在玩一样的自问自答游戏、发出一样的声音、群体吞并群体、乌合之众猎巫独立个体的那一天。
这样看起来,中文博客圈真的无可救药了。
概念式春药只管勃起不管活好
最近有一个特别的现象。当我的博客开始在Follow上作为一个信息源出现后,它在短时间内得到的关注度、阅读总量已经接近博客的三年运营。在递归岛屿的中文博客圈,独立博客很难做到真正的“被看见”或者说是“引发共鸣地被看见”。
因为Follow的曝光,越来越多人关注到内容本身,甚至会有人透过文章预留的Telegram参与互动,或是跟我直接就文章的观点进行交流和讨论。Follow是通过RSS抓取博客的的文章发布,并不会就博客关于里的生平小作文、设计风格、创作概念进行抓取,独立博客的“内容”回归到了本位。
概念,是一个非常抽象、私人的存在。特别是当作品未完成、完成度有困难、无法坚持完成、甚至作品根本不存在时,概念就成了暂时的春药——不停地向人阐述自己将会创造多么牛逼的作品、能够给社会带来多大的启示、能够引发众人多深的思考——但是作品呢?“还没写出来呢,你先看看这个概念,看看这设计风格,多牛逼啊!”
没有“创作内容”,自然就不会被抓取,不被抓取就不会被看见,也不会点进原本的博客里看到那牛逼的“概念”。
Follow或许是博客创作者的暂时解药
既然Follow抓取的是博客的内容,且是按照时间线抓取的内容。博客内容发布即成,变成了期刊的概念,这是信息流遵循的规则。于是在这个规则之中,也能直观地看到博客本身的创作频率;回归内容后,读者可以免于博客设计元素的打扰,看到博客本身的创作质量。
我之所以提到了“暂时”这个词,也是保留了对AI的态度——如果真的形成了“创作者-AI-读者”的结构,创作者会不会因为AI的吸血而再一次出现孤岛化的情况。另外,我在《中文博客圈的“鸩酒”与止不了的“渴”》 里也提到,创作者对AI的依赖,也是一个不能忽视的问题。
Follow的用户群远超过原本中文博客圈的量级,确实可以让独立博客暂时脱离递归岛屿的困境,但Follow能够走多远,会不会也因为无法真正解决信息焦虑,很快沦为“概念”。另外,Follow依赖的并不是社交属性,所以无法让读者和创作者形成互动。互动缺失本身也是孤岛化的构成要件之一,但如果通过订阅可以引发思考,进而引导至互动空间,这又是博客功能对Follow功能的弥补。
当然,也可以通过利用RSS只抓取摘要的方式,避免Follow可以显示全文,使得用户需要进入博客阅读完全文。但用户是否愿意跳出APP,特别是手机端的Follow上线后,这是需要另说的事情了。
但这一切都是“暂时”的,核心不是平台本身,而是创作者本身是否真的能够坚持创作、坚持高质量创作。当独立博客的内容被丢入全面的信息海洋时——那些自娱自乐的部分,就必然要接受更多受众的审视和裁判。
那独立博客到底是什么?
在中文博客圈的递归岛屿里,孤岛之间可以按照占领的时间、岛屿大小、抱团的程度来选出“最有话语权”的“主岛”。或许在孤岛内,还会有见面三分情、大佬要面子的规则。一旦信息完全公开至孤岛以外的平台,就必然要接受来自他人“价值标准”的认定。
问题就立马从“我为什么要创作博客”变成了“我为什么要订阅你的博客”。这和创作者的创作初衷并不矛盾,而是来自外界的价值认定我们既不能统一标准、也不能让别人闭嘴。除非我选择关闭博客的RSS抓取、拒绝自己写给自己的作品被投放至公共领域。Follow的信息可没有“先来后到”一说,用户完全是根据自己的喜好订阅信息源,不是靠你我形成几个创作联盟就可以垄断,将他人拒之门外的。
举个话糙理不糙的例子。一百个人都在写日记,用户就算订阅了全部日记,也会挑选有趣的查看——对一些人而言,“性爱日记”当然要比那些“吃喝拉撒日记”更吸引人眼球。如何从这一百个人里脱颖而出,不仅仅是标题党这么简单,Follow回归“内容”,那内容就变成了当下的直接评判标准。
每个人对独立博客的定义不同,但“内容”又是大家无论如何都无法绕过的核心,否则大家只需要批量生产概念即可。这个话题可以留在以后细聊。如果你有任何想要分享的观点,欢迎透过莫比乌斯频道 或博客内联系方式进行互动。


{kind=link}